Chapter 9 Collaboration and Reproducibility with Git
Data analysis is often collaborative. Sometimes this collaboration involves a team of programmers simultaneously contributing code to the same project, even the same document. In other cases, the collaboration may be asynchronous or an analyst may decide to continue work left behind by someone else. Each of these cases is simplified if the users adopt a workflow that includes tools designed to facilitate version control (sometimes called “source code management”).
As you read this chapter, you will be introduced to one such tool–Git–and introduced to a basic implementation of a collaborative workflow that includes version control. Additionally, a valuable byproduct of such a workflow is the ability to preserve and access the entire history of a document (or project) evolution.
9.1 Version Control
As mentioned above, version control is a system that records changes to a file or a set of files in order to keep track and possibly revert to or modify those changes over time. More specifically, it allows you to:
- record the entire history of each file in a project;
- manage contributions of multiple collaborators;
- revisit history of the project and revert back to a specific version of any file if needed;
- draft changes without modifying the main file until you feel ready to commit to them.
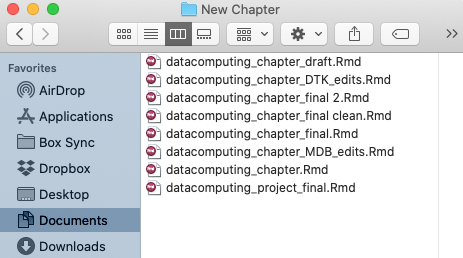
As projects become more complex or the number of contributors increases, these features become increasingly valuable. Users unfamiliar with proper tools designed to manage version control sometimes recognize a need and attempt an inefficient solutions like emailing documents to one another (or themselves) or perhaps saving many copies of the same document in order to preserve a crude history of changes. General purpose cloud storage (e.g., Google Drive, Dropbox) offer a slight improvement, but are less effective for our purposes than tools specifically designed for programming applications.
Figure 9.1: An inefficient attempt to implement version control by file name.
Rather than save many independent copies of each file, many version control software tools simply track incremental changes to the files under version control. Storing a complete record of changes from one version to the next is far more efficient than saving many copies of whole documents for which a majority of the content may be unchanged from one iteration to the next. Moreover, with a complete record of every incremental change, it’s just as easy to piece together the current state of a document or to rebuild a previous the state of a document at an earlier point recorded in it’s development lifecycle. For this reason, some have quipped that including version control in your workflow is like having a time machine that can revisit any point in the history of your documents! (unfortunately, the ‘time machine’ is not able to jump forward to your completed project, so we continue…)
9.1.1 Collaboration
To be clear, while Git and other version control tools facilitate collaboration among multiple users, it is equally valuable for projects created and maintained by a single user. In fact, for many users “self-collaboration” is far more common. For example, an R user may want to work on a project from more than one computer such as an RStudio Server as well as a desktop version of RStudio on a personal computer. A different type for self-collaboration is the case of a discontinued or completed project to which the user returns after a long time away (e.g., many months or years). Having the entire history and evolution of the project available is a convenient way to re-establish momentum or revisit an idea that was previously abandoned but seems more promising with the benefit of new perspective or resources. Another important–yet hopefully infrequent–reason for version control as a single user is as an insurance policy if your primary computer is damaged, lost, or stolen.
9.1.2 Reproducibility
An advisory committee to the U.S. National Science Foundation (NSF) describes reproducibility in the sciences as, “the ability of a researcher to duplicate the results of a prior study using the same materials as were used by the original investigator. That is, a second researcher might use the same raw data to build the same analysis files and implement the same statistical analysis in an attempt to yield the same results…. Reproducibility is a minimum necessary condition for a finding to be believable and informative.”1 K. Bollen, J. T. Cacioppo, R. Kaplan, J. Krosnick, & J. L. Olds. Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science (National Science Foundation, Arlington, VA, 2015). Much has been written on the subject of reproducibility in the sciences, but our interest here is aligned to computational aspects of reproducibility.
Computational reproducibility generally provides an opportunity to demonstrate the accuracy of your code & methods according to some stated purpose, and allows others the opportunity to make use of your work whether to directly replicate some part of it or to extend and modify your work for a new purpose.2 See http://ropensci.github.io/reproducibility-guide/ We bolster the integrity of our work when we strive to preserve a complete and transparent record of all actions in a project from raw source data through final product.
Two important tools for computational reproducibility are very much at the heart of our interests in this book: literate programming and version control. Literate programming allows programming code associated with an analysis to be integrated with the narrative. RMarkdown is well-designed for this purpose such that the entire document and analysis could be knit independently by another user if needed.
Version control is another an important part of a reproducible workflow because it preserves a complete record of work as a matter of transparency such that another person (or your future self) can see every decision and detail of analysis from source data through final product. If one or more files are inadvertantly changed at some point during the project resulting in a loss of data, version control tools can restore them to the proper state. Unfortunately, such issues are not uncommon especially if one or more users are likely to view data sources using spreadsheet software (e.g., Excel) in which a stray keystroke could easily overwrite one or more cells of data.
Note that it is indeed possible to construct a completely reproducible analysis without version control, and it is also possible to employ version control for work that is not reproducible. The strength of the workflow advocated here is derived from the combination of reproducibility and version control principles.
9.2 Git and GitHub
Git is just one of several well-established software tools designed for version control. In Git, a repository, or Repo, is a group of documents subject to version control. A Repo is analogous to a folder at some directory location on your computer: everything in the folder can be tracked by Git including Rmd files, images, PDFs, R Notebooks, data sets, and much more.
GitHub is one of several web-based version control repository hosting service designed to augment Git. If you like, you can store a bunch of files in a repository (or Repo) on the GitHub remote servers and delete them from your computer entirely. You can replace the files with new versions or even edit some specific types of files right from the GitHub webpage. When you are ready to get them back, you could simply locate the files through your GitHub account and retrieve them.
More commonly, users establish a link between a file directory on their (local) computer and a Repo stored on the GitHub remote. You edit files on your computer and save your progress as you normally would, except now that you have established a link with Git(Hub) you can periodically update the Repo on the GitHub remote with the latest progress.
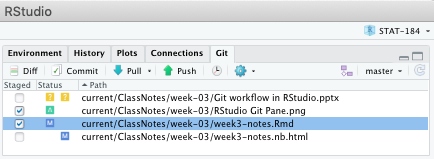
Importantly, adding version control with Git and GitHub doesn’t necessarily change much of your workflow. In fact, for many RStudio users who have properly configured RStudio and Git, the vast majority of your version control workflow can happen entirely within a convenient the RStudio interface. We’ll discuss specific details, but it’s sufficient to note the addition of the “Git” tab in the upper right pane of the RStudio window shown in Figure 9.2.
Figure 9.2: Git pane in RStudio.
9.2.1 Git & RStudio Configuration
As mentioned previously, with proper configuration a wide majority of your use of Git can happen entirely within the RStudio environment. (See Appendix for instructions).
If you change computers, or switch to an RStudio Server, you may need to repeat the configuation on that new system. Apart from that exception, you can generally think of this configuration as a one-time exercise (per computer).
9.2.2 Basic workflow
When beginning work on a project, you will first need to access or create an associated Git Repo. There are many ways to do so: an existing Repo might be provided to you by a collaborator (or teacher), you might initiate a new Repo from your GitHub profile, fork a public repo, etc.
Once you have access to an RStudio project associated with a Git Repo, it’s relatively simple to adopt some basic version control infrastructure into your workflow.
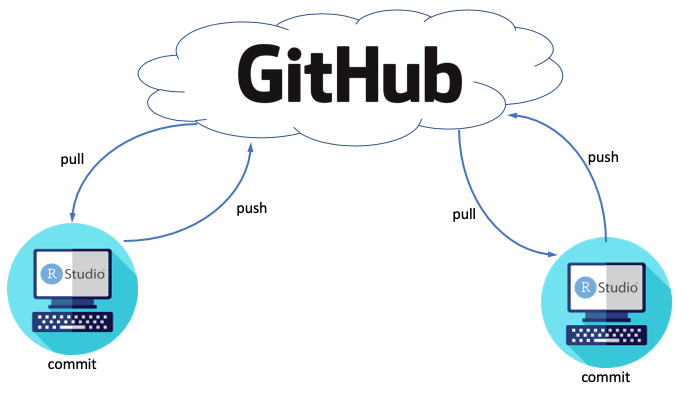
Figure 9.3: Basic version control workflow using RStudio and GitHub remote repository hosting for a single user

As shown in Figure 9.3, steps 2, 3, and 4 are the heart of our simple version control workflow. It’s recommended that you commit early and often as you make incremental progress in your project. The “commit” action effectively preserves a record of the entire Repo as it exists at that point in time. As you build a history of commits, you create a record of the evolution of your project. If at any point in the future, you wish to revisit an earlier state of the project your commits become the available stops for your version control “time machine” mentioned previously.
When making a commit to your Repo, you are required to add a message that is intended to describe the nature of the changes to your project. It’s important to write informative commit messages so you or your collaborators can decipher what has happened at each step in the evolution of the project.
The commit process occurs locally on your computer, so you still need to make them available on the GitHub remote. Before doing so, it’s essential that you verify that you are working with the most recent version of the files found on the GitHub remote. The “pull” action allows the user to query the GitHub remote and update their local files associated with the RStudio project. At this point you are now ready to “push” your commits to the GitHub remote for preservation.
The GitHub remote not only archives the work, but also serves as a hub for managing and distributing contributions among multiple collaborators or computers as shown in Figure 9.4.
Figure 9.4: Schematic of collaborative version control workflow using RStudio and GitHub remote repository hosting
9.2.3 Troubleshooting common issues
As with any new workflow, it will take a bit of practice to get used to things. We briefly acknowledge a few of the most common here: merge conflicts, files ‘missing’ from the Git tab in RStudio, and large files in the Repo.
9.2.3.1 Dealing with conflict
When multiple collaborators or computers are modifying files associated with a Git repo, there is a chance that two conflicting versions of the same file may need to be reconciled. The result is called a merge conflict. Basically, Git has noticed there are two conflicting versions of some part of a document in the Repo and–this is important–prompts a human user to decide how best to resolve the issue rather than naively overwriting one version or the other.
Many merge conflicts can be avoided altogether if you (and your collaborators) “pull” and “push” frequently. If a conflict is encountered, you will be presented with two alternative versions of the offending lines of code. In order to resolve the conflict, you’re welcome to adopt any combination of the two alternative code segments that you choose.
9.2.3.2 RStudio Git tab not tracking commits?
It’s a common mistake to forget to change from one RStudio Project to the next. If you forget, it may look like your changes aren’t tracked by Git. In reality, Git will still monitor changes… but it is monitoring them in association with the correct Repo for the file, so you won’t be able to make commits on those files until you change to the correct RStudio Project associated with the file.
9.2.3.3 Large files
GitHub is storing all sorts of things for its users and even doing so free of charge for academic users. Having said that, storage presumably costs them money and slows down performance, so GitHub is inclined to resist storing even moderately large files. You’ll be warned if you try and commit any single file that is more than 50 MB. There are sensible ways to work around this, but a common strategy is to tell Git to simply “ignore” the large file… that is, don’t include it in my snapshots and don’t archive it on the GitHub remote. Otherwise, GitHub helpfully provides guidance of their own for handling large files (https://help.github.com/en/github/managing-large-files).
9.3 Exercises
Coming soon…