Chapter 4 Stratification and summary
One concise description of statistical methodology can be made in three words: stratify, summarize, compare. This chapter is about the first two of these. Later, we’ll tackle the third, but that will require some care and sophistication with the techniques of stratification and summarization.
Figure 4.1 is a picture of a cut through rock in Quebrada de las Conchas, Argentina. You have probably seen similar geological features when driving on a highway cutting through mountains or looking at canyon walls.
Figure 4.1: Rock strata – layers – distinguished by different colors and textures of material. Source: travelwayoflife, CC BY-SA 2.0

The word “stratum” is Latin for “layer.” The layers in Figure 4.1 are evident even to the untrained viewer, but it’s worth thinking about what it is about rock that makes a layer. If you know about geology, you may think about each layer being deposited at a specific geological time. More fundamentally, the rock in a layer has similar properties to other rock in that layer, but different from neighboring layers.
4.1 Statistical stratification
In statistics, stratification is the process of dividing the rows of a data frame into subgroups that have common properties. Deciding what properties to look at requires some creativity and insight from the data scientist, although often what to do is obvious.
To illustrate, consider measurements of people’s full expiratory lung volume collected as part of a study to understand the functional effects of smoking and exposure to second-hand smoke. The data shown in Table 4.1 and documented at (Kahn 2005), are available in the SDSdata::Expiration data frame. The unit of observation is a person. There are 654 rows and five variables: age, expiratory lung volume (in liters), height (in inches), sex, and whether or not the person smokes.
Table 4.1: Data on lung volume and other variables.
| age | volume | height | sex | smoke |
|---|---|---|---|---|
| 8 | 2.358 | 61.0 | female | non-smoker |
| 12 | 2.866 | 62.0 | female | non-smoker |
| 12 | 3.279 | 70.5 | male | non-smoker |
| 11 | 2.491 | 59.0 | female | non-smoker |
| 8 | 1.724 | 67.5 | female | non-smoker |
| 10 | 3.498 | 68.0 | male | smoker |
| … and so on for 654 rows altogether. |
Stratification follows the same logic as in statistical graphics. Pick a response variable. Since the interest was in understanding lung volume, we’ll use volume as the response variable. Then pick one or more explanatory variables. The explanatory variables are used to define the groups to be used in the stratification. For example, using sex as the explanatory variable will produce two groups, one of 336 females and one of 318 males. Using smoke as the explanatory variables divides the data frame into groups in a different way: 589 non-smokers and 65 smokers. Stratification can also be done using both sex and smoke as explanatory variables. This gives four groups: 310 female non-smokers, 279 male non-smokers, 26 female smokers, 39 male smokers. Similarly, age could be the explanatory variable used for stratification, perhaps by itself or perhaps along with either sex or smoke or both.
Building on the techniques in (ref:chapter-data_graphics), we can use statistical graphics to display the stratification. For instance, Figure 4.2 shows lung volume stratified by smoking status.
Figure 4.2: Lung volume stratified by smoking status.
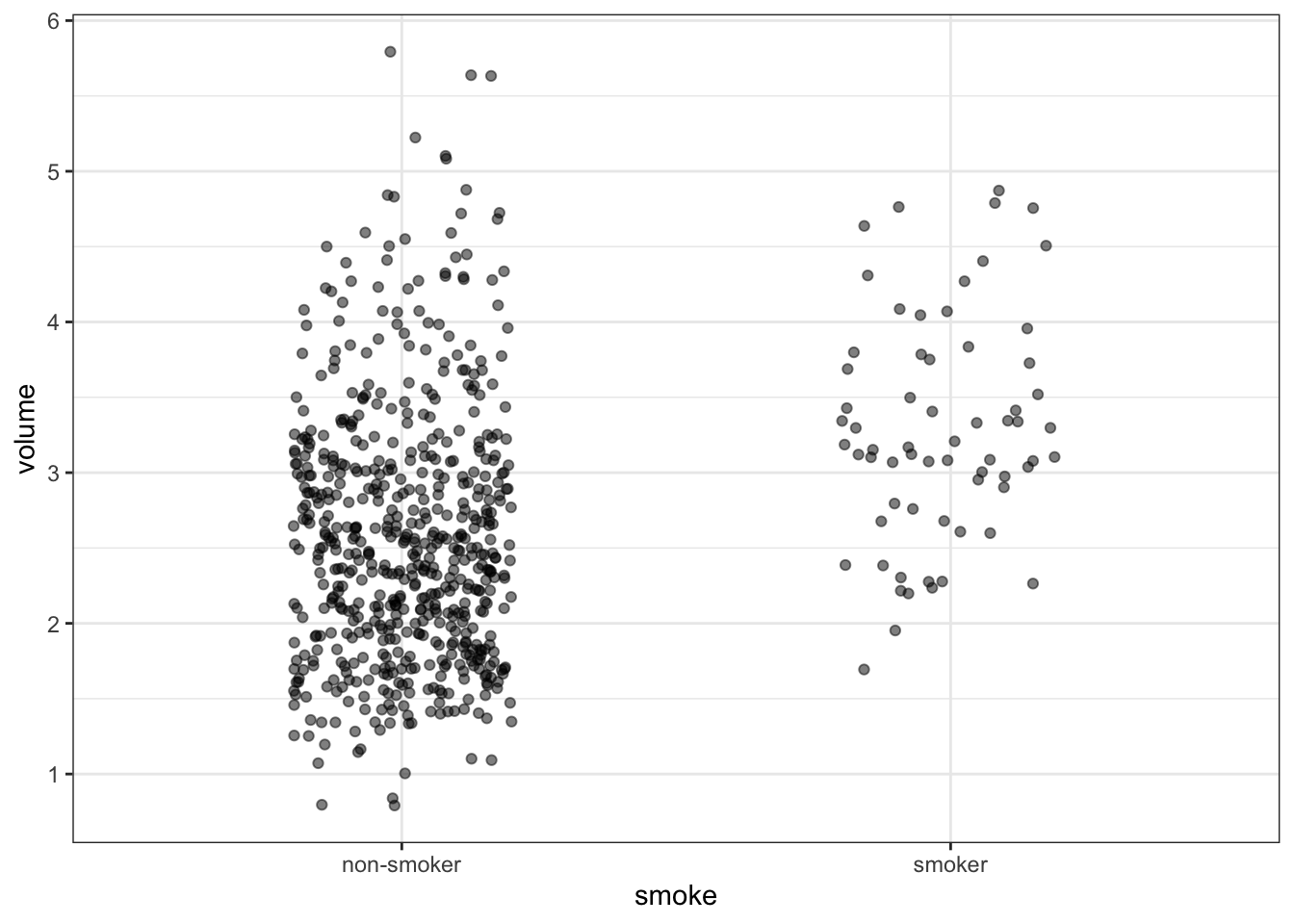
A few things are different between the patterns seen in geological strata and the statistical stratification of Figure 4.2. The geological strata are laid out under the influence of gravity, so they tend to be horizontal. In contrast, the statistical strata are displayed according to the conventions of statistical graphics, with the explanatory variable on the horizontal axis. Consequently, the statistical strata are displayed vertically: one band for non-smokers and one band for smokers.
Second, the rock strata are defined by their color, texture, composition, and so on. The material being stratified is rock. In statistical stratification, the material being stratified is the values of the response variable. The statistical strata are not defined by different values for the response. Instead, the strata are defined by having different values for the explanatory variables.
The statistical modeler is the one who defines the strata. Whether or not the material is different from one strata to another is not established merely by the modeler’s choice. That choice might produce strata that differ in lung volume or it might not. We would judge the strata as being materially different if the distribution of lung volume values is distinctly different from one stratum to the next. For many purposes, the goal of the modeler is to find explanatory variables that do create material differences in the strata and to understand and interpret why that is so.
It’s worth pointing out that the phrase “stratify lung volume by smoking status” is practically equivalent to “model lung volume as a function of smoking status” or “explain lung volume using smoking status.” The concept of modeling/stratification/explaining is so important in statistics that there are even more ways to state it, for example “conditioning lung volume on smoking status.” What’s special about “stratify” is that it refers to a particularly simple technique that amounts to dividing a data frame into discrete groups defined by categorical explanatory variable or variables, e.g. smokers and non-smokers, females and males. Later chapters will examine how to model/explain/condition using quantitative explanatory variables.
4.2 Statistical summary
Suppose you have a stratification that you want to investigate, for instance stratifying lung volume by smoking status. The next step is to summarize the response variable for each of the strata/groups. There are many types of summaries in common use.
The response variable in the example is lung volume, which is quantitative. There are two fundamentally different formats for summarizing a quantitative variable:
- A point summary reduces the values of the response variable to a single number.
- An interval summary in which two numbers are used to delimit a range.
Point summaries are attractive because they seem simple. For instance, for the non-smokers, a representative lung volume is 2.6 liters, while for the smokers a representative value is 3.3 liters. You can confirm this by looking at Figure 4.2.
I used the word “representative,” but haven’t yet said what “representative” means. I might equally have used the any of the words “typical,” “usual,” “quintessential,” “archetypal,” “prototypical,” or “model.” These concepts are all somewhat vague, and there is wiggle-room when picking a number that is representative of all the values in a stratum. For example, it would be reasonable to say that a representative lung volume for non-smokers is 2.5 or 2.7 liters. But it would be unreasonable to say that the representative value is 4 liters.
Rather than worry about giving a precise definition for “representative” or the analogous concepts, statisticians have settled on standard ways to construct a point summary. The two most common of these are the mean and the median. As you may well know, the mean is calculated by adding up the values and dividing by the number of values. There are 589 non-smokers, for instance. Adding up their lung volumes gives \(2.358 + 2.866 + 3.279 + \cdots = 1511.46\) liters, where the \(\cdots\) is a concise way of referring to the remaining 586 values, thus saving space, printer’s ink, and the reader’s attention. Taking the sum of all 589 people’s lung volumes and dividing by 589 produces the mean lung volume: \(1511.46 / 589 = 2.57\) liters.
The median is defined differently: it is a number which is less than or equal to half the lung-volume values and greater than or equal to the other half of the values. You could calculate it from Figure 4.2 by counting down 294 points from the top of the non-smoker stratum and taking the median as the value of the 295th point. This leaves another 294 values that are less than (or equal to) the value of the 295th point. For non-smokers, the median lung volume is 2.47 liters.
There is nothing magical about using the mean or the median. What’s important is that they are reasonably representative, can be easily and automatically calculated, help to dodge unnecessary and unproductive disputes about method and subjectivity, and (mostly) avoid the researcher’s choosing his or her own definition of “representative” to serve his or her own, narrow purposes.
The mean has both merits and demerits. It has nice, if somewhat obscure, mathematical properties. For instance, the mean of the sum of two variables is exactly the same as the sum of the means of the individual variables. On the other hand, the mean can be heavily influenced by extreme high or low values. For instance, it takes just one billionaire in a large room to make the mean income of the people in that room larger than anyone else’s actual income. Or, the extreme values might be due to error in measurement or recording. The median is minimally influenced by extreme values. The word robust is used to describe summaries that are hardly affected by outliers. The median is robust while the mean is not.
Representativeness is not always the goal in constructing a point summary. Often, the interest is in summarizing the position of high (or low) values. An obvious point summary to describe high values is the maximum: the single highest value. Similarly, the minimum is a point summary for the low values. Maximum and minimum values are problematic as statistical summaries because they are not at all robust as summaries. They are acutely sensitive to blunders: errors in measurement or recording. And, like the mean and median, there is nothing about the maximum or minimum to tell us whether many other points are nearby, or not.
Statisticians use quantiles to address both the problems of lack of robustness and to provide an indication of how the summary relates to the set of response variable values as a whole. You’ve already seen one example of a quantile: the median. The median is the 50% quantile, that is, the dividing line between the upper 50% of values and the lower 50%. The 25% quantile marks the division between the lower 25% and upper 75% of values of the response variable. Sometimes this is called the “first quartile,” because one-quarter of the values are below it. That’s potentially confusing because there is so little typographical difference between “quantile” and “quartile.”
The 75% quantile marks the division between the lower 75% and upper 25% of response variable values. Depending on your purpose, you might want to use some other quantile level. For instance, if your goal were to describe a low, but somewhat common, lung volume, you might choose the 5% quantile.
Still another kind of point summary involves setting a limit and calculating what fraction of the values are above that limit. For instance, high blood pressure is conventionally defined as a systolic pressure greater than 130 mmHg. To summarize the prevalence of high blood pressure, you could find the fraction of values larger than 130 mmHg.
4.3 Example: The fallacy of reification and the “average man.”
The confusion of an abstraction with concrete reality is called the fallacy of reification. When we calculate a mean, such as the mean lung volumes of a sample of people, we should not think that there is an ideal lung volume of which we are making multiple measurements with error. All there is are the various individual people and their lung volumes. The mean lung volume is merely a summary, not an ideal.
The history of the mean serves as a warning of how easy it is to fall into the fallacy of reification. Up through the 18th century, the best of a set of astronomical measurements of an event from different observatories was considered to be the single measurement from the most prestigious observatory. Then, in comparing the distribution of measurements it was noticed that they often fall into a characteristic pattern which came to be called the law of error. The law of error provided a theory by which a hypothetical value of zero error could be calculated from the available data. This hypothetical value is the mean of the measurements. The mean came to be thought of as the actual value, observations of which included some error due to atmospheric conditions, instrument calibration, lack of perfect alignment between clocks, etc.
In the late 1820s, Adolphe Quetelet, a Belgian astronomer, was sent to Paris for the purpose of learning how to set up a national observatory. A few years earlier, the French government, as part of a national re-organization, had started to tabulate records of crimes and convictions. Quetelet found out about this statistical innovation and examined the tabulations. He discovered something that we all take for granted today but which was unknown at the time: that there are rates of crime that differ from one sort of crime to another but which are relatively consistent from one region to another. Quetelet speculated that there are laws that govern social phenomena, just as there are laws of physics. He coined the term “social physics,” a precursor to what we now call sociology.
In astronomy, it was accepted that the mean of several measurements gave a better indication of the workings of physical law than any individual measurement. Quetelet extended this logic to social physics, looking at means of many different kinds of measurements of human society and physiology. He took the mean to be the ideal value from which individual measurements differed because of error. The word “error” was used consciously. Differences between people were regarded not as diversity but as erroneous deviations from the ideal. This takes an abstract mathematical idea – the mean – and treats it as a real physical quantity resulting from the action of physical law.
Quetelet invented l’homme moyen, the “average man” – what people would be if error could be reduced to zero. Today, we regard the varying individual characteristics of people not as the result of error, but the interplay of many diverse factors.
Quetelet’s work predated Darwin, and Quetelet had no notion of what we now understand as the encoding and function of genes. A lot of current research involves the human genome, the full genetic sequence that define us. Fortunately, it’s understood that there is not a single, human genetic sequence that defines the “ideal” human. It’s not tenable to believe that individuals are errors or mutants from the ideal. Instead, the human genome encompasses a broad range of variations, each equally human, that are similar in enough ways to create the organisms we recognize as human beings.
4.4 Interval summaries
When a point summary serves your purpose, use it. But many purposes are better served by summaries in the form of a range or interval. An interval on the number line is specified by its two endpoints and interval summaries are often expressed as two numbers: the lower end of the interval and the upper end.
There are different kinds of intervals used in statistics: summary intervals, prediction intervals, confidence intervals, credible intervals. A summary interval is used to describe the range of response variable values in a stratum. Common sense suggests using the `r sds_newword(“range”) as a summary – the interval between the largest value and the smallest. But the maximum and minimum are not at all robust. It’s better to work with more robust descriptions.
To mark the path forward, let’s start by giving the range a new name. We’ll call it the “100% summary interval.” The 100% summary interval contains all of the values being summarized. In the same spirit, imagine an interval that contains 80% of the values. To be more specific, consider an interval that leaves out 10% of the values on the low side and another 10% on the high side. This is the 80% summary interval.
We’re free to define the summary interval at any level: 100%, 99%, 60%, and so on. Statistical practice has settled on a convention: use the 95% coverage interval. 95% includes almost all of the values and so the 95% interval is representative. The 95% interval excludes 2.5% of the values on the low side and 2.5% on the high side – sufficient to handle the occasional rare outlier. Figure 4.3 shows the data on lung volume stratified by smoking status, along with 95% summary intervals for each group.
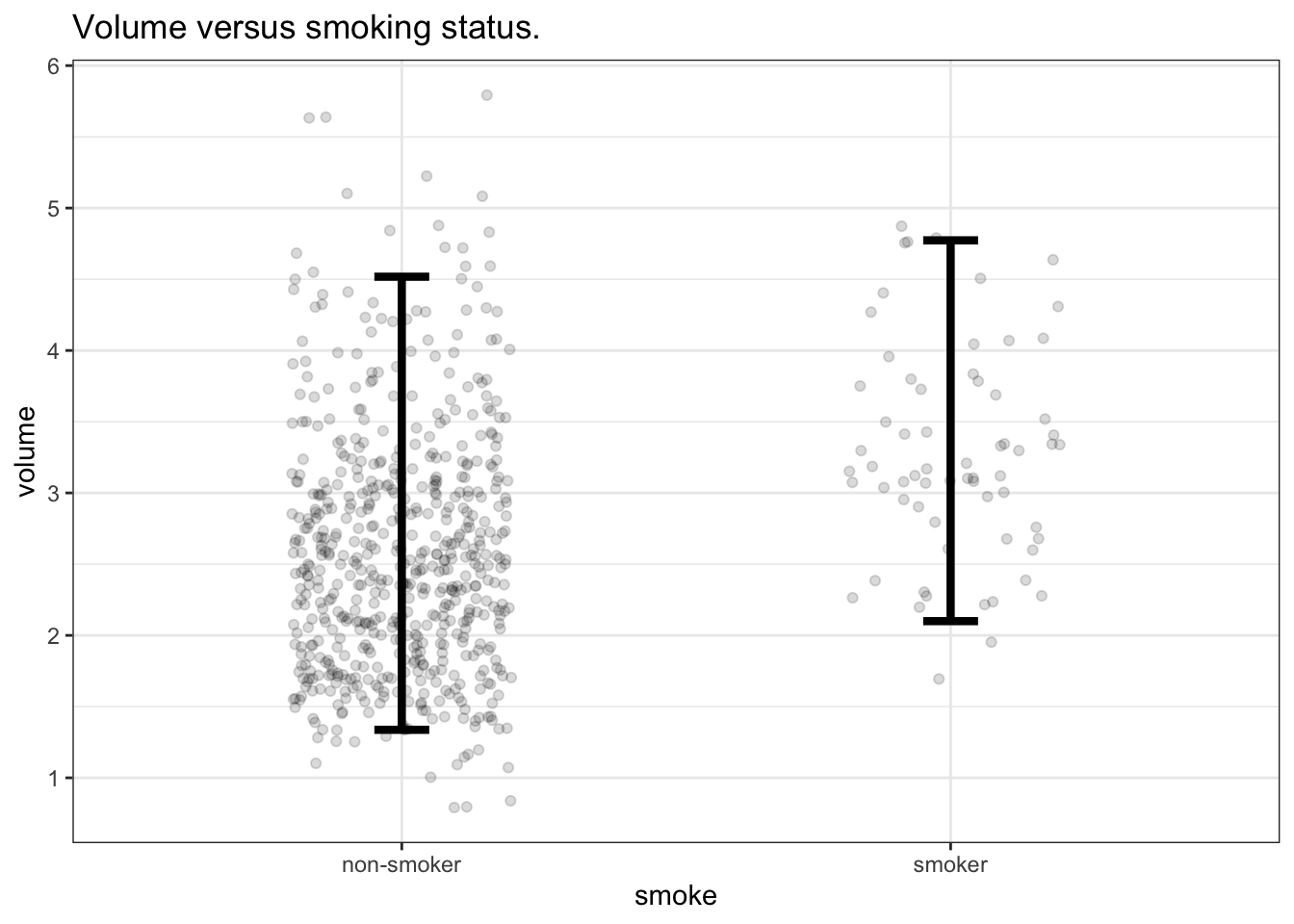
Figure 4.3: Lung volume versus smoking status along with the 95% summary interval for the lung volume of the people in each group.
Note that there are 65 smokers displayed in Figure 4.3. A 95% summary interval should include 95% of those points. Seen another way, the 95% summary interval excludes about 5% of points. Five percent of 65 is 3.25 and so the 95% summary interval should exclude about 3 data points.
Obeying the convention of using a 95% summary interval has the benefit of helping to reduce confusion. It’s a standard. People trained in statistics are habituated to interpreting intervals as if they were at a 95% level. If I had the power to re-write history, for a variety of reasons I would set the standard at 80%. And it’s certainly legitimate practice to use 80% summary intervals so long as you are careful to make it clear to the reader that the summary interval is at the 80% level. But it’s easy for readers to miss such qualifications, so do use the 95% level unless there is a compelling reason to do otherwise.
4.5 The uses of stratification
Keep in mind that statistical summaries will depend on how you, the modeler, choose to stratify the data. Choose stratification variables that you believe or suspect will explain or account for the response variable.
The sign that a given stratification explains or accounts for the response is that the summary statistics are discernably different than they would be for unstratified data. Going further, we can look at whether the 95% summary intervals are shorter in the stratified than in the unstratified data.
Stratification can also help put explanatory variables in context. For example, the stratification of lung volume by smoking status suggests that smokers tend to have a larger lung volume. Since a high lung volume is considered healthy, does this mean that smoking can improve health?
Before jumping to that conclusion, we should consider what else might be going on. Note that the lung volume data were collected from school-age kids. Perhaps we should take into account that older kids tend to be bigger overall than younger kids. Similarly, among older kids girls tend to be smaller than boys. Figure 4.4 shows the lung volume stratified by three variables: smoking, sex, and age.
Figure 4.4: Lung volume stratified by age, sex, and smoking status. The band represents a kind of 95% summary interval applied to quantitative variables rather than discrete strata.
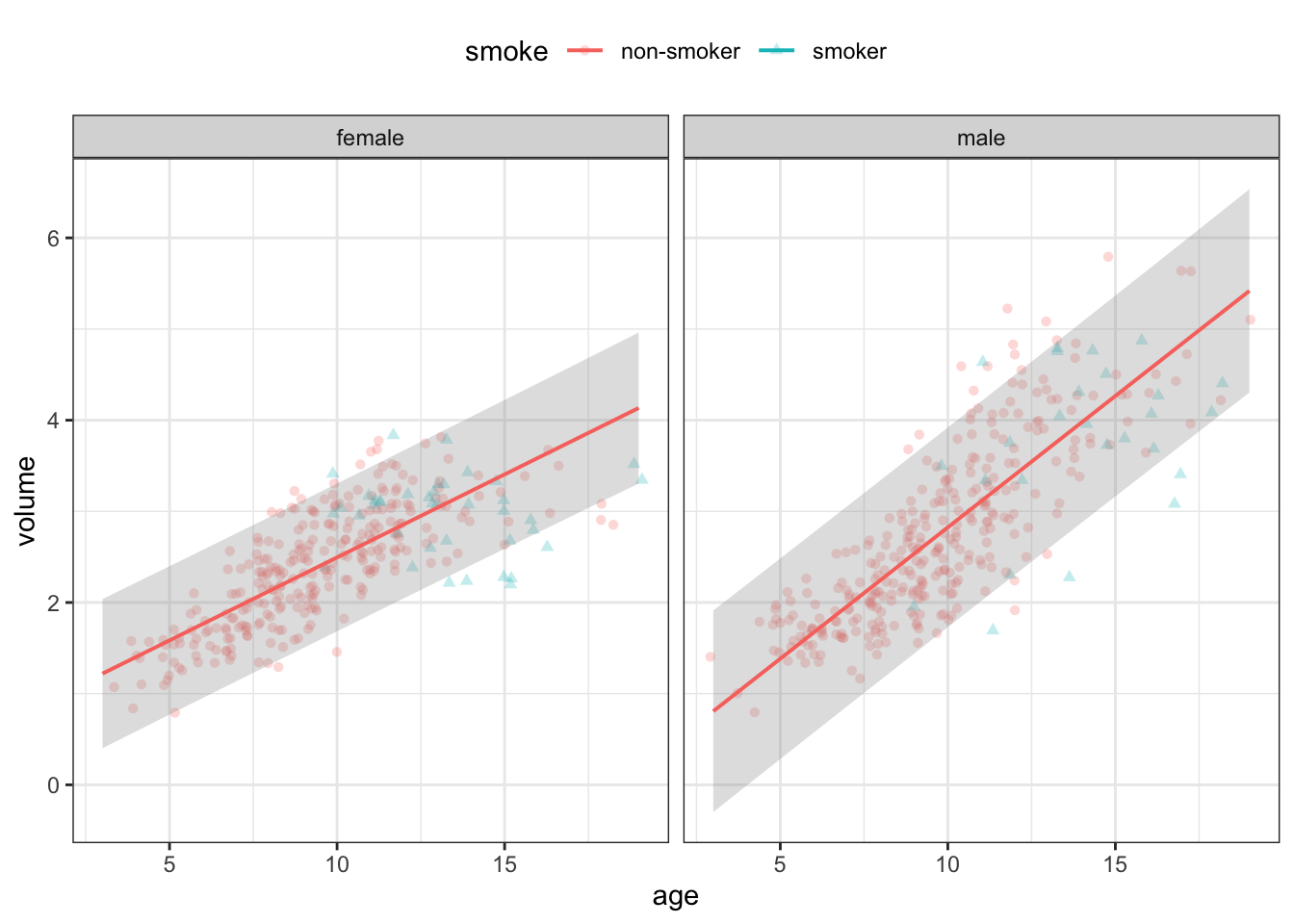
Since age is a quantitative variable, the 95% summary interval is drawn as a band rather than I-shaped glyphs. (To simplify the presentation, the summary band is just for the non-smoker strata.) There doesn’t seem to be much difference between the lung volumes of smokers and non-smokers once you take into account the variation in lung volume by age and sex. But it’s evident that smokers tend to be older than non-smokers. Perhaps that’s why the smokers as a group have larger lung volumes than the non-smokers as a group: the non-smoker group includes more young children. As we’ll see later in the book, this is a situation where smoking is entangled with age, or, to use more statistical language, smoking is confounded with age. Stratification on other statistical techniques can sometimes untangle the variables, as here.
4.6 Example: Nice weather
The mean outdoor temperature in my home town is about 47°F. As I write this, in mid-October, the actual temperature is 37°F. Does that mean that today is unusually cold? There’s no way to know from a point summary like the mean. Summaries should always be chosen to support a desired purpose.
Suppose the purpose at hand is to pick a suitable wardrobe. 47° suggests a light jacket and perhaps a sweater. Gloves and cap optional.
Such clothing would hardly prepare you to live in my city of St. Paul, Minnesota in the northern US. The temperature ranges from -30° to 105°, the 95% interval is about -10 to 90. Summarizing temperature by a mean doesn’t convey the information needed for making sensible choices. On the other hand, the complete temperature range is misleading. The arctic weather of -30° is rare, happening about once a decade. The 95% summary interval is a better summary of the temperature than the mean or the range.
Weather records are often stratified by month. This is common sense. Seen statistically, the benefit of stratifying by month is that the 95% summary intervals are much narrower than the unstratified intervals. Since we usually know the month, the stratification provides more information.
Figure 4.5 contains three graphs giving different amounts of detail about the outdoor temperature. Consider these two questions one might seek to answer with weather data.
- When can I plant my vegetable garden? I need to avoid frost.
- Is there any hope that an October or November day will be as warm as a summer day?
Figure 4.5: Monthly outdoor temperatures in St. Paul, Minnesota. (a) shows the mean temperature. (b) shows both the mean high and low temperatures. (c) gives 95% summary intervals on the high and low. The horizontal line indicates the temperature of freezing.
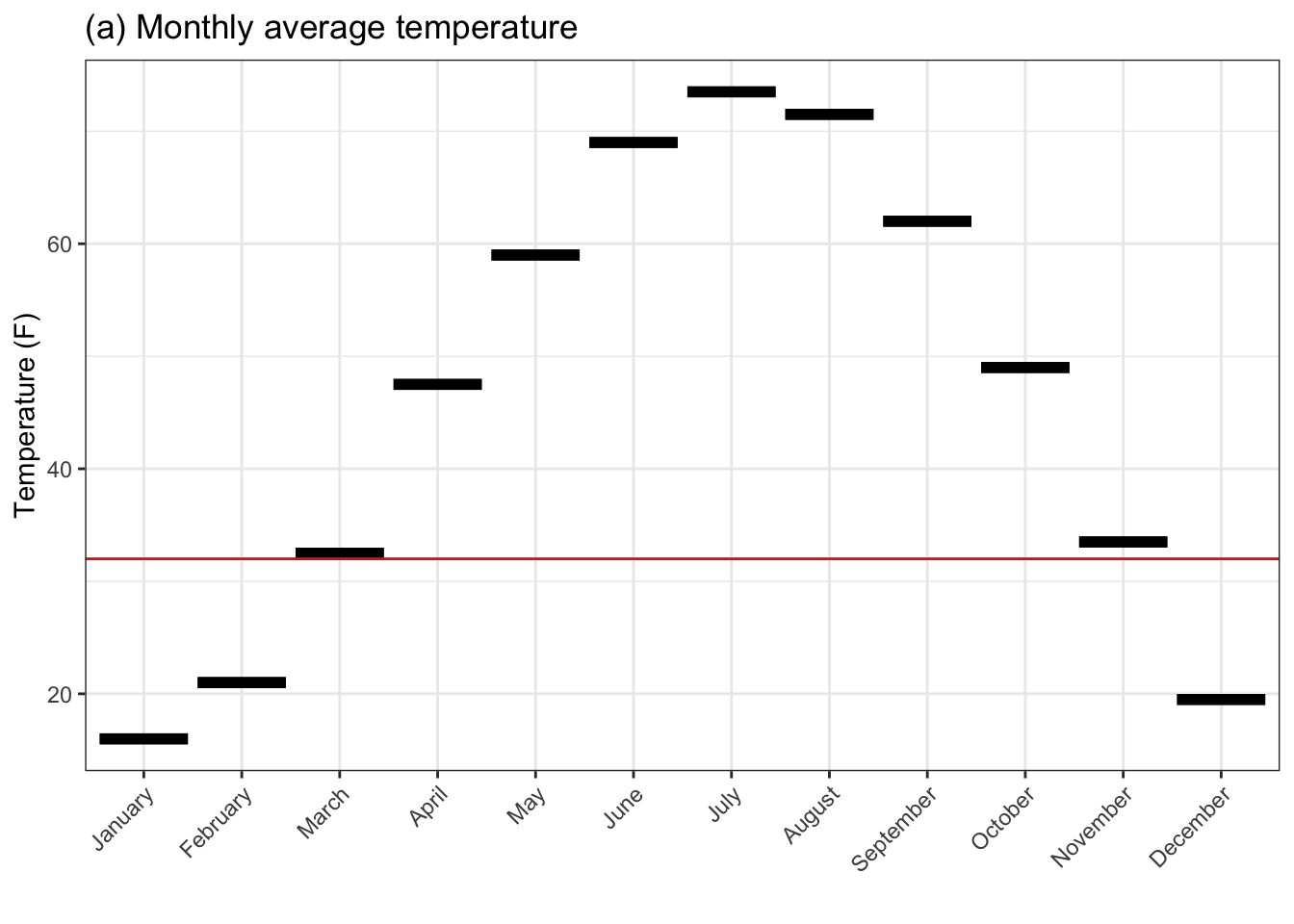
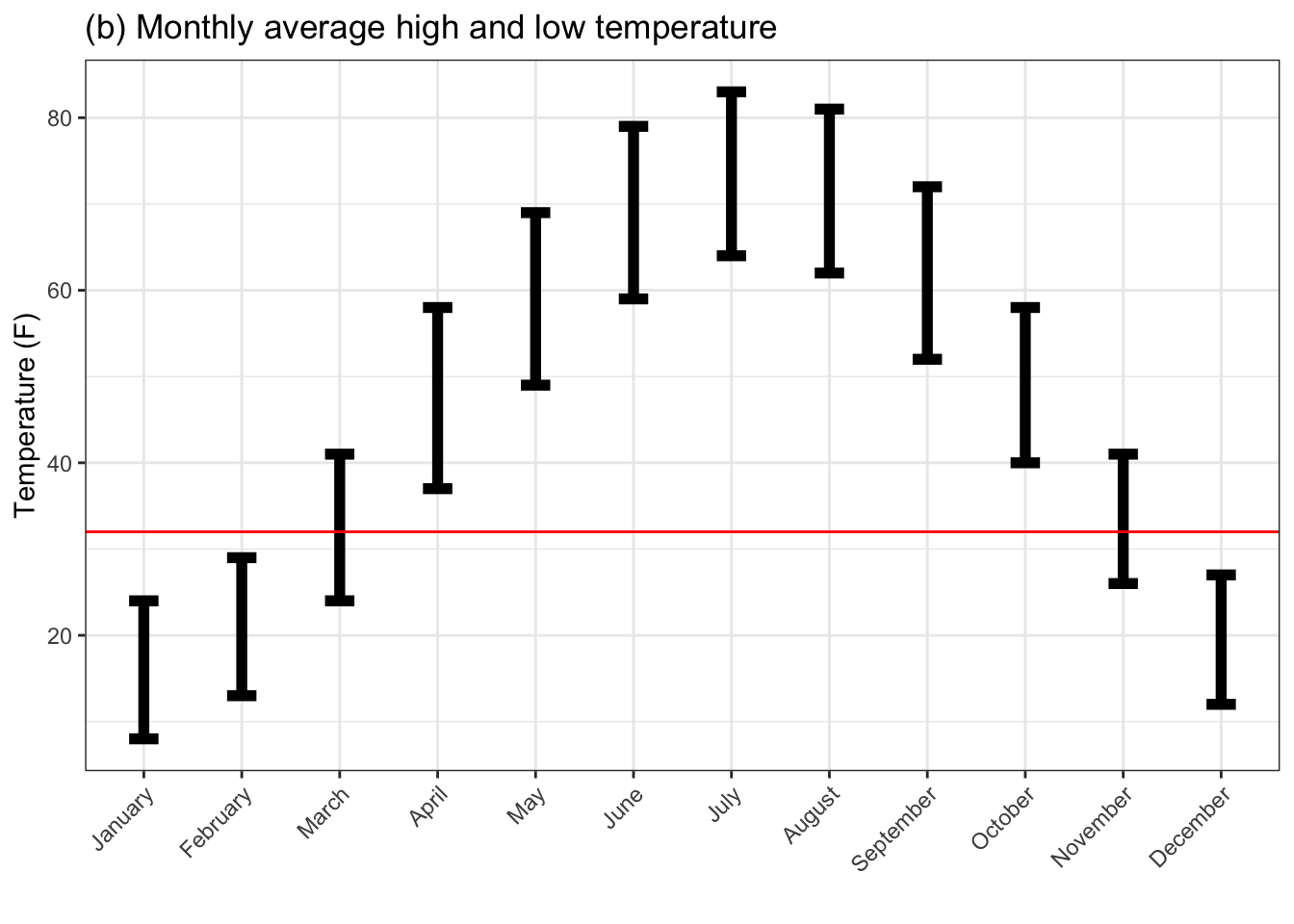
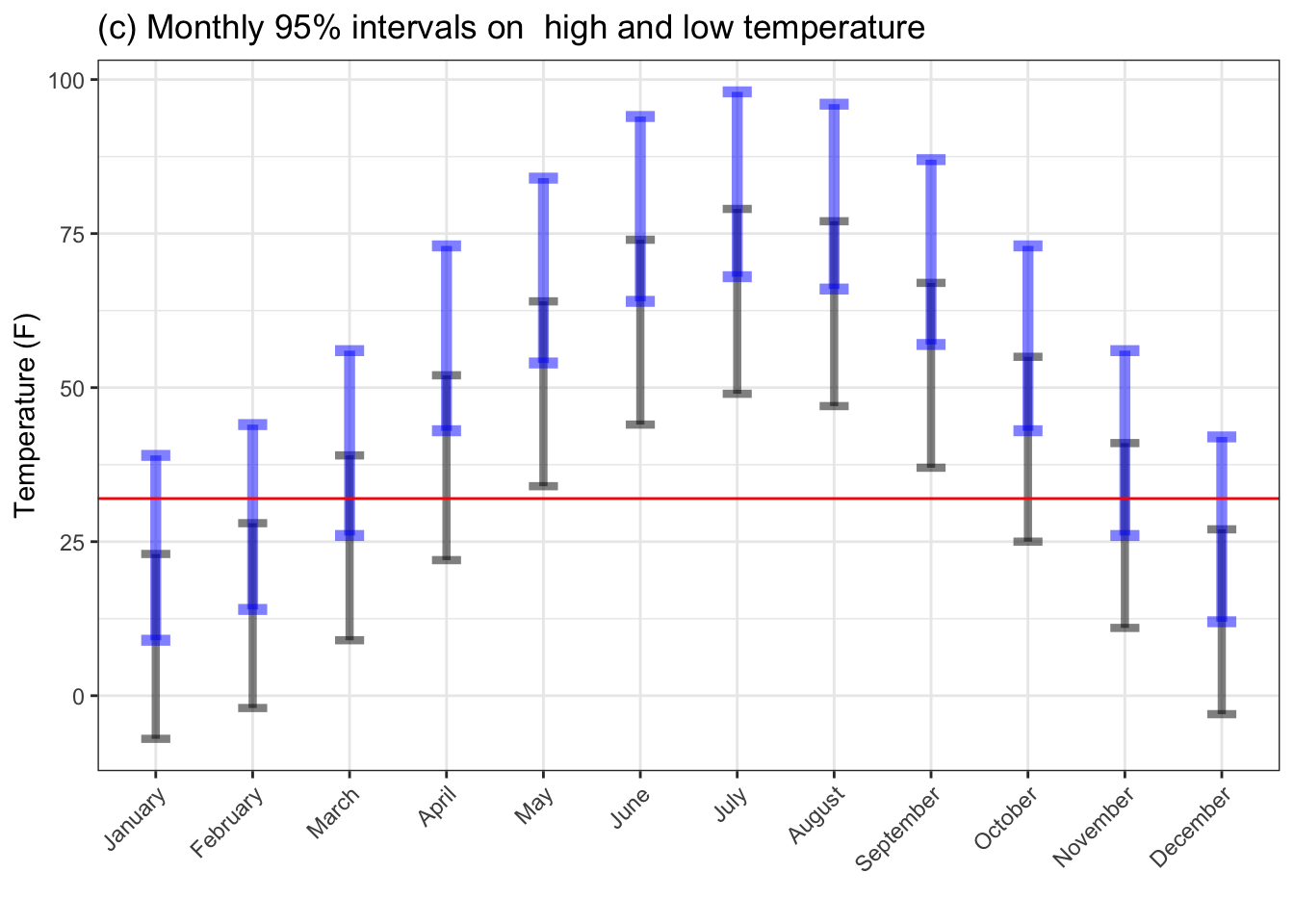
Figure (a), showing the average temperatures, suggests that March and November are pretty close to freezing, so plant in April and expect to harvest by October. October is 20°F colder than summer temperatures. (Even September is substantially cooler than summer.)
Figure (b) shows the average high and low temperatures which seems to be the format favored by web sites. April and October temperatures are above freezing, so good for gardening. As regards summer in October, the daytime October temperature is below the summer nighttime temperature, so you won’t see summer in October.
Figure (c) gives a 95% range for daily high and low temperatures. The conclusions drawn from it differ than those suggested by (a) and (b). Even May and September get close to frosty. And an October day may well reach the level of the summer months.
Summary intervals give a much better basis for making realistic choices. Means fail to display the variability that is a ubiquitous feature of our world.
4.7 Example: Mean stereotypes
Many of our beliefs about the world are shaped by means and a mistaken belief that a “typical” value is representative. Are men taller than women? In the US, the mean adult male height is 180cm (5 ft 9) while the mean female height is 162cm (5 ft 4). Summaries like this sometimes get translated into phrases like “the average woman is 5 ft 4.” Of course there’s no such thing as the average woman or the average man; women differ from one another and men differ from one another. And many women are taller than many men.
Stereotypes fallaciously condense diversity into typecast labels and force people into pigeonholes that are too tight to contain them. Consider this stereotype: boys are better at math than girls. Such beliefs are reinforced by data, but only if you hide the actual distributions. For instance, the headline “2016 SAT test results confirm pattern that’s persisted for 50 years — high school boys are better at math than girls” source is followed by a graphic showing in detail how math scores for men have stayed higher than those for women over the last fifty years. In 2016 the mean score was 527 for males and 496 for females. (I won’t reproduce the graphic here since to avoid a careless reader concluding that such a presentation of means is a good practice. Nonetheless, it is unfortunately a common practice.)
I was able to track down a rough description of the distribution of SAT math scores by sex. source It would be easy for the relevant organization to publish a complete list of test scores, person-by-person, while maintaining the confidentiality of the test-taker. Perhaps the reason they don’t is that surprisingly few people are inclined to look at distributions rather than means. (I’m hoping you, dear reader, will turn out differently!)
Figure 4.6 shows what the person-by-person SAT math score data would look like if it had been published.
Figure 4.6: The distribution of scores on the SAT mathematics test, reconstructed from summary data published by the College Board.
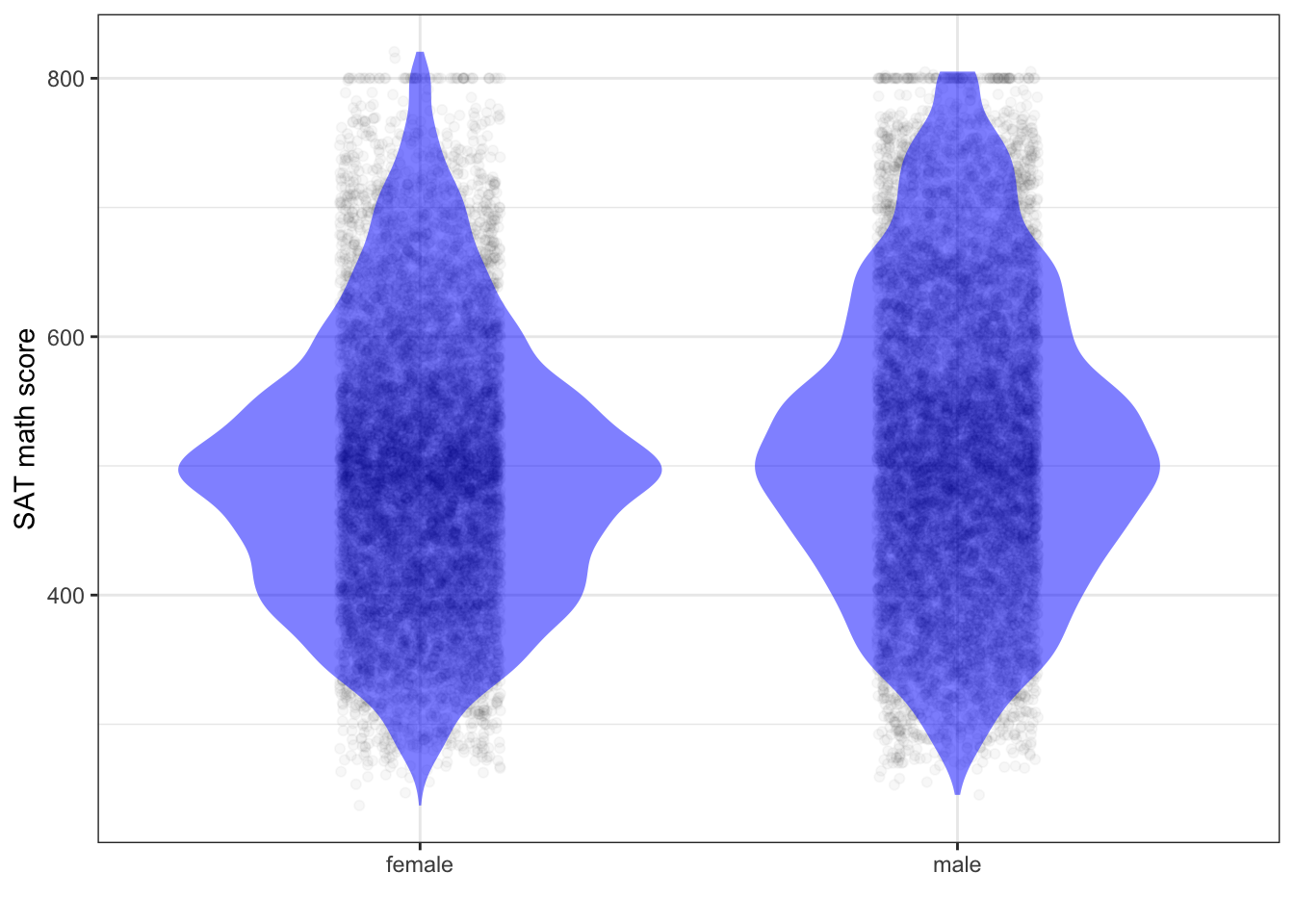
The differences between the distributions for males and females are small. The first sentence of any accurate summary of Figure 4.6 is that males and females are basically the same.
4.8 Summarizing categorical variables
The previous sections dealt with summarizing quantitative response variables in individual strata. There were a variety of types of summaries: point summaries, interval summaries at specified percentages, and so on. For categorical variables, the situation is simpler. There is just one kind of summary that’s needed.
As you recall, a categorical variable has discrete levels, each of which can be given a label, typically a word. The variable smoker in the lung volume example used previously in this chapter had two levels: “smoker” and “non-smoker.” It’s easy to imagine a similar variable about smoking history with several levels, say “never,” “current,” “past.”
To summarize a categorical response variable, take each stratum in turn and calculate the fraction of cases that take on each level. For instance, consider stratifying smoke by sex. For females, 88% of the cases are non-smokers (leaving 12% as smokers). For males, 92% are non-smokers (leaving 8% as smokers). For each stratum – females and males – the fraction is reported for each possible level of the categorical response variable.
When summarizing categorical variables with more than two levels, the proportion for each level should be reported. To illustrate, let’s examine the general health of the people recorded in the National Health and Nutrition Evaluation Survey (NHANES). We’ll stratify by the person’s work status: HealthGen ~ Work.
Table 4.2: Summarizing health stratified by work status using the NHANES data. Numbers are in percent.
| Working | Looking | NotWorking | |
|---|---|---|---|
| Excellent | 13.1 | 9.1 | 9.3 |
| Vgood | 35.3 | 31.5 | 28.1 |
| Good | 39.5 | 44.4 | 39.0 |
| Fair | 11.2 | 14.3 | 18.0 |
| Poor | 0.9 | 0.7 | 5.6 |
There are five levels in the response variable, so five fractions are reported for each stratum of work status. It’s easy to lose track in Table 4.2 which variable is the response and which is the explanatory. One way to sort it out is to note that the numbers within each stratum add to 100%. So, if you got confused and thought that “Excellent” is a stratum, you can straighten yourself out by noticing that the numbers in “Excellent” – 13.1%, 9.1%, 9.3% – do not add to 100%. So “Excellent” is not a stratum, it is a level of the response variable.
Table 4.2 is written in a way that’s consistent with the graphical convention that the explanatory variable goes on the horizontal axis and the response variable goes on the vertical axis. Such consistency helps to avoid confusion.
Do notice that Table 4.2, as appropriate for summarizing categorical variables, presents proportions, not counts. Keep in mind that the purpose of such a table is to summarize a response variable using the data as evidence. A table of counts, although useful for some purposes, is a summary of the data. A table of counts does not show us directly what is the relationship between the response and explanatory variables.
4.9 Example: So many strata!
Although age is a quantitative variable, the lung-volume data represent it as discrete quantities: 3, 4, 5, and such. Figure 4.7 shows a stratification of smoking status versus age in the lung-volume data. Each dot is one proportion. Only one number needs to be shown at each age because the proportion of smokers must always be one minus the proportion of non-smokers.
Figure 4.7: Stratifying smoker status by age. The dots show the proportion of non-smokers at each age. The smooth curve is generated by a modeling technique, logistic regression, covered in later chapters.
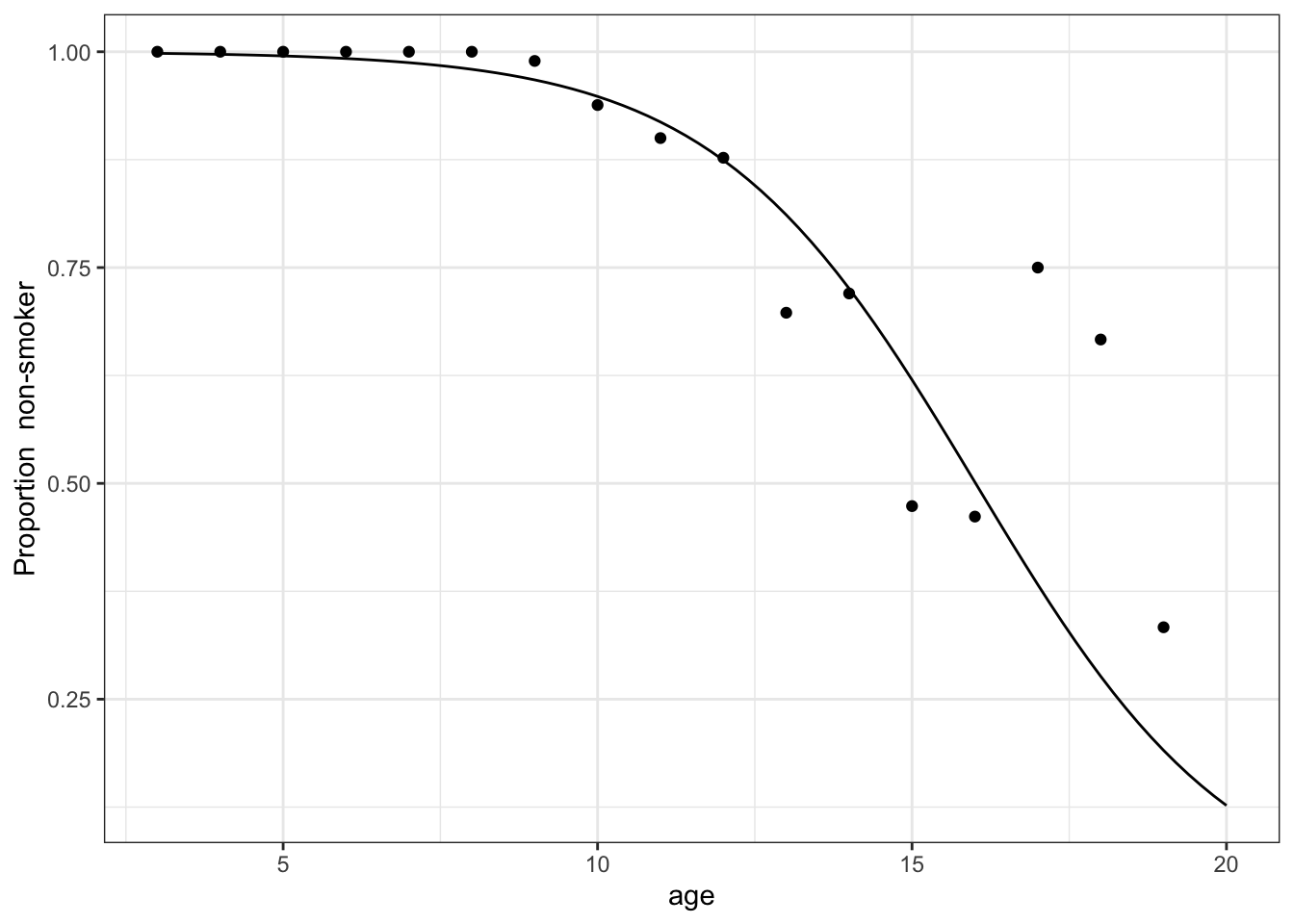
For ages 13 and older, there is a lot of jaggedness. This is happening because there is so little data at each individual age that the exact proportion depends on the luck of the draw in selecting the sample of people. Such jaggedness is characteristic of situations where there are so many strata that there is little data in each one.
The smooth curve in Figure 4.7 shows a modeling technique to be introduced in later chapters that helps to mitigate the problems caused by small data by taking into account the idea that the proportions at nearby ages should be similar. Stratification is a valuable technique, but other ways of summarizing relationships can be easier to assimilate.
4.10 Exercises
Problem 1: To illustrate stratification, consider this very simple, unrealistically small, made-up data frame listing observations of animals:
| species | size | color |
|---|---|---|
| A | large | reddish |
| B | large | brownish |
| B | small | brownish |
| A | large | brownish |
The stratifications you will build in (1)-(4) will be in the form of a table, like this, although there might be only one explanatory variable, or perhaps none.
| size | color | Prop. of A |
|---|---|---|
| large | brownish | 0.5 |
| and so on |
- Use just
sizeas an explanatory variable. Since there are two levels for size, the classifier can take the form of a simple table, giving the proportion of rows for each of the two sizes. Fill in the table to reflect the data.
| size | prop_of_A |
|---|---|
| large | |
| small |
- Repeat (1), but instead of “size”, use just “color” as an explanatory variable.
color prop_of_A reddish brownish - Again build a classifier, but use both color and size as explanatory variables.
| color | size | prop_of_A |
|---|---|---|
| reddish | large | |
| reddish | small | |
| brownish | large | |
| brownish | small |
- Finally, build the “null model”, a no-input classifier. This means there is just one group, which has all four rows.
Problem 2: A problem about translating between bottom-top and plus-or-minus.
Intervals are commonly written in two ways: a bottom-to-top format or a plus-or-minus format. For instance, the summary interval for times between busses might be written 6.5 ± 3.5 minutes. Whether the plus-or-minus format or the bottom-to-top format most effectively communicates with the human making use of the information depends on the situation (and perhaps who that human is). Still, the two formats are mathematically equivalent.?
Problem 3: Efficiency of fuel use is not the only, nor necessarily the main consideration when buying a car. For instance, people understandably base their choice on passenger and luggage volume as well as power and performance.
Some people believe that engine power needs to be proportional to passenger and luggage volume, or, in other words, that a capacious car needs a high-power engine. The EPA doesn’t consistently publish data on engine power, but a reasonable proxy is engine displacement: the volume of the cylinders.
The graph shows the relationship between passenger volume and engine displacement for 2019 model-year cars. The unit of observation is a car model, so the graph accurately reflects the range of cars on the market. Of course some car models will be more popular than others, but this is not indicated by the graph.
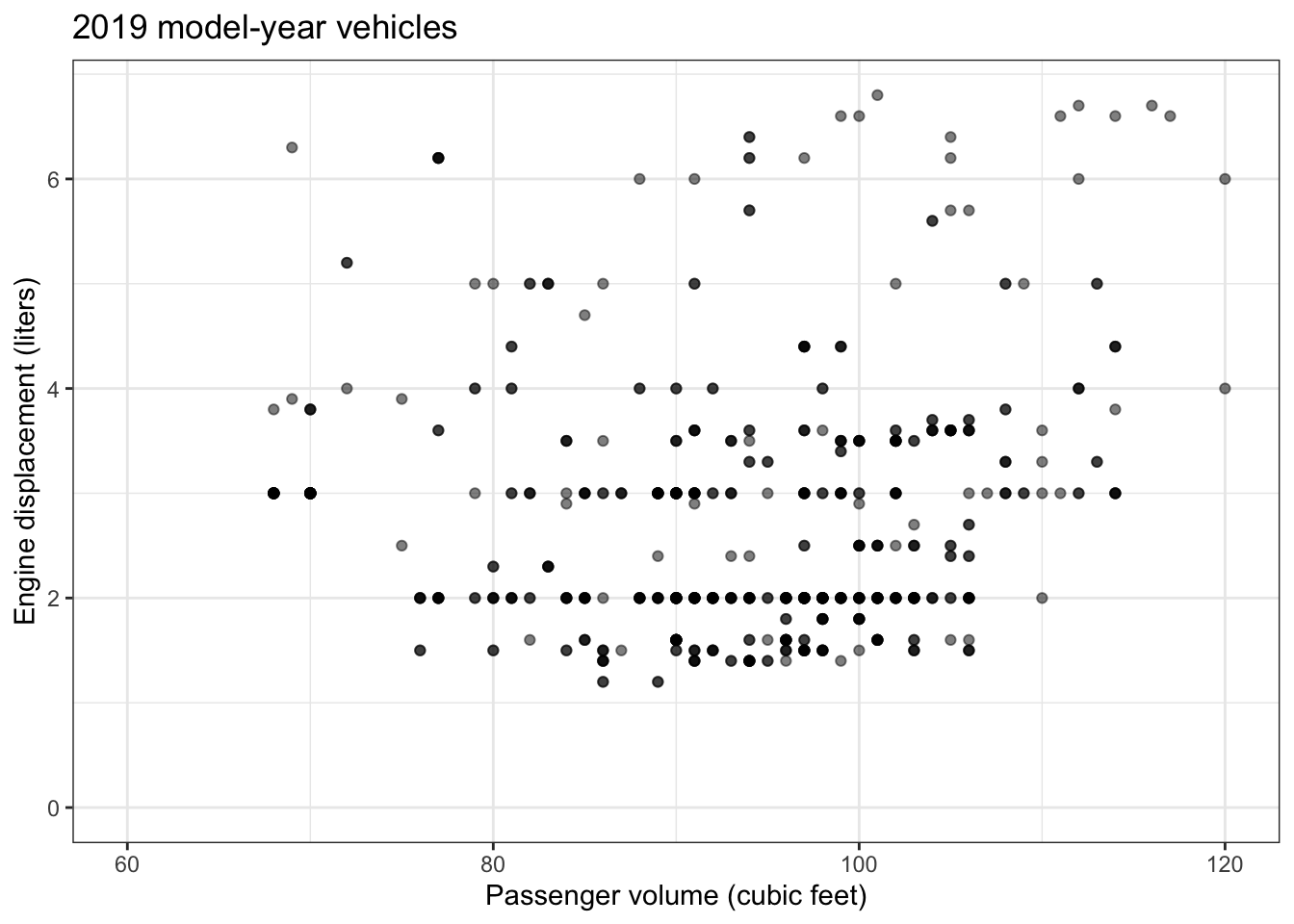
- Split the horizontal axis into discrete strata: <70, 70 to 80, 80 to 90, and so on.
- What is the 95% summary interval on displacement for the 70 to 80 category?
- What is the 95% summary interval on displacement for the 100 to 110 category?
- Comparing the 70 to 80 and the 100 to 110 cubic feet strata:
- how does the engine displacement vary?
- Is there a strong relationship between passenger volume and engine displacement?
- Consider the vehicles at the extremes of passenger volume, either very small (< 70) or very large (> 110).
- How are these extreme vehicles systematically different in displacement than the large majority of vehicles with passenger volumes between 70 and 110 cubic feet?
- Are the very large and very small vehicles similar or different from each other in terms of displacement? Give a common-sense explanation for the pattern.
Problem 4: The graph plots winning time in the Scottish hill races as a function of climb (in meters) and distance (in km). There is a jittered data layer as well as an interval layer showing the 95% coverage interval.
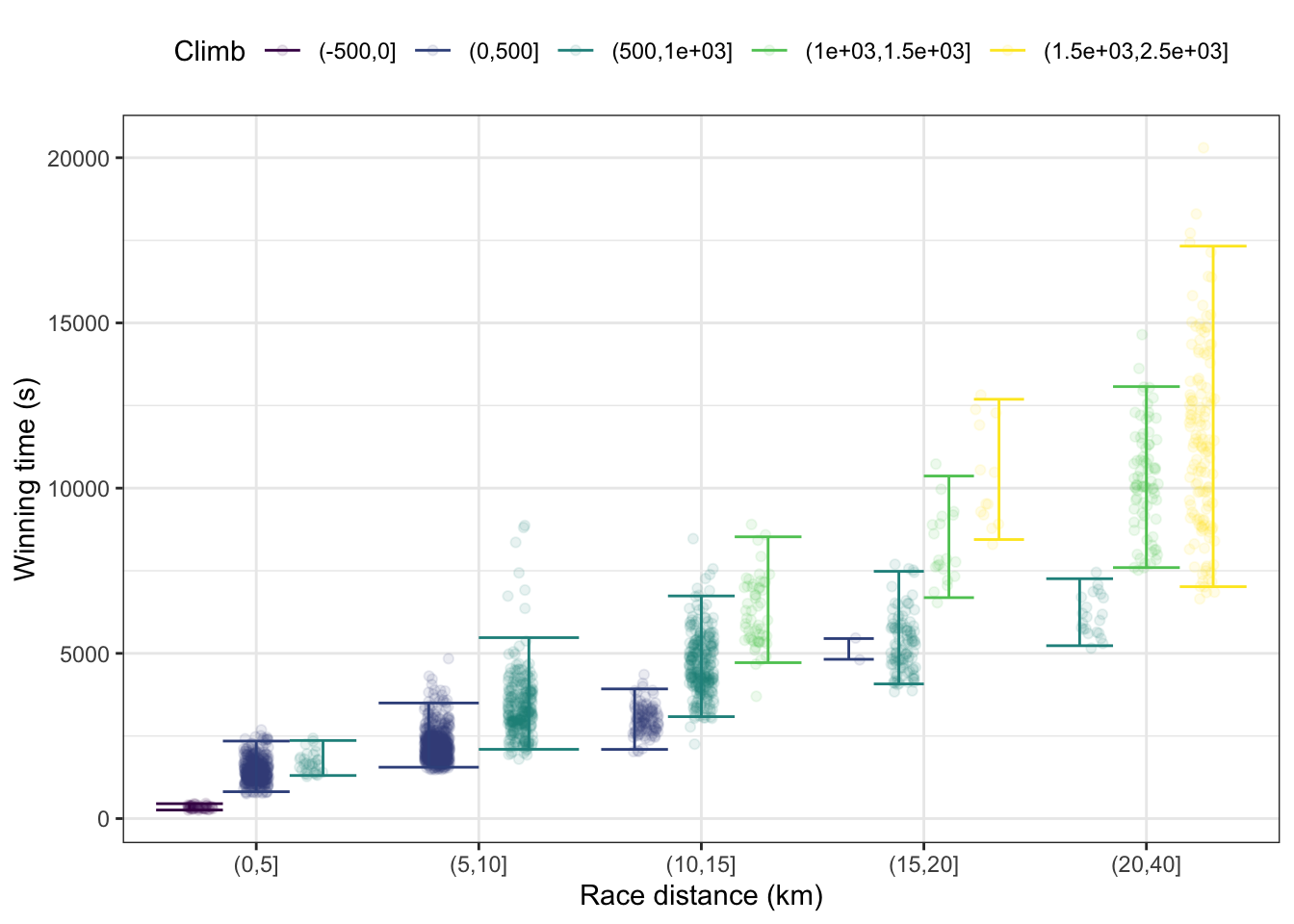
- What is the unit of observation for the data layer.
- How many different strata for race distance are there?
- From the legend you can see that there are five strata for climb. Yet not every climb stratum shows up for each distance stratum. State, in everyday terms, why some strata are missing.
- Your friend, a competitive hill racer, is planning to run a race with a distance of 13 km and a climb of 1200 m. Make a prediction, in the form of a 95% interval, of how long the race will take for the winner.
Problem 5: In 1972, the US Congress approved the Equal Rights Amendment to the US Constitution, intended to guarantee equality under the law for women and men. (The ERA was ratified by 35 of the 50 states, but this was too few for the amendment to become part of the Constitution.
Perhaps in response to the mood of the time, officials at the University of California Berkeley examined the statistics of graduate-school admissions for the Fall 1973 quarter to look for signs of possible discrimination. Data for the six most popular graduate departments is provided in the SDSdata::UCB_applicants data frame. Tables A through D show different views of the data
Table 4.3: Table A
| admitted | rejected | |
|---|---|---|
| female | 31.7 | 46.1 |
| male | 68.3 | 53.9 |
Table 4.3: Table B
| female | male | |
|---|---|---|
| admitted | 12.3 | 26.5 |
| rejected | 28.2 | 33.0 |
Table 4.3: Table C
| female | male | |
|---|---|---|
| admitted | 557 | 1198 |
| rejected | 1278 | 1493 |
Table 4.3: Table D
| admitted | rejected | |
|---|---|---|
| female | 30.4 | 69.6 |
| male | 44.5 | 55.5 |
For each of the four tables (which all summarize UCB_applicants), say whether the table is in the form of counts or percent, and what variable (if any) is being used to stratify the table.
| Table | counts or percent? | stratification variable? |
|---|---|---|
| A | ||
| B | ||
| C | ||
| D |
Problem 6: One of the approaches considered to help lower carbon-dioxide emissions is a tax on carbon to discourage the use of carbon-based fuels. It’s been suggested, based on climiate and economic models, that an appropriate tax rate to reflect the social costs of carbon dioxide is about $30 per metric ton of CO2, or, equivalently 3¢ per kilogram.
One possibility to reduce emissions is to switch to a hybrid vehicle. Figure @ref(fig:fish-dive-plant62305-1} compares the CO2 emission in kg per year of driving for hybrid and non-hybrid passenger vehicles. (A year is defined here as 10,000 miles of driving.)
Figure 4.8: CO2 emissions and fuel use by 2019-model passenger vehicles.
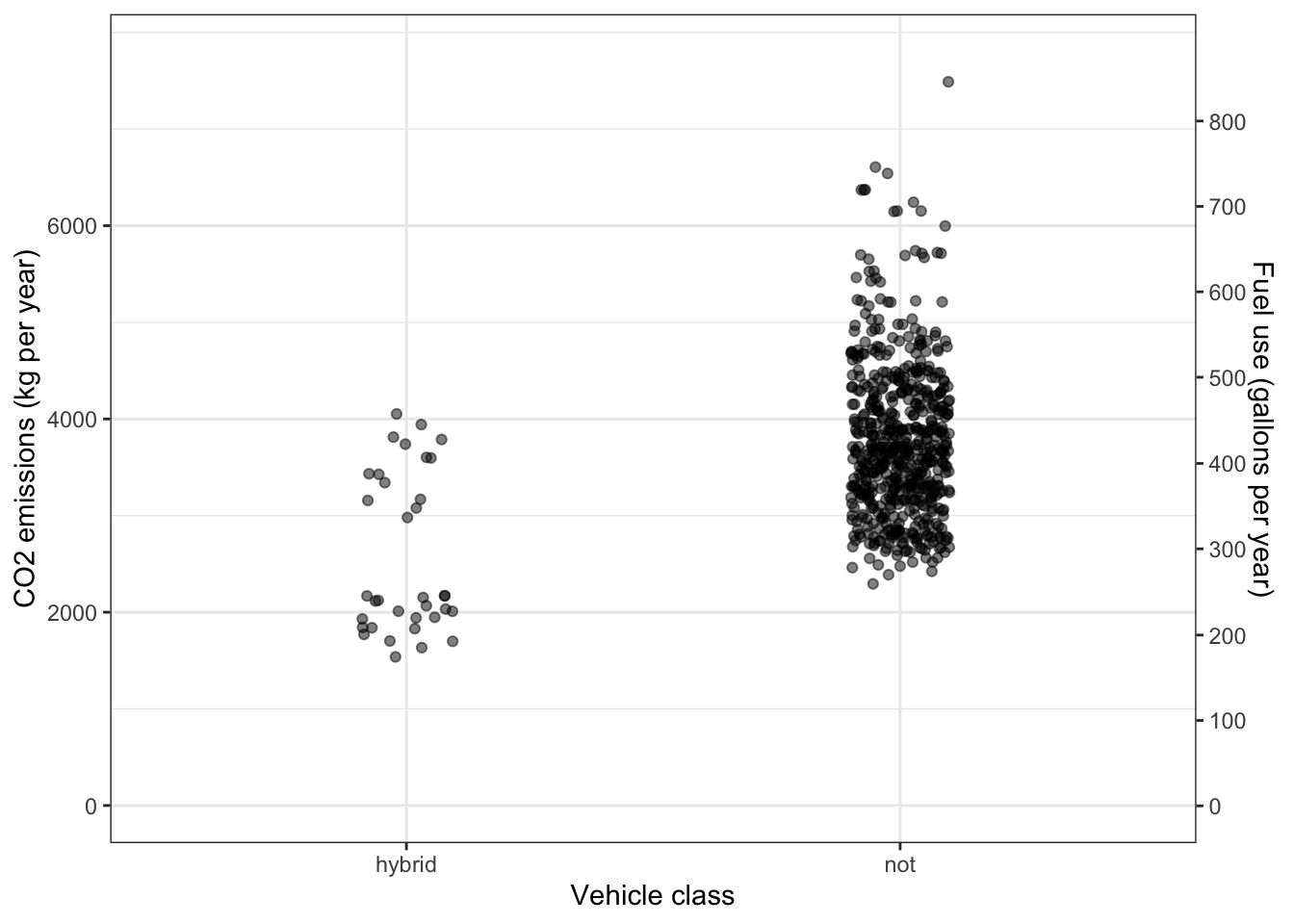
At a hypothetical CO2 tax rate of 3¢ per kg, how much would taxes per year be reduced for a person to switch the choice of a new car from a non-hybrid to a hybrid vehicle? Use the mean emissions for each vehicle class in your calculations. Over a 10-year period, would the reduced taxes (on their own) be a strong motivating factor for switching to a hybrid? Explain why or why not.
Figure @ref(fig:fish-dive-plant62305-1} also displays the yearly fuel use. (CO2 emission is directly related to fuel use. A gallon of gasoline corresponds to about 9kg of carbon-dioxide.) Using the mean consumption for the hybrid and non-hybrid vehicle classes, how much money would be saved by choosing a hybrid rather than a non-hybrid vehicle? Use $3.00/gallon as the price of fuel.
People buying a new car face some uncertainty in their fuel-related expenses. A major uncertainty is the price of fuel. In part (2) we used a hypothetical cost of $3.00 per gallon. In the last decade in the US, gasoline market prices have ranged from $1.50 to $4.50 per gallon. Written another way, the gasoline price has been in the range $3.00 ± 1.50. Ironically, as CO2-emissions restrictions come into action, the price of carbon-based fuels will likely drop. (Less demand implies lower price.)
- By how much would the price of fuel per gallon have to drop to compensate entirely for the proposed 3 cent per kilogram CO2 tax? (Hint: One gallon of gasoline produces about 8.6 kg of carbon dioxide.) Is the market-based uncertainty in fuel cost (roughly ±$1.50) small or large compared to the proposed tax.
Problem 7: BREAK INTO TWO PROBLEMS Some examples of stratification to use in exercises.
In the previous chapter, we looked at informative formats for summarizing individual variables. We often gain valuable insight into a variable by relating it to other variables, as we have done with graphics. A familiar, everyday variable is human height. Figure 4.9 shows the height variable from the National Health and Nutrition Evaluation Survey.
Figure 4.9: (ref:heights2-cap)
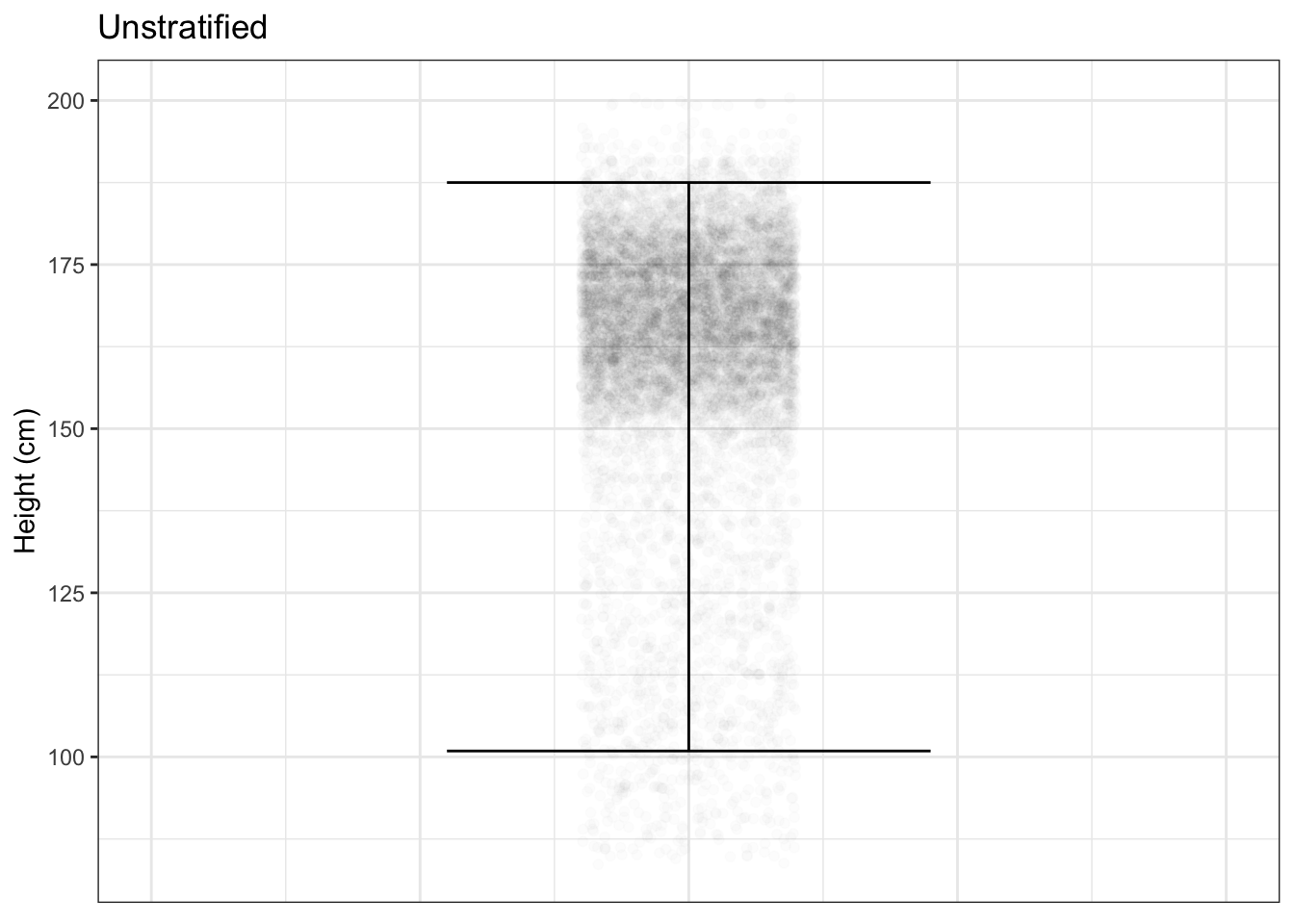
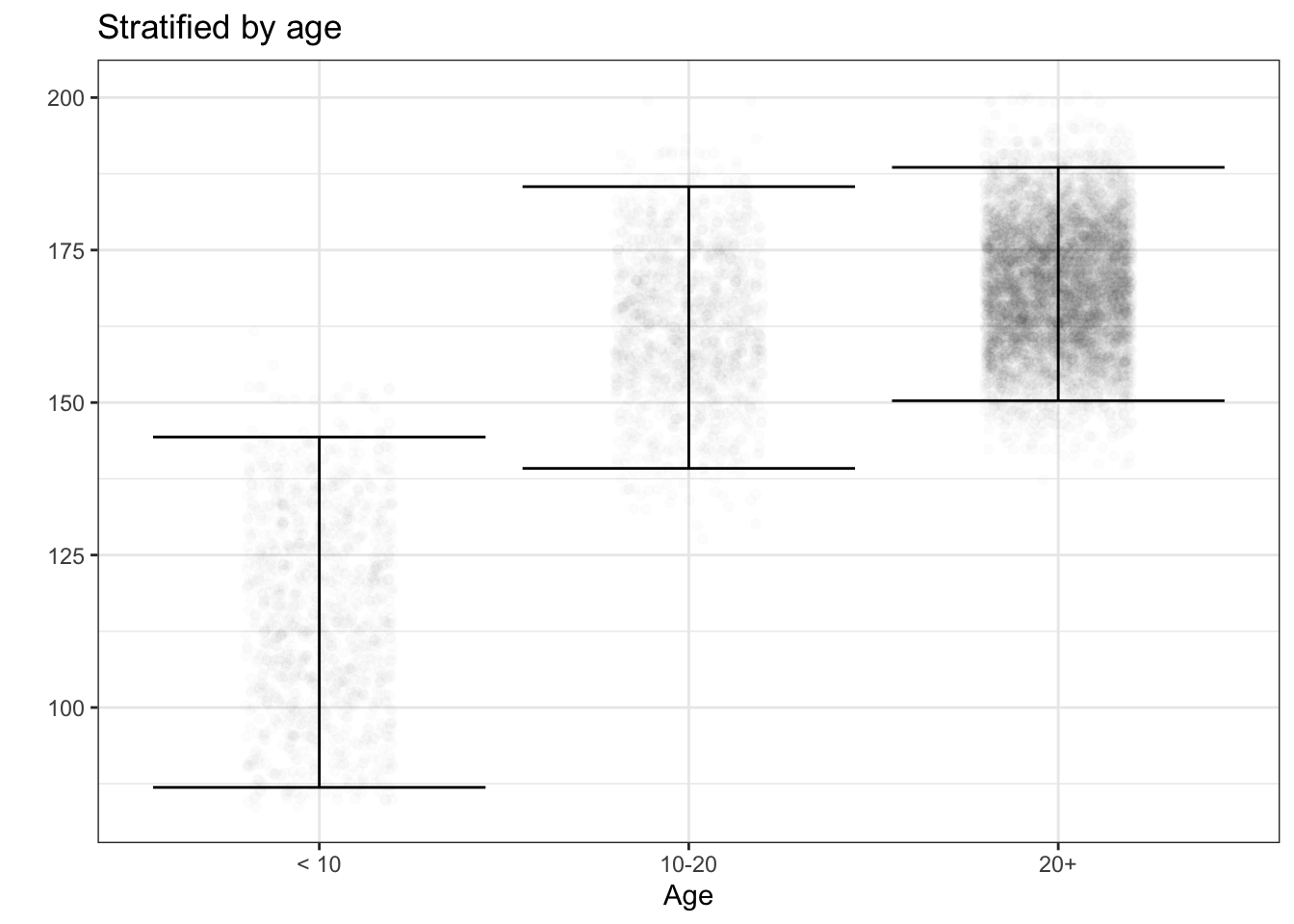
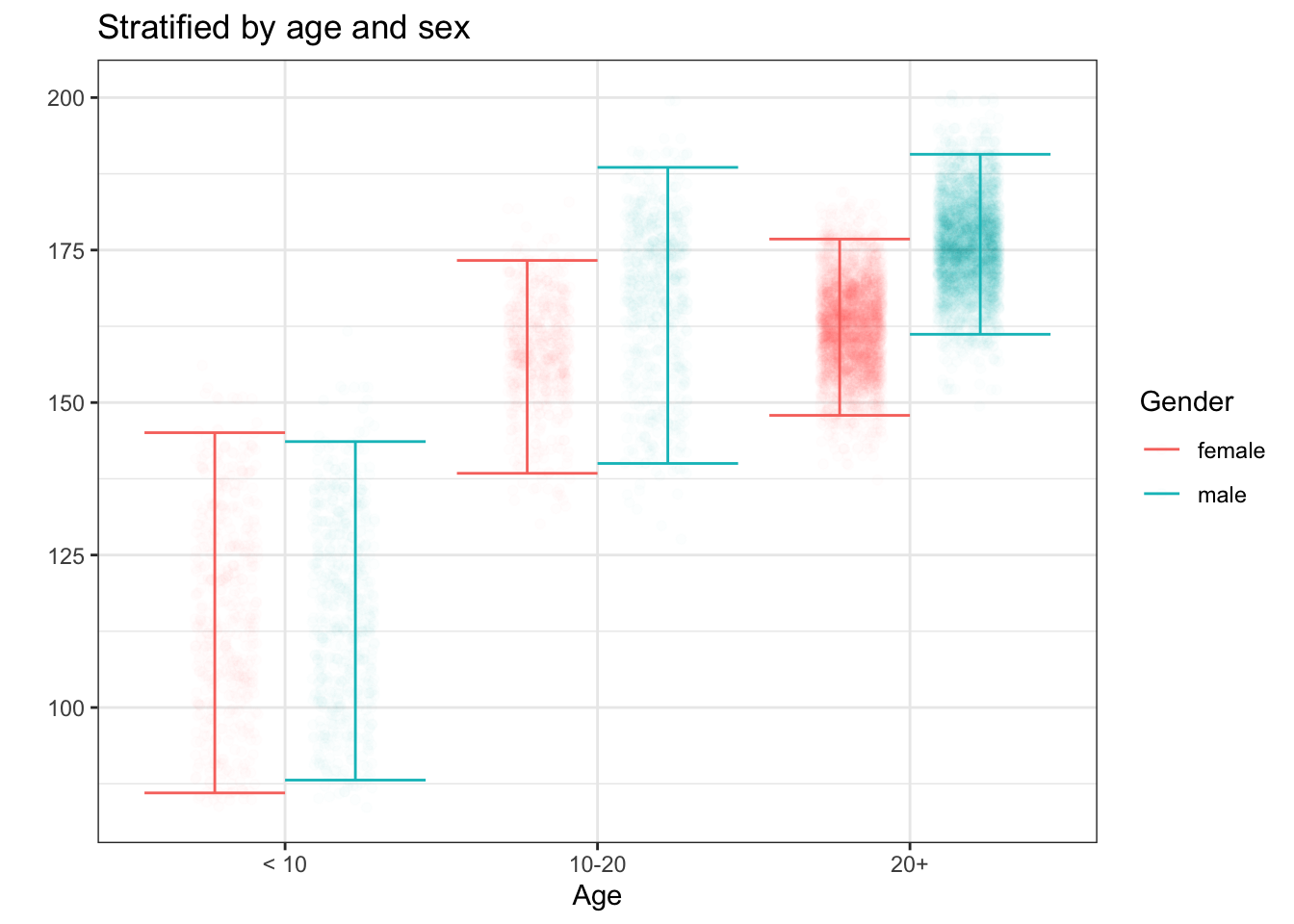
In the unstratified data, the summary interval is very long. Stratifying heights by age group reveals – what you already know! – that height is a function of age. The summary intervals for height ~ age are much shorter than in the unstratified plot. Further stratifying by sex shortens the intervals still more.
This process of breaking down data according to one or more variables is called stratification, from the Latin word for “spread.”
There are two important roles for stratification in studying data:
- Stratification shows the relationship between the response variable and an explanatory variable, for instance, the relationship between height and age in Figure 4.9.
- Sometimes the relationship between two variables, say height and sex, can be obscured by variation in another variable such as age. Stratification can clarify the relationship that would otherwise be obscured.
Here’s another way to look at (2). Suppose we diagram the relationships among height, age, and sex using arrows. A diagram that says, "Height is determined by both age and sex.
\[\mbox{age} \rightarrow \mbox{height} \leftarrow \mbox{sex}\] If our interest is just in one arrow, say \(\mbox{height} \leftarrow \mbox{sex}\), we certainly what to stratify the variable pointed to by the variable pointed from. But, perhaps surprisingly, it also can help to stratify by the other variable(s) pointing to the response variable.
4.11 Stratification and explanatory variables
Carrying out a stratification is straightforward once you have selected the explanatory variables to use to define the separate groups. The selection of explanatory variables is sometimes obvious based on the purpose of your work and your understanding of how the system you are studying works, but sometimes it is a thorny issue and a matter of dispute.
In this chapter, we’ll focus on categorical explanatory variables, like sex or age decade. (Later in the book, we’ll see how to stratify by quantitative variables.)
Each categorical variable spreads the rows of a data frame into different groups, one group for each level of the variable. For instance, in the National Health and Nutrition Evaluation Survey on which Figure 4.9 is based, the age-decade variable has seven distinct levels. The sex variable has two.
When using multiple explanatory variables, the total number of groups defined is the product of the number of levels in each group. So stratifying on age (3 groups) and sex (2 groups) produces a total of 6 groups.
For each stratification group, you extract the corresponding rows from the data frame and construct a summary for one group at a time. Figure 4.9 shows the 95% summary interval for each of the 6 groups. Comparing the summaries for the different groups provides a way not just to describe the response variable, but to describe the relationship between the response and explanatory variables. In particular, the summary becomes not just an interval, but an interval that is a function of the explanatory variables.
This idea of one variable being a function of other variable(s) is so important that there are many ways to refer to the broad concept:
- one variable versus another
- one variable stratified by another
- one variable conditioned on another
- one variable explained by another
- one variable associated with another
- one variable correlated with another
- one variable modeled by another.
- one variable accounted for by another
- one variable caused by another
- one variable as a function of another
- one variable dependent on another
- In symbols: A
 B.
B.
These terms, except for one, are equivalent. You’re entitled to use the terms interchangeably. The exception is “caused by”. The use of “caused by” carries a definite connotation of a distinctive form of relationship, one where changing the the value in of the explanatory variable in the real world will change the response variable as well. For many purposes, causality is a critically important feature of a relationship. Determining whether a statement is justified that one variable is caused by another will be an important theme of this book. Stratification has a particularly important role to play in describing causal relationships between real-world variables, as we’ll discuss in the next section.
4.12 Stratifying by multiple explanatory variables
The common phrase “all other things being equal” is an important qualifier in describing relationships. To illustrate: A simple claim in economics is that a high price for a commodity reduces the demand. For example increasing the price of heating fuel will reduce demand as people turn down thermostats in order to save money. But the claim can be considered obvious only with the qualifier all other things being equal. Perhaps the fuel price increased because winter weather has increased the demand for heating compared to summer. In that case, the data will show that higher prices are associated with higher demand. Unless you hold other variables constant – e.g., weather conditions – increased price may not in fact be associated with lower demand.
Table 4.4: (ref:whickham-0-cap)
| outcome | smoker | age |
|---|---|---|
| Alive | Yes | 23 |
| Alive | Yes | 18 |
| Dead | Yes | 71 |
| Alive | No | 67 |
| Alive | No | 64 |
| Alive | Yes | 38 |
| … and so on for 1,314 rows altogether. |
Today, everybody knows that smoking leads to increased mortality. Using arrows, this can be written
\[ \mbox{smoking} \rightarrow \mbox{death}.\]
To investigate this relationship with data, we’ll need data on the mortality of both smokers and non-smokers. For instance, consider a study of heart and thyroid disease initially carried out in 1972-74 in Whickham, UK. (Vanderpump and al. 1995) In the initial phase of the study, several variables were recorded from each of 1314 women. These variables included smoking status. Twenty years later, in the second phase of the study, it was determined which of the women were still alive. The woman-by-woman data6 Available in the mosaicData::Whickham is displayed in Table 4.4.
To investigate the relationship \(\mbox{smoking} \rightarrow \mbox{death}\), we’ll certainly want to stratify the response variable death by smoking. Since death is categorical, an appropriate summary is to report the proportion of rows found at each level of the category. But, since there are only two levels, we need report the proportion for only one. (The other will be the complement of the one we report.) This summary, stratified by smoking status, is shown in Table 4.5.
Table 4.5: (ref:whickham-1-cap)
| smoker | prop_alive |
|---|---|
| No | 68.6% |
| Yes | 76.1% |
Table 4.5 shows that the smokers were more likely to be alive twenty years after the original data were collected. That contradicts what’s known about smoking and health. But why? One possibility is that the relationship between smoking and health is being obscured by another relationship: \(\mbox{age} \rightarrow \mbox{death}\).
We can use the Whickham data to look at the relationship \(\mbox{age} \rightarrow \mbox{death}\), as shown in Table 4.6.
Table 4.6: (ref:whickham-age-cap)
| age_decade | prop_alive |
|---|---|
| twenties | 98.3% |
| thirties | 94.8% |
| forties | 84.4% |
| fifties | 66.8% |
| sixties | 44.8% |
| seventies | 10.9% |
Seeing the relationship between age and mortality, it makes sense to provide a more complete diagram:
\[ \mbox{smoking} \rightarrow \mbox{death} \leftarrow \mbox{age}.\]
Even though our primary interest is in \(\mbox{smoking} \rightarrow \mbox{death}\), we may be able to clarify things by stratifying not only by smoking but also by age. The results are shown in Table 4.7.
Table 4.7: (ref:whickham-2-cap)
| smoker | age_decade | prop_alive |
|---|---|---|
| No | twenties | 98.5 |
| Yes | twenties | 98.0 |
| No | thirties | 95.5 |
| Yes | thirties | 94.1 |
| No | forties | 86.7 |
| Yes | forties | 82.8 |
| No | fifties | 72.2 |
| Yes | fifties | 61.6 |
By looking at the connection between smoking and mortality within an age stratum, we are effectively holding age constant in our analysis. Another way to think about this is that we are looking at mortality versus smoking, other things being equal.
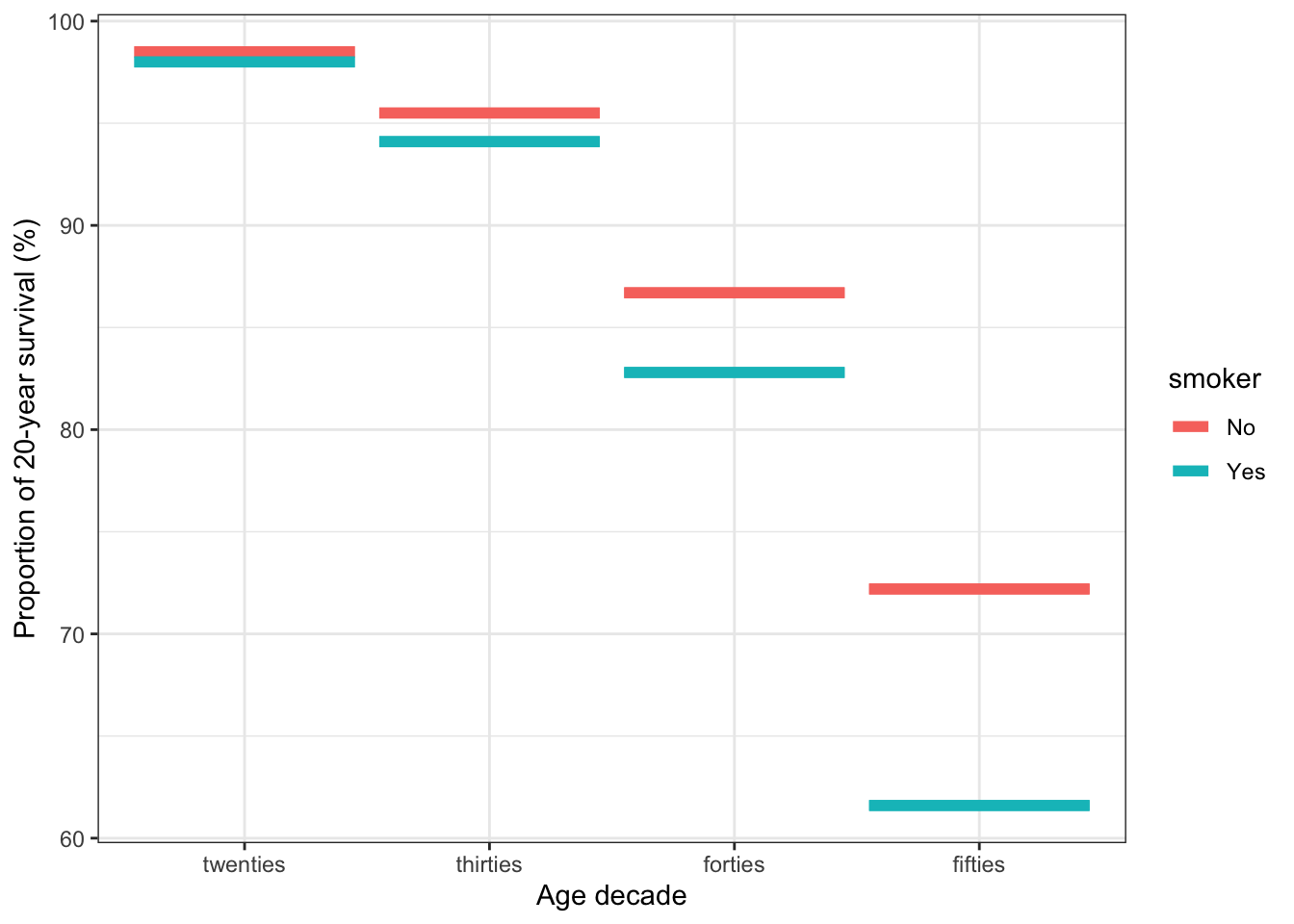
Figure 4.10: (ref:whickham-2b-cap)
Problem 8: Consider the table below, which shows general health of the NHANES survey participants stratified by their working status. The relationship being presented is HealthGen ~ Work. Health is the response variable, work status is the explanatory variable.
Table 4.8: A summary of HealthGen stratified by Work
| Working | Looking | NotWorking | |
|---|---|---|---|
| Excellent | 13.1 | 9.1 | 9.3 |
| Vgood | 35.3 | 31.5 | 28.1 |
| Good | 39.5 | 44.4 | 39.0 |
| Fair | 11.2 | 14.3 | 18.0 |
| Poor | 0.9 | 0.7 | 5.6 |
The relationship Work ~ HealthGen is different. While we might be tempted to describe both HealthGen ~ Work and Work ~ HealthGen as "the relationship between health and work status, keep in mind that in our description of relationships between two variables there are two different roles to play: the response variable and the explanatory variable.
Here’s the summary of Work ~ HealthGen:
Table 4.9: A summary of Work stratified by HealthGen
| Excellent | Vgood | Good | Fair | Poor | |
|---|---|---|---|---|---|
| Working | 67.5 | 64.6 | 59.4 | 48.1 | 21.3 |
| Looking | 3.2 | 4.0 | 4.6 | 4.3 | 1.1 |
| NotWorking | 29.3 | 31.5 | 36.0 | 47.7 | 77.6 |
Each of the two summary tables contains 15 numbers, But the numbers are not the same.
Which table would you use to determine the faction of people in poor health who are not working?
A friend looks at
Work ~ HealthGenand notices that the two largest numbers in the table are in the cells Working/Excellent and NotWorking/Poor. Your friend claims that this shows that non-working people tend to be in poor health and working people in excellent health. Explain what’s wrong about your friend’s reasoning and describe the situation as it actually is.
Problem 9: DRAFT Turn this into a problem about stratification …
Stratifying by water service …
Stratifying by location – the cholera victims are clustered.
Data from John Snow, On the mode of communication of cholera First edition, p. 24
1849 outbreak with data on water supply and value of room, On the mode of communication of cholera Second edition, pp. 62-3
Problem 10: A table of counts summarizes the available data, it does not describe the relationship between a response and an explanatory variable. One way to see this is that the numbers in the table are the same regardless of which variable is on the horizontal axis.
Table 4.10: Counts of cases in the NHANES data frame with work status on the horizontal axis.
| Working | Looking | NotWorking | |
|---|---|---|---|
| Excellent | 545 | 26 | 237 |
| Vgood | 1466 | 90 | 714 |
| Good | 1639 | 127 | 993 |
| Fair | 463 | 41 | 459 |
| Poor | 39 | 2 | 142 |
Table 4.11: Counts of cases in the NHANES data frame with health on the horizontal axis.
| Excellent | Vgood | Good | Fair | Poor | |
|---|---|---|---|---|---|
| Working | 545 | 1466 | 1639 | 463 | 39 |
| Looking | 26 | 90 | 127 | 41 | 2 |
| NotWorking | 237 | 714 | 993 | 459 | 142 |
Survey data, like that in the NHANES data frame, is collected by sampling from the population. It often happens that some kinds of people are more likely to be included in a sample than others. For instance, common sense suggests that people in poor health might be reluctant to participate in a survey. If this were true, then the data in NHANES would underrepresent proportion of the population that is in poor health.
Consider these two different relationships:
Work ~ HealthGenHealthGen ~ Work
The questions here concern whether a description of a relationship can be faithful to the true situation in the entire population even if the data under-represent a group (such as people in poor health).
For each of (a) and (b), say whether the summary of the relationship can be faithful to the truth despite the under-representation of people in poor health.
Now consider the tables of counts organized in the two different ways: one with health on the horizontal axis and one with working status on the horizontal axis. Can one of these tables be faithful to the true situation even when people in poor health are under-represented.
Problem 11: The graph shows the distribution of time-of-day when the NYC bus delays (described in (ref:cheetah-lose-saucer)) stratified by the reason given for the delay.
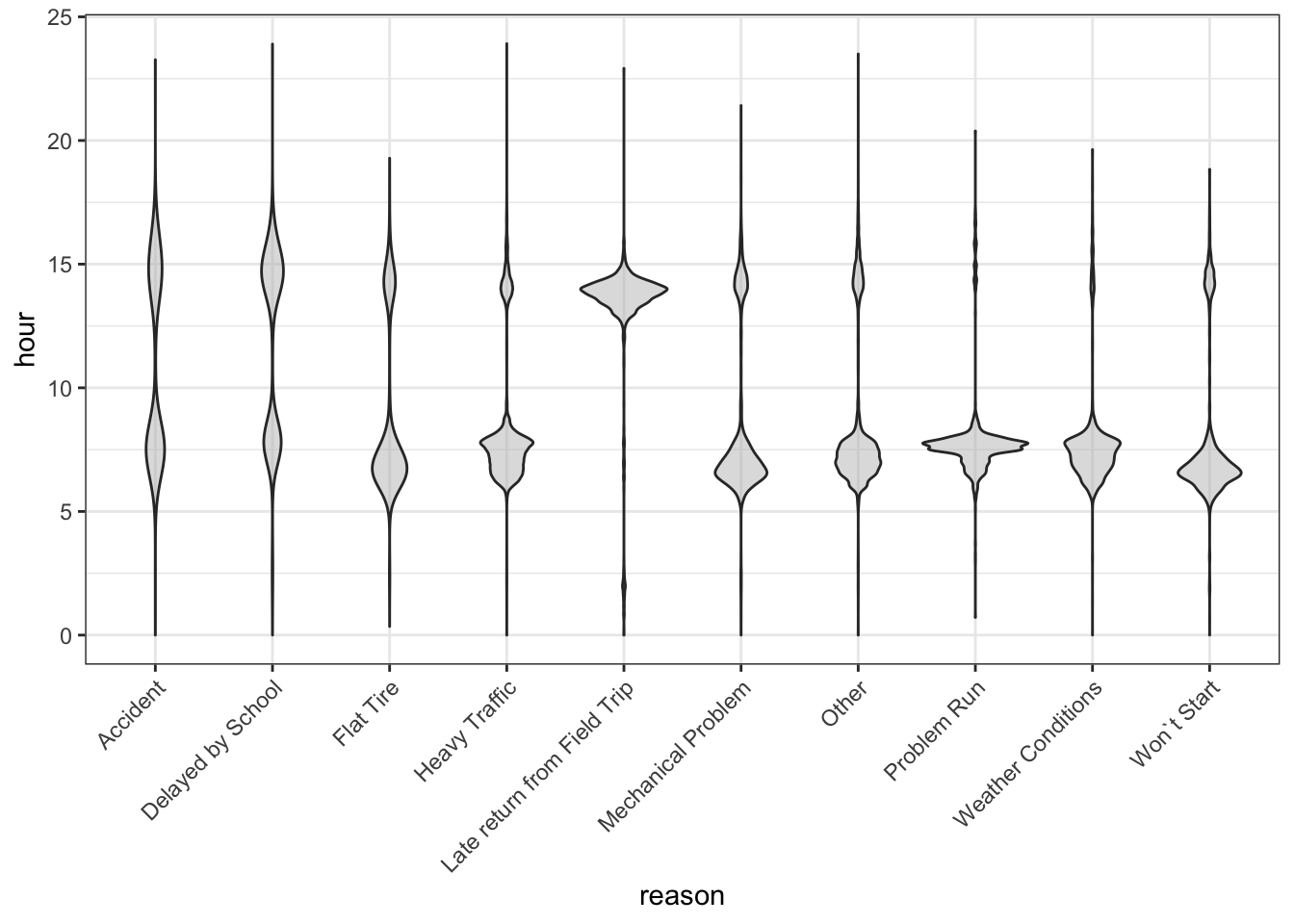
Is traffic worse in the morning or the afternoon? Give a plausible justification for your answer in terms of how schools function versus how businesses function.
Which category of reason for the delay is most common in the afternoon?
Are mechanical problems and the bus engine not starting most common in the morning or afternoon?
To judge from the violin plot, which reason is the most common for bus delays?
Problem 12: The violin plot shows gasoline consumption (in miles-per-gallon for city driving) stratified by the number of passenger doors for the SDSdata::MPG data frame. (For many vehicles, the values are missing. These are marked “NA”.)
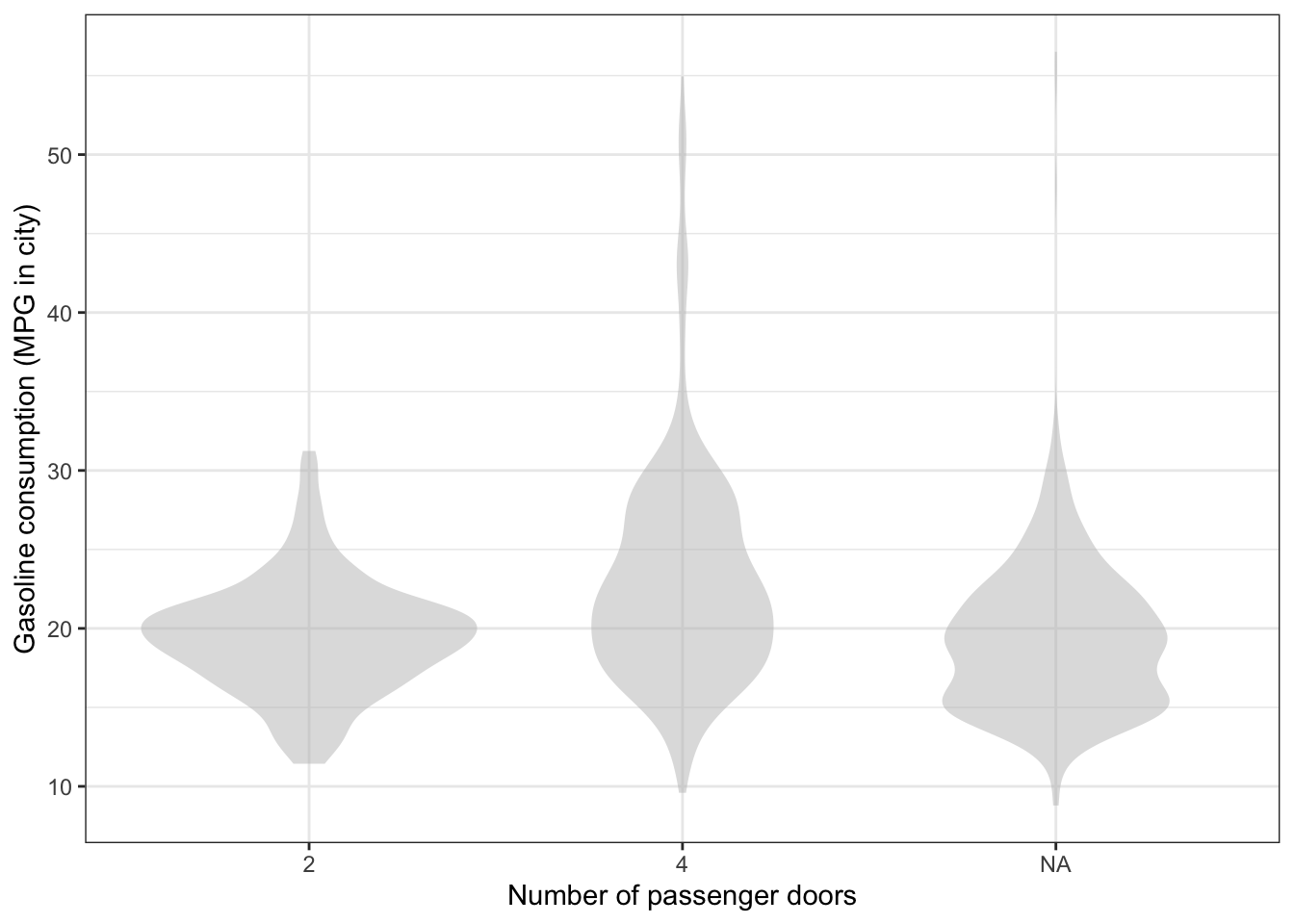
Sketch in 95% prediction intervals for gasoline consumption stratified by the number of passenger doors.
Which category – 2 doors, 4 doors, or NA – has the largest number of vehicles?
The unit of observation in the MPG data frame is “a model of car”. There are 1154 different models included in MPG, thus 1154 rows. Imagine that you had another data frame with the same variables as MPG, but where the unit of observation were “a registered vehicle”. There are roughly 290 million vehicles registered in the US, so the data frame would have 290 million rows. Also imagine (probably contrary to reality at present) that car models with relatively high miles per gallon are much more popular than cars with low miles per gallon.
- Sketch out what the
MPG ~ doorsviolins would look like for the 290 million-row table.
Problem 13: The graph shows the activity level of people at a YMCA using a set of “smart” exercise machines that keep track of each person’s usage. The values are made available via a phone app to enable each person to see his or her ranking.
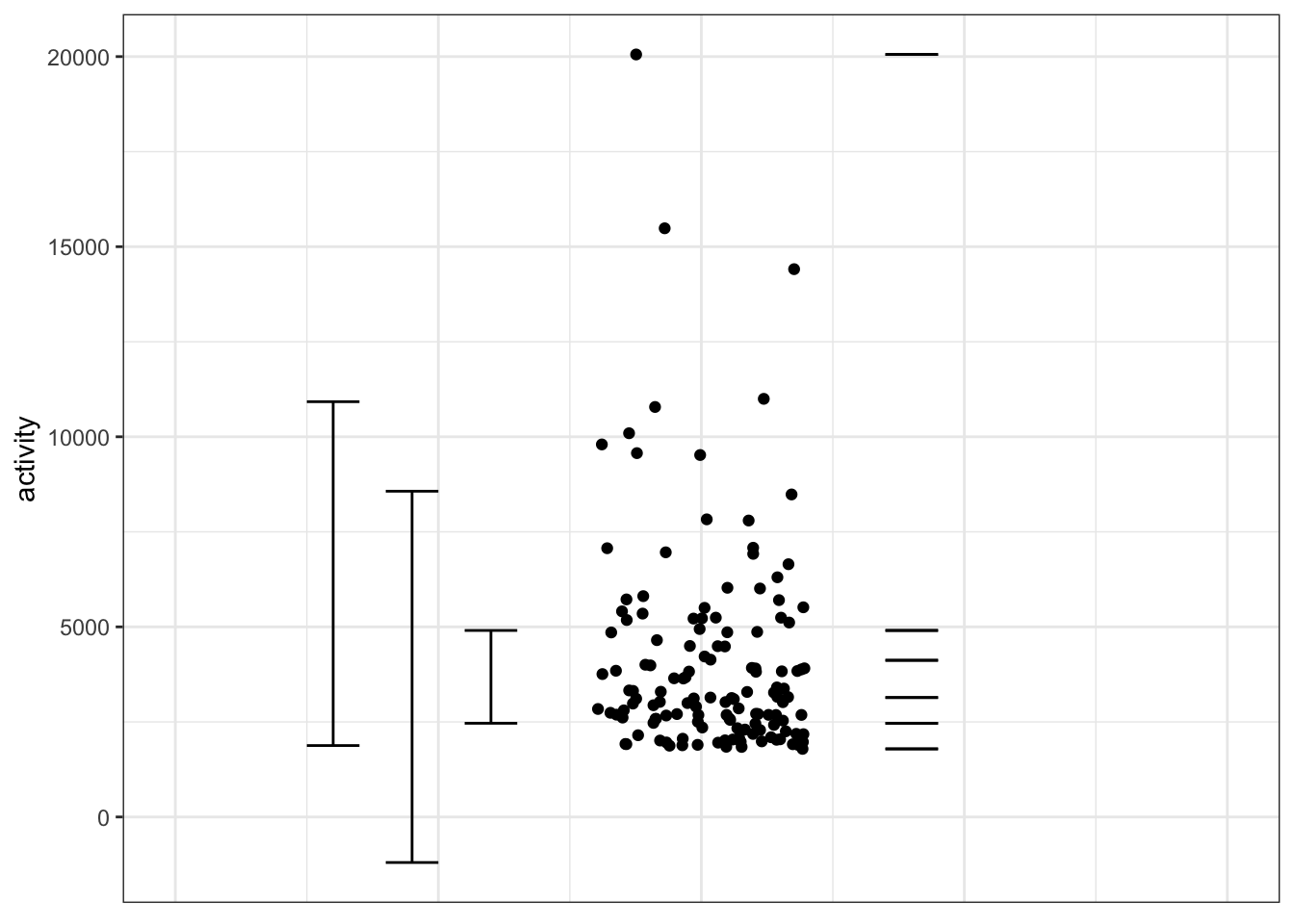
The mean activity level is 4121, the median is 3141, the largest single value is 20,056, and the smallest single value is 1791. There are 135 people for whom data is recorded.
- Six different point summaries are shown as black dots: the mean, median, 25% quantile, 75% quantile, min, max. Label each dot by the name of the statistic.
- Three interval summaries are shown: the 95% coverage interval, the 50% coverage interval, and the outlier guidelines. Label each interval by its name.
- Suppose the person at 20,056, in a bout of energy-drink fueled exercise mania, brought her score to 50,026.
- How would the median activity level change?
- How would the mean activity change?
- The outlier guidelines suggest that some of the data points be considered as possible outliers. What is it about the bulk of data points that suggests that all of the data points may be genuine? Translate this, if you can, into human terms.
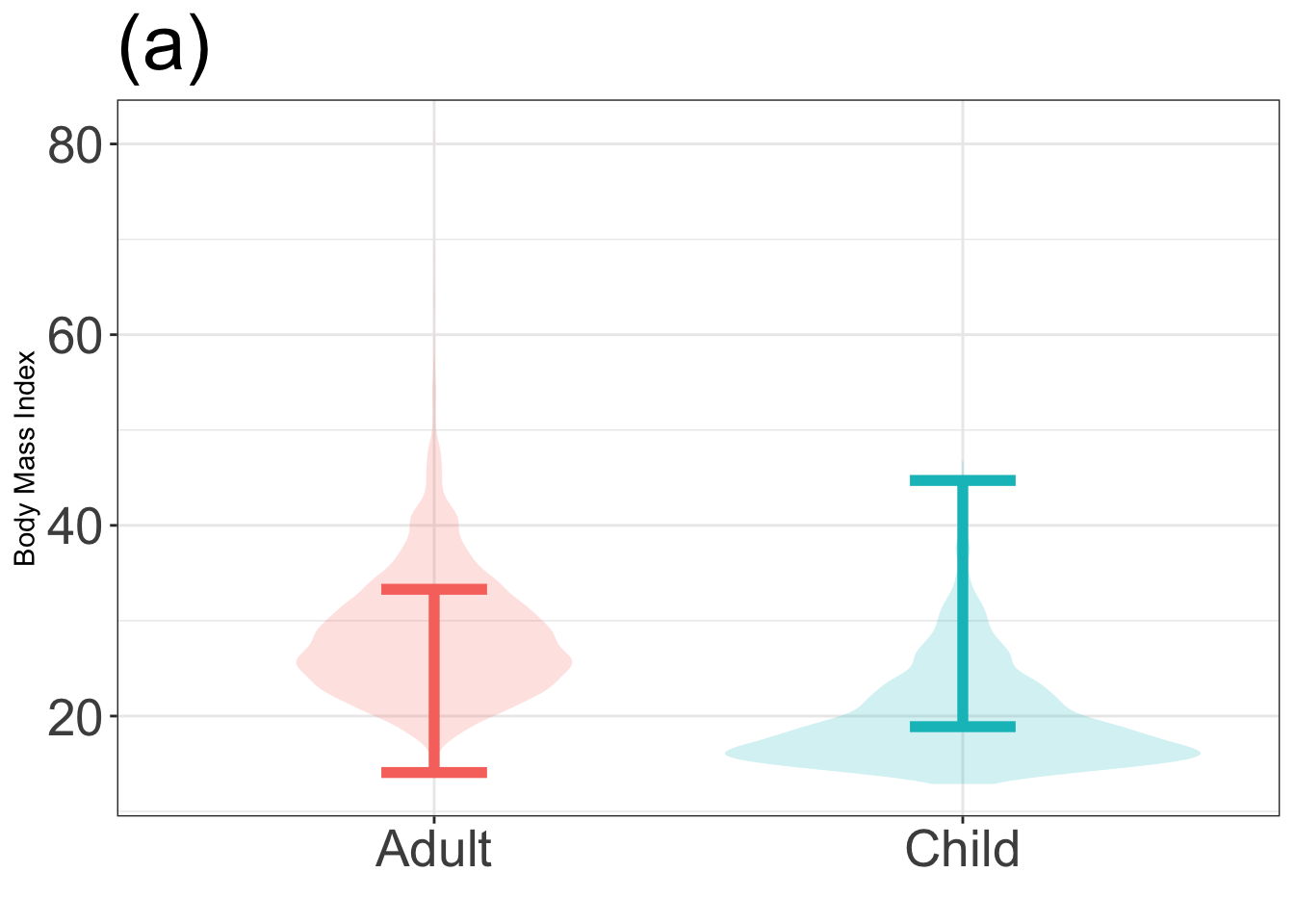
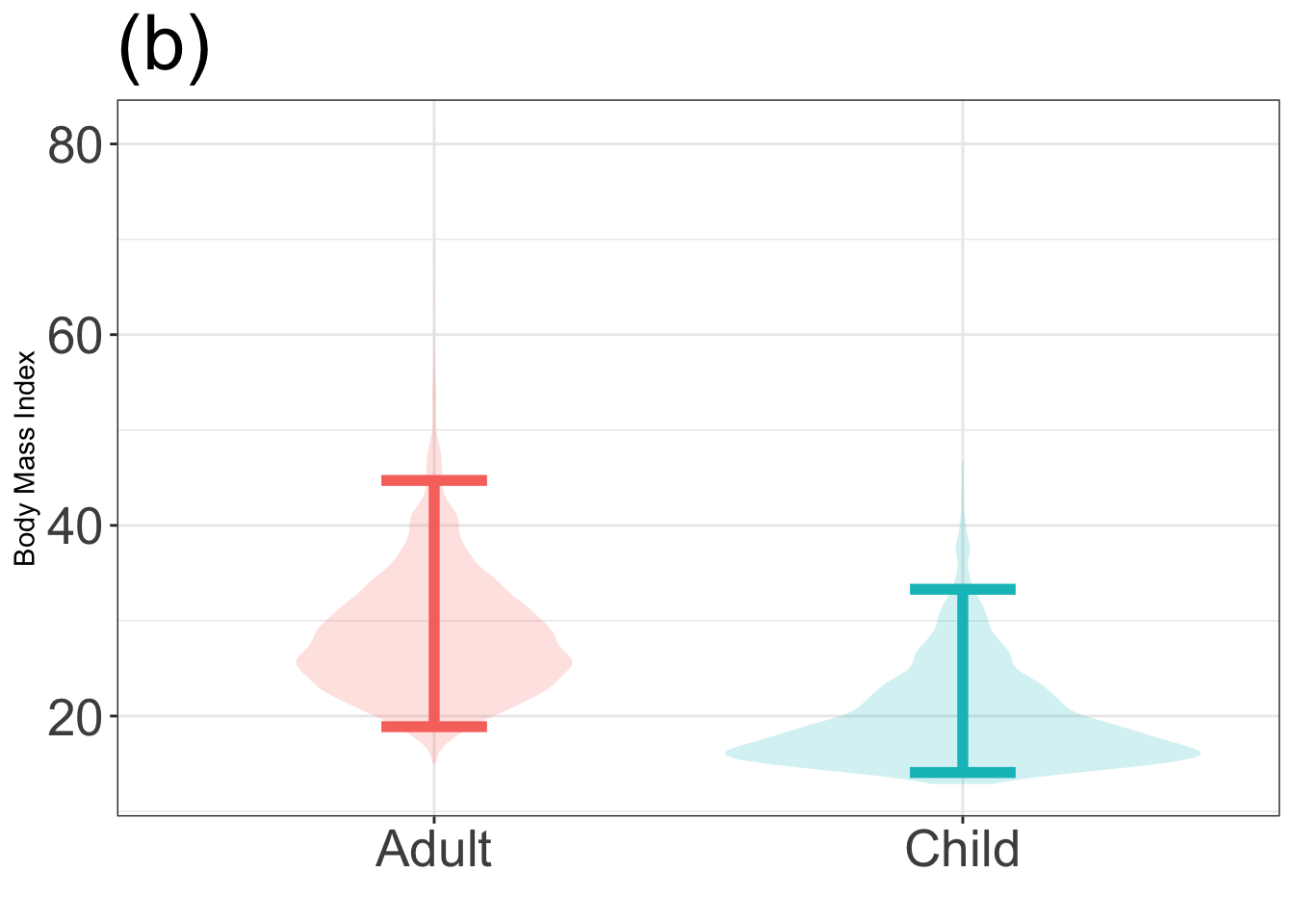
Problem 14: The graphs below show a violin plot of body mass index (BMI) for adults and children. One of the graphs shows a correct 95% coverage interval on BMI, the other does not.
Identify the incorrect graph and say what feature of the graph led to your answer.
Problem 15: The three graphs below show the distribution of weights broken down by sex. The violin layer is the same in each graph. Each graph has a coverage interval at one of these levels: 25% 50%, 80%, 95%. Which graph has which coverage interval? Which of the listed coverage intervals is not shown in any graph?
![]()
![]()
![]()
Problem 16: DataCamp.com is a company offering online courses, often developed by university faculty. They pay royalties to their authors for the use of their materials. In a 2019 letter, DataCamp offered this summary of the royalties it paid individual authors:
- Average: $4,094
- 25% Quartile: $1,221
- 50% Quartile: $2,519
- 75% Quartile: $3,980
- It is indeed possible for the mean to be higher than the 75% quantile. Explain how this might happen.
Sketch out a violin density plot consistent with the numerical summaries.
Explain what it is about your sketch that leads you to think it is consistent with the numerical summaries.
Problem 17: DRAFT Examples where it’s clear that p(A|B) need not be the same as p(B|A) ….
Jo Hardin
One way I try to communicate to my students what a p-value is not is by giving them the following two conditional probability statements to estimate:
P(pregnant given you have a uterus)
P(you have a uterus given that you are pregnant)
Andrew Ross
One that I like comes from the Peck/Olsen/Devore book (I think): Pr( you are over 6 feet tall given that you are in the NBA) versus Pr(you are in the NBA given that you are over 6 ft tall)
I also like this one (perhaps in the same book?) Pr( you are a US citizen, given that you are a member of Congress) versus Pr(you are a member of Congress, given that you are a US citizen)
though both of these are fairly US-centric. The latter one could be easily adapted for other countries, but the first one not as much.
Mine Çetinkaya-Rundel
I’ve used the following before that I think got the point across: P(my car is on fire | something is wrong with my car) P(something is wrong with my car | my car is on fire) Best, Mine
Albyn Jones
P(you can read | you have a PhD in statistics) vs P(you have a PhD in statistics | you can read) (:-)
- two examples that need to be broken into separate problems: fish-ride-book
- from John Snow: horse-light-plant
References
Kahn, Michael. 2005. “An Exhalent Problem for Teaching Statistics.” Journal of Statistics Education 13 (2). Taylor & Francis: null. https://doi.org/10.1080/10691898.2005.11910559.
Vanderpump, M P, and et al. 1995. “The Incidence of Thyroid Disorders in the Community: A Twenty-Year Follow-up of the Whickham Survey.” Clinical Endocrinology 43: 55–69.