- 1
-
summarize()reduces many rows to a single row. - 2
-
Calculate the mean of
heightand name the corresponding variable in the outputmodval. - 3
-
Break down the calculation in (2) group by group.
| sex | modval |
|---|---|
| M | 69.23 |
| F | 64.11 |
Lesson sec-variation listed three foundations for statistical thinking and provided instruction on the first one:
In this Lesson, we will take on two and three:
In business, accounting keeps track of money and value: assets, receipts, expenditures, etc. Likewise, in statistics, accounting for variation is the process of keeping track of variation. At its most basic, accounting for variation splits a variable into components: those parts which can be attributed to one or more other variables and the remaining (or residual ) which cannot be so attributed.
The variable being split up is called the “response variable.” The human modeler chooses a response variable, depending on her purpose for undertaking the work. The modeler also chooses explanatory variables that may account for some of the variability in the response variable. There is almost always something left over, variation that cannot be attributed to the explanatory variables. This left-over part is called the “residual.”
To illustrate, we return to a historical statistical landmark, the data collected in the 1880s by Francis Galton on the heights of parents and their full-grown children. In that era, there was much excitement, uncertainty, and controversy about Charles Darwin’s theory of evolution.
Everyone knows that height varies from person to person. How much variation in height is there? We quantify variation using the variance. var() will do the calculation. The units of the output will be in square-inches, since height itself is measured in inches.
var(height) has units of “square-inches” when the variable height is measured in inches.price is 144 square inches. What is the standard deviation of price? (Make sure to include the units!)height includes the two values 57 inches and 54 inches. The difference between them is 3 inches. The square of this difference is 9 square-inches. The variance is the average of all the different pairs of values.Galton’s overall project was to quantify the heritability of traits (such as height) from parents to offspring. Darwin had famously measured the beaks of finches on the Galapagos Islands. Galton, in London, worked with the most readily available local species: humans. Height is easy and socially acceptable to measure, a good candidate for data collection.
Galton sought to divide the height variation in the children into two parts: that which could be attributed to the parents and that which remained unaccounted for, which we call the “residual.” We will start with a mathematically more straightforward project: dividing the variation in the children’s heights into that part associated with the child’s sex and the residual.
Active R chunk lst-galton-mean shows how to calculate the average height for each sex using the techniques from Lesson sec-wrangling. The line numbers in the code listing explain each of the components of the command.
summarize() reduces many rows to a single row.
height and name the corresponding variable in the output modval.
| sex | modval |
|---|---|
| M | 69.23 |
| F | 64.11 |
To see the results of the command, run it!
Note that the output has one row for each sex. As always, the output from summarize is set by the arguments to the function. Here, there will be two variables in the output: sex and the mean height for each sex, which we’re calling modval, short for model value.
This simple report indicates that the sexes differ, on average, by about 5 inches in height. But this report offers no insight into how much of the person-to-person variation in height is attributable to sex. For that, we need to look at the group averages in the context of the variation of individuals. That is, instead of computing the model value for each sex, we will compute it for each specimen using mutate(). This is simple, since all F specimens will have a model value of 64.1 inches, while the M specimens all have a model value of 69.2 inches. However, anticipating what will come later in this Lesson, we will do the calculation using mutate().
Note: To save space on the screen, Active R chunk lst-galton-mutate is written to show only a handful of the 898 rows that would otherwise be in the output.
Active R chunk lst-galton-mutate2 repeats the above calculation, but summarizes to show the variance of height and the variance of the model values.
The output shows that the variability in the model values of height, is about half the variability in the height itself. This is the the answer to (2) from the introduction to this Lesson; sex accounts for about half of the variation in height.
Item (3) in the introduction was about measuring what remains unexplained. This “unexplained” part of height is called the residual from the model values. The residual is easy to calculate. Active R chunk lst-galton-resid-var calculates the residuals from the simple model that accounts for height by sex.
It’s essential to note from the output of Active R chunk lst-galton-resid-var that the variance in the response variable (height) is exactly the sum of the the variance of the model values and the variance of the residuals. In other words, the variance in the response variable is perfectly split into two parts:
Active R chunk lst-galton-resid-var shows how to calculate the residual for each specimen: subtract the model value from the value of the response variable. Let’s look at the values of the residuals from the model of height versus sex.
Galton |>
mutate(modval = mean(height), .by = sex) |>
mutate(resid = height - modval) |>
point_plot(resid ~ 1, annot = "violin")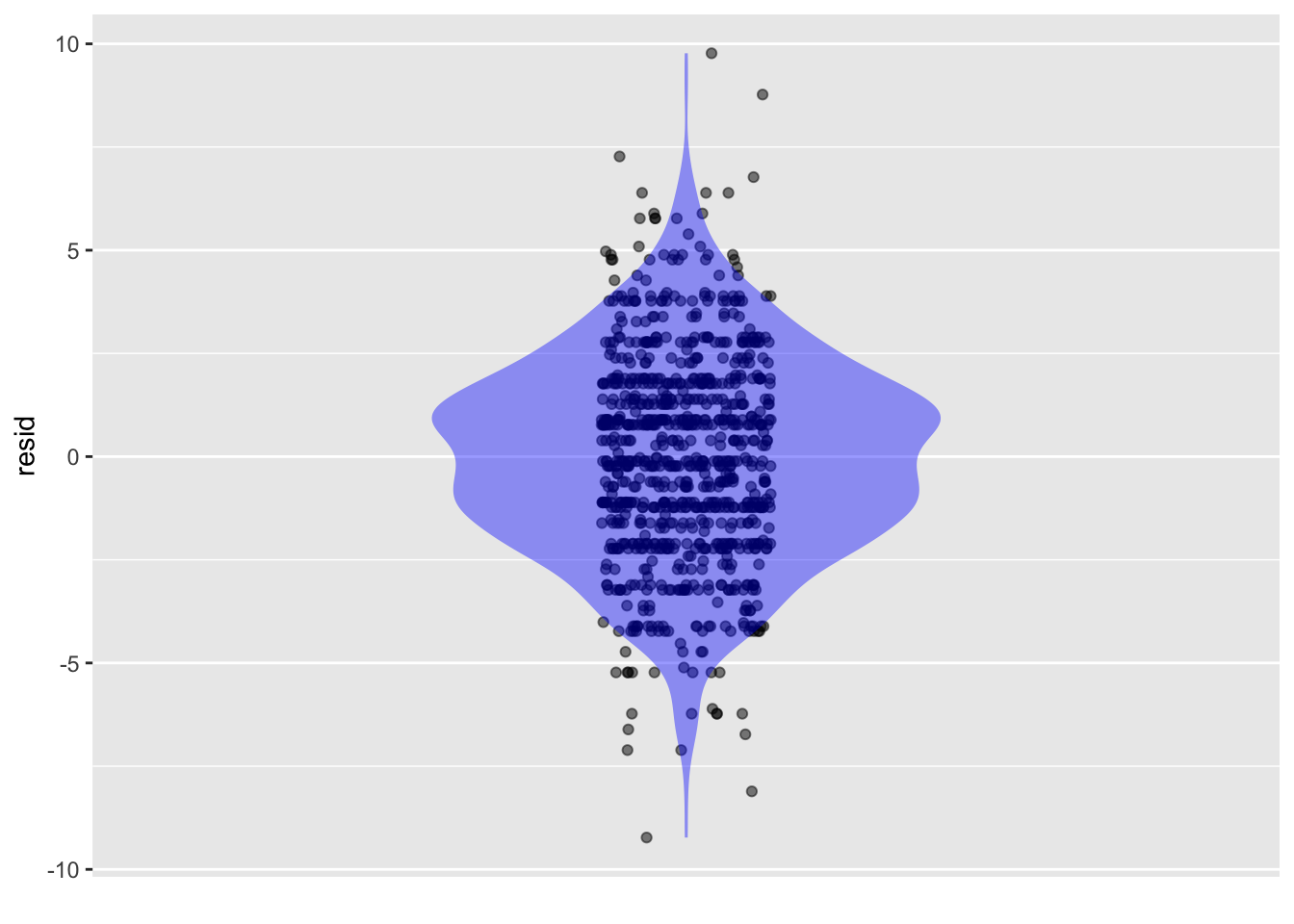
Which line of Active R chunk lst-resid-point-plot finds the residual for each of the specimens?
Some residuals are positive and some negative. Explain how a residual can be negative.
If the model value is larger than the response variable, the residual will be negative. Similarly, if the model value is less than the response variable, the residual is positive.
Since Lesson [-@sec--variation-and-distribution] we have used the variance as the prefered way to measure the amount of variation. The advantage of the variance is that it perfectly partitions variation in the response variable into two parts: (i) variation in the model values and (ii) variation in the residuals.
The following chunk demonstrates the perfect partitioning: Run it!
mage) from the Births2022 data frame by the mother’s education level (meduc). Is the variation in mage perfectly partitioned between the model values and the residuals?In addition to replacing Galton with Births2022, you will need to replace the explanatory variable sex with meduc. Similarly, replace height with mage.
sd()) to measure variation. Modify the above chunk, replacing var() with sd(). Looking at the results, does the standard deviation perfectly partition the response variable into model values and residuals?The previous section used the categorical variable sex as the explanatory variable. Galton’s interest, however, was in the relationship between children’s and parents’ height.
sex is a categorical explanatory variable. Using mutate(..., .by = sex) is a good method of handling categorical explanatory variables. However, this does not work for quantitative explanatory variables. The reason is that .by translates a quantitative variable into a categorical one, with a result for each unique quantitative value. It’s trivial to substitute the height of the mother or father in place of sex in the method introduced in the previous section. However, as we shall see, the results are not satisfactory. Galton’s key discovery was the proper method for relating two quantitative variables such as height and mother.
First, let’s try simply substituting in mother as the explanatory variable and using mean() to create the model values. Then, use point_plot() to show the model values as a function of mother.
The last line of Active R chunk lst-galton-by-mother connects adjacent points with lines. It’s hard to see any pattern in the model values.
It is common sense that the model linking mothers’ heights to children’s height should be smooth, not the jagged pattern seen in Active R chunk lst-galton-by-mother. The source of the jaggedness is the use of .by = mother in mutate(modval = mean(height), .by = mother). There is nothing in .by = mother to enforce the idea that the model value for mid-height mothers should be in-between the model values for short and for tall mothers.
The solution to the problem of jagged model values is to avoid the absolute splitting into non-overlapping groups by mother’s height. Instead, we want to find a smooth relationship. Galton invented the method for accomplishing this. A modern form of his method is provided by the model_values() function., which we shall use to construct Model3.
Notice that the .by = mother step has been entirely removed. Notice also that model_values() uses the same kind of tilde expression as we have employed when plotting. The response variable is listed on the left of the  , the explanatory variable on the right side. In other words, we are modeling the child’s
, the explanatory variable on the right side. In other words, we are modeling the child’s height as a function of mother’s height.
As always, modeling splits the variance of the response variable into two parts, one associated with the explanatory variable and the other holding what’s left over: the residual. Here’s the split for Model3 which uses mother as an explanatory variable:
The mother’s height doesn’t account for much of the variation in the children’s heights.
The model_values() approach to modeling works for both quantitative and categorical explanatory variables. For convenience, you can annotate point_plot() to show the model along with the raw data. Try it:
The model value for females is about 64 inches. The tallest female is 71 inches. This makes the largest residual 71 - 64 = 5 inches.
height ~ mother. Find a point that has a large negative residual from this model.The models we work with in these Lessons always have exactly one response variable. But models can have any number of explanatory variables.
Whatever the number of explanatory variables and however many levels a categorical explanatory variable has the model splits the variance of the response into two complementary pieces: the variance accounted for by the explanatory variables and the part not accounted for, that is, the residual variance.
To illustrate, here is a sequence of models of height with different numbers of explanatory variables.
| Number of explanatory variables | tilde expression | var(resid) |
|---|---|---|
| 0 | height ~ 1 |
|
| 1 | height ~ sex |
|
| 2 | height ~ sex + mother |
|
| 3 | height ~ sex + mother + father |
Calculating the residuals and their variance for any of these four models can be accomplished with
Galton |>
mutate(modval =
model_values(
..tilde.expression.here.
),
resid = height - modval) |>
summarize(
var(height), var(modval), var(resid)
)Three explanatory variables
Two explanatory variables
One explanatory variable
Zero explanatory variables
Galton |>
mutate(modval = model_values(height ~ 1),
resid = height - modval) |>
summarize(var(height), var(modval), var(resid))| var(height) | var(modval) | var(resid) |
|---|---|---|
| 12.8373 | 0 | 12.8373 |
When selecting explanatory variables, comparing two or more different models sharing the same response variable is often helpful: a simple model and a model that adds one or more explanatory variables to the simple model. The model with no explanatory variables, is always the simplest possible model. For example, in sec-multiple-vars1, the model height ~ 1 is the simplest. Compared to the simplest model, the model height ~ sex has one additional explanatory variable, sex. Similarly, height ~ sex + mother has one additional explanatory variable compared to height ~ sex, and height ~ sex + mother + father adds in still another explanatory variable.
The simpler model is said to be “nested in” the more extensive model, analogous to a series of Matroshka dolls. A simple measure of how much of the response variance is accounted for by the explanatory variables is the ratio of the variance of the model values divided by the variance of the response variable itself. This ratio is called “R2”, pronounced “R-squared.”

For instance, R^2 for the model height ~ sex + mother is \[\text{R}^2 = \frac{7.21}{12.84} = 0.56\] By comparison, R^2 for the simpler model, height ~ sex, is slightly smaller:
\[\text{R}^2 = \frac{6.55}{12.84} = 0.51\] For all models, \(0 \leq\) R2 \(\leq 1\). It is tempting to believe that the “best” model in a set of nested models is the one with the highest R2, but statistical thinkers understand that “best” ought to depend on the purpose for which the model is being built. This matter will be a major theme in the remaining Lessons.
Activity 9.1 The data frame LSTbook::Gilbert records 1641 shifts at a VA hospital. (For the story behind the data, give the command ?Gilbert.) Whether or not a patient died during a shift is indicated by the variable death. The variable gilbert marks whether or not nurse Kristen Gilbert was on duty during the shift.
A. Are the variables numerical or categorical?
B. The data were used as evidence during Gilbert’s trial for murder. The data can be reduced to a compact form by data wrangling:
LSTbook::Gilbert |>
summarize(count = n(), .by = c(death, gilbert))| death | gilbert | count |
|---|---|---|
| no | not | 1027 |
| yes | not | 357 |
| no | on_duty | 157 |
| yes | on_duty | 100 |
Calculate the proportion of times a death occurred when Gilbert was on duty, and the proportion of time when Gilbert was not on duty. Does the shift evidence support the claim that Gilbert was a contributing factor to the deaths.
C. In the Lessons, we will mainly use regression modeling rather than wrangling as a data-reduction technique. In the trial, the relevant question was whether Gilbert was a factor in the deaths. Express this question as a tilde expression involving the variables death and gilbert.
D. The response variable in your tilde expression from (C) is categorical. Regression modeling requires a numerical response variable. Use mutate() and zero_one() to transform the variable death from categorical form to a numerical form that has a value 1 when Gilbert was on duty and 0 otherwise. This will become the response variable for the regression: death ~ gilbert.
E. Carry out the regression using model_train(). Look at the coefficients from the fitted model with conf_interval(); these are in .coef column. Explain how the coefficients correspond to the proportions you calculated in (B).
Activity 9.4
DRAFT: Show that the sum of squares and mean square for modeling using the median is larger than for the mean.
Activity 9.6