11 Fitting features
For more than three centuries, there has been a standard calculus model of an everyday phenomenon: a hot object such as a cup of coffee cooling off to room temperature. The model, called Newton’s Law of Cooling, posits that the rate of cooling is proportional to the difference between the object’s temperature and the ambient temperature. The technology for measuring temperature (Figure fig-early-thermometers) was rudimentary in Newton’s era, raising the question of how Newton formulated a quantitative theory of cooling. (sec-low-order returns to this question.)
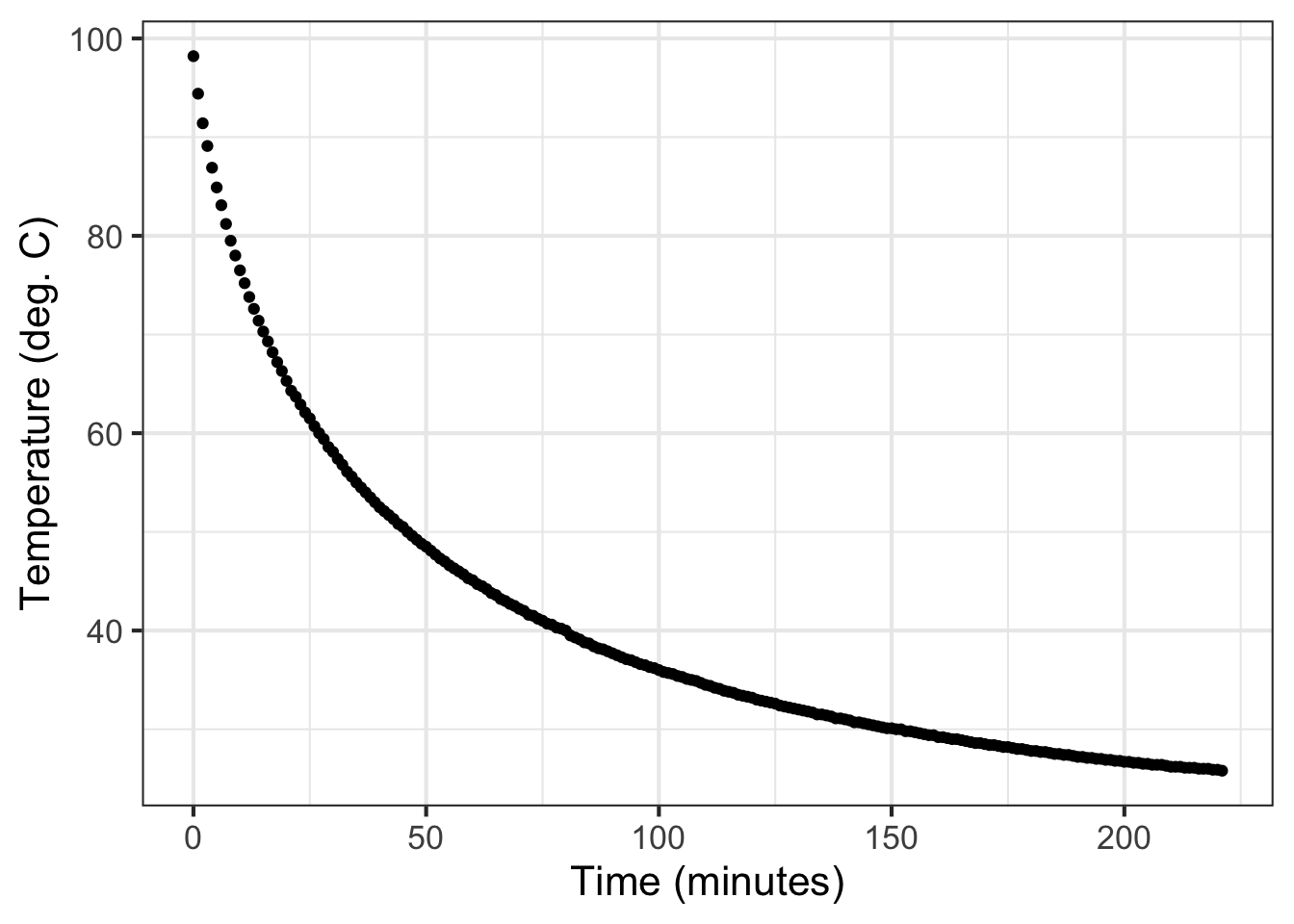
Using today’s much more precise technology, Prof. Stan Wagon of Macalester College investigated the accuracy of Newton’s “Law.” Figure fig-stans-data shows some of Wagon’s data from experiments with cooling water. He poured boiling water from a kettle into an empty room-temperature mug (26 degrees C) and measured the temperature of the water over the next few hours.
This chapter is about fitting, finding parameters and coefficients that will align a function with data such as in Figure fig-stans-data. This chapter covers the exponential, sinusoid, and gaussian functions. sec-magnitude considers the power-law and logarithm functions.
| Gaussian | Sinusoid | Exponential |
|---|---|---|
 |
 |
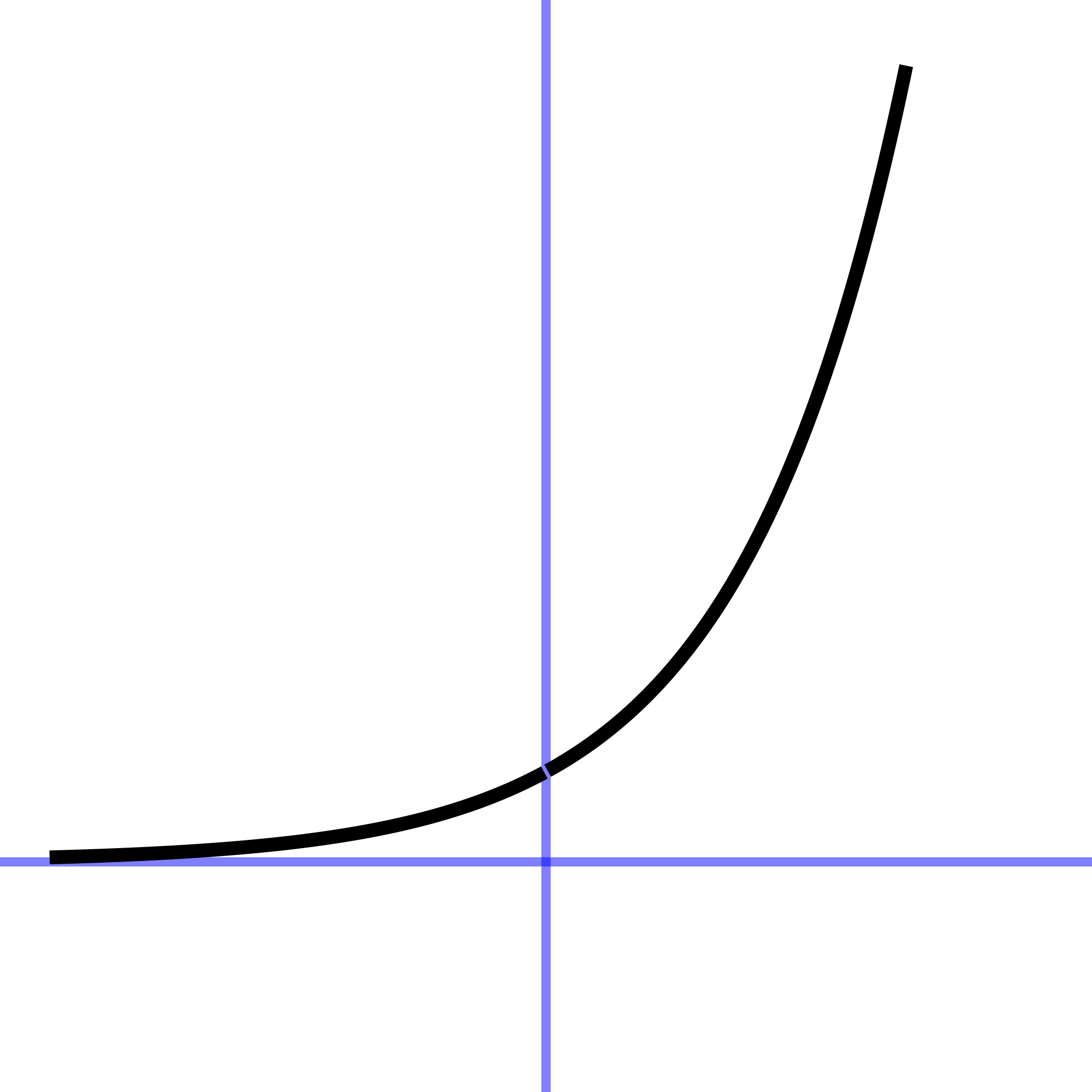 |
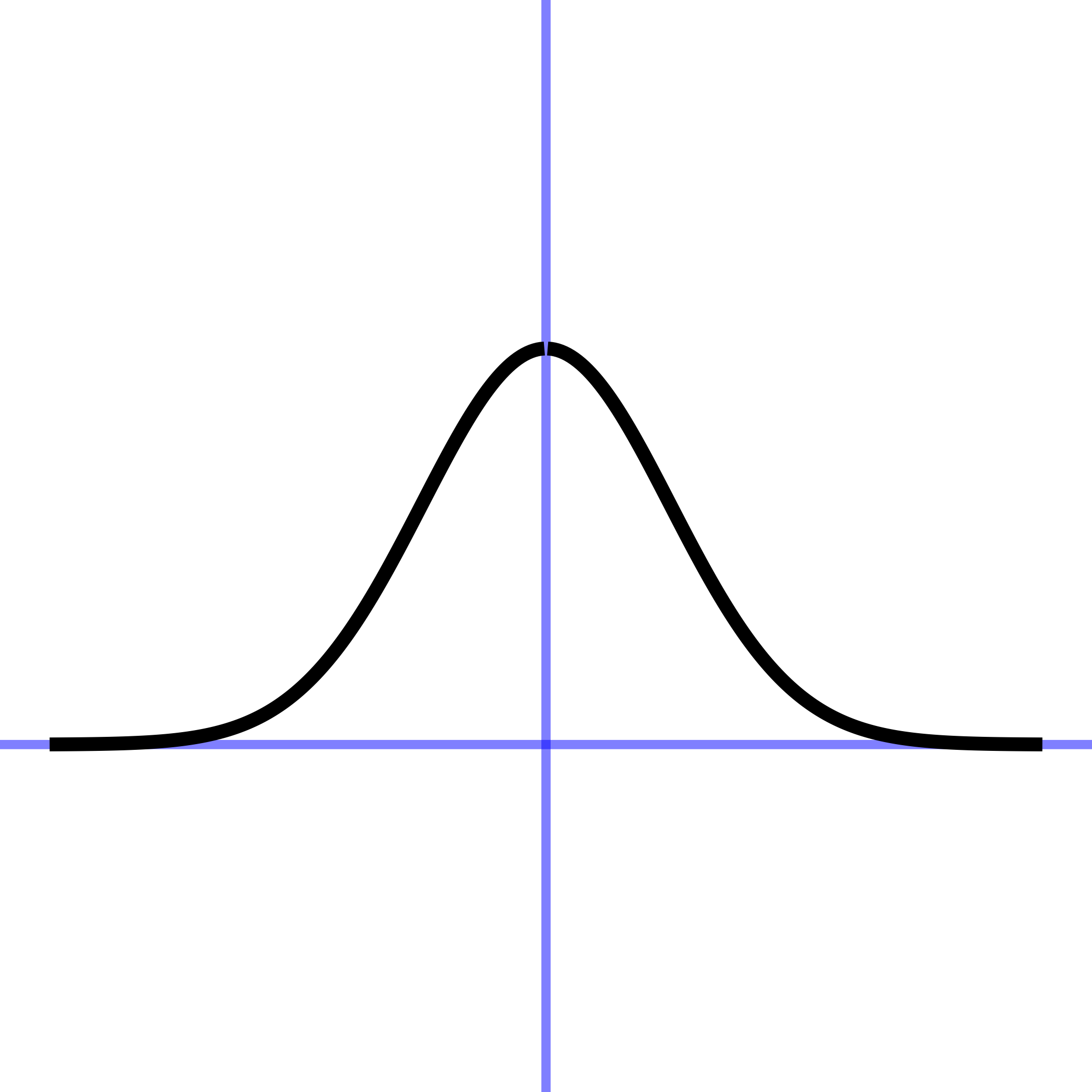
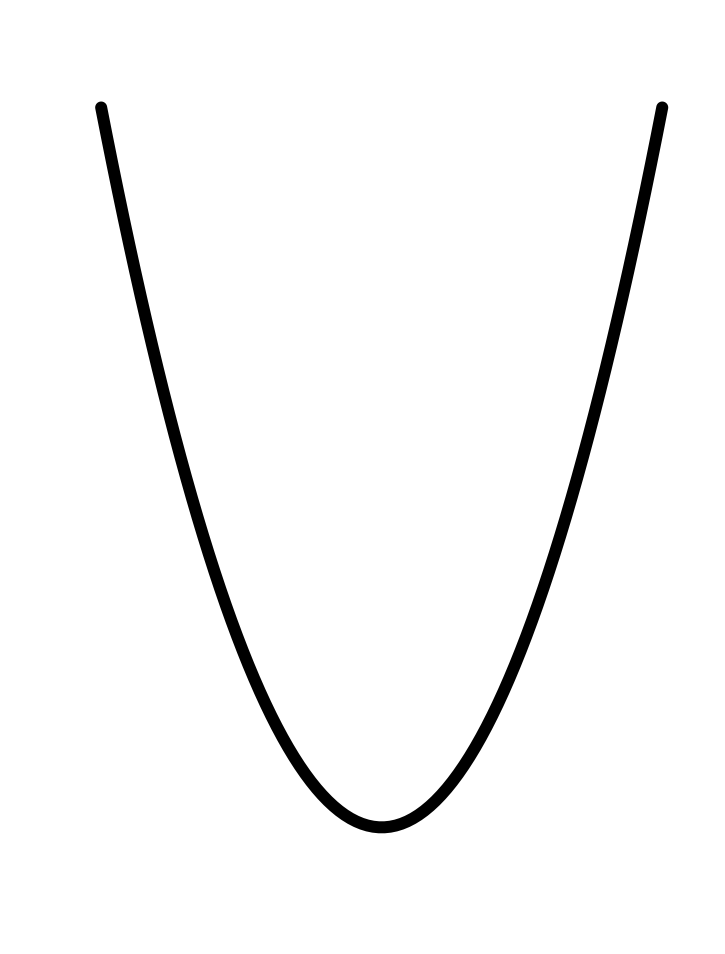
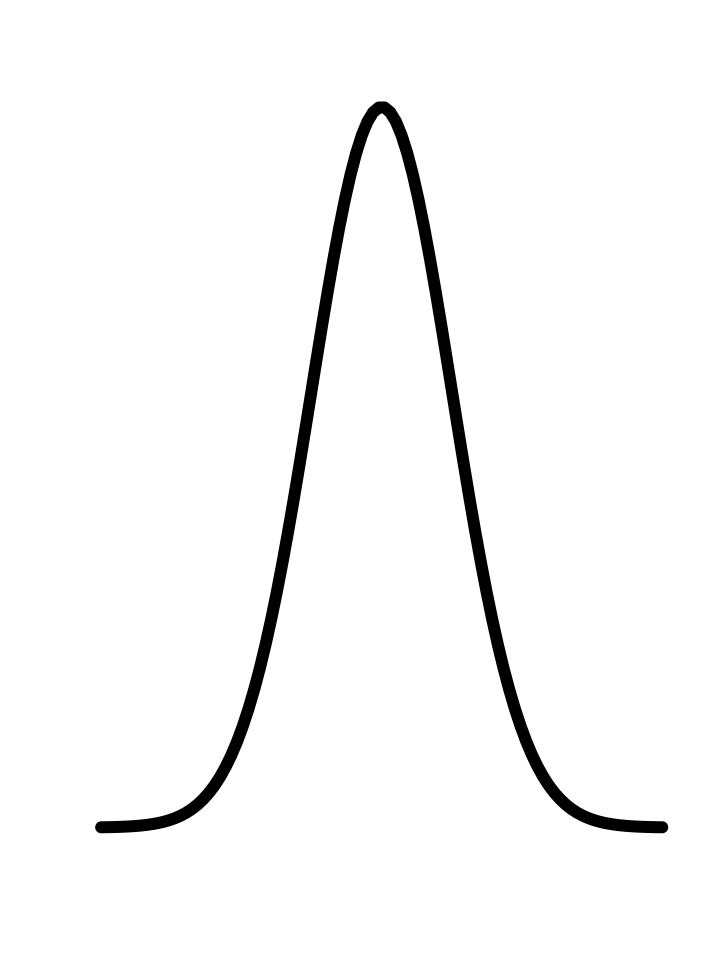
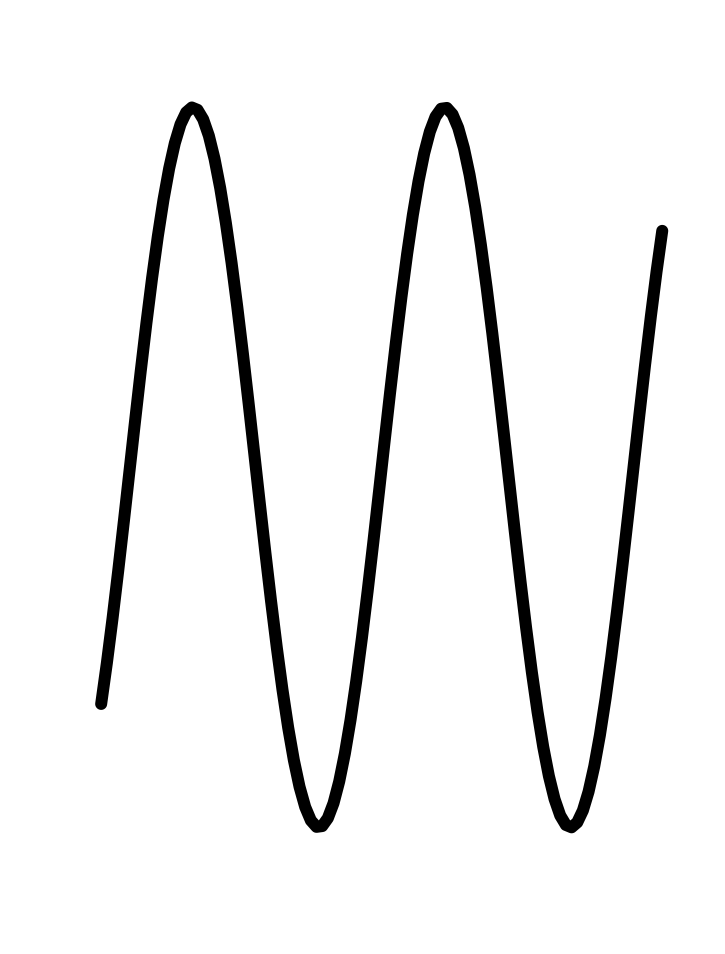
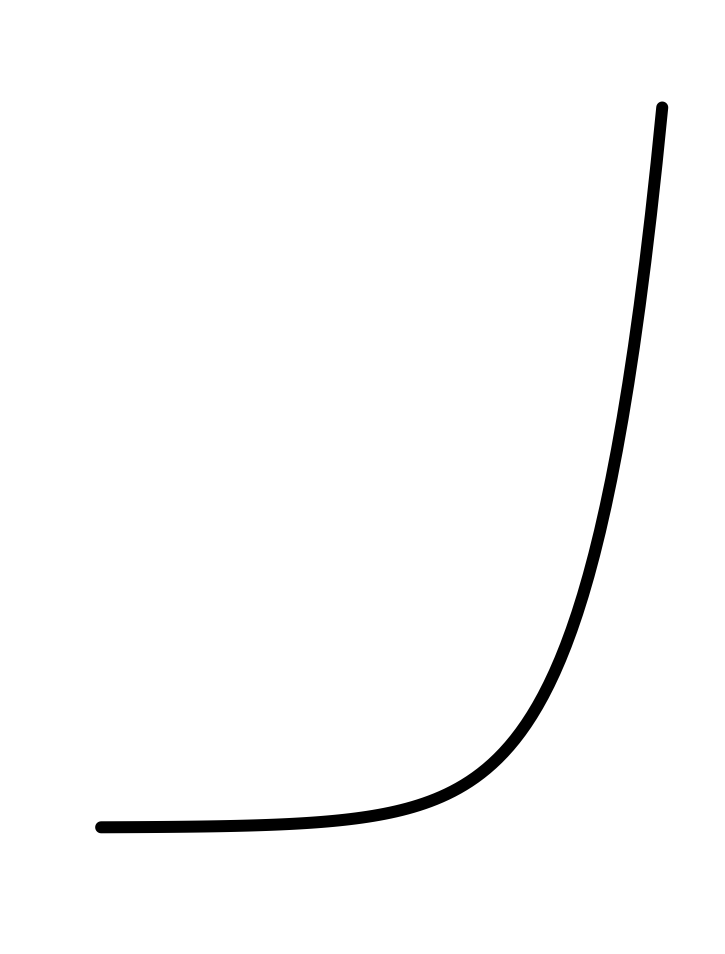
In every instance, the first step, before finding parameters, is to determine that the pattern shown in the data is a reasonable match to the shape of the function you are considering. Here’s a reminder of the shapes of the functions we will be fitting to data in this chapter. If the shapes don’t match, there is little point in looking for the parameters to fit the data!
11.1 Gaussian
The ability to perceive color comes from “cones”: specialized light-sensitive cells in the retina of the eye. Human color perception involves three sets of cones. The L cones are most sensitive to relatively long wavelengths of light near 570 nanometers. The M cones are sensitive to wavelengths near 540 nm, and the S cones to wavelengths near 430nm.
The current generation of Landsat satellites uses nine different wavelength-specific sensors. This makes it possible to distinguish features that would be undifferentiated by the human eye.

Back toward Earth, birds have five sets of cones that cover a wider range of wavelengths than humans. (Figure fig-bird-cones) Does this give them a more powerful sense of the differences between natural features such as foliage or plumage? One way to answer this question is to take photographs of a scene using cameras that capture many narrow bands of wavelengths. Then, knowing the sensitivity spectrum of each set of cones, new “false-color” pictures can be synthesized recording the view from each set.1
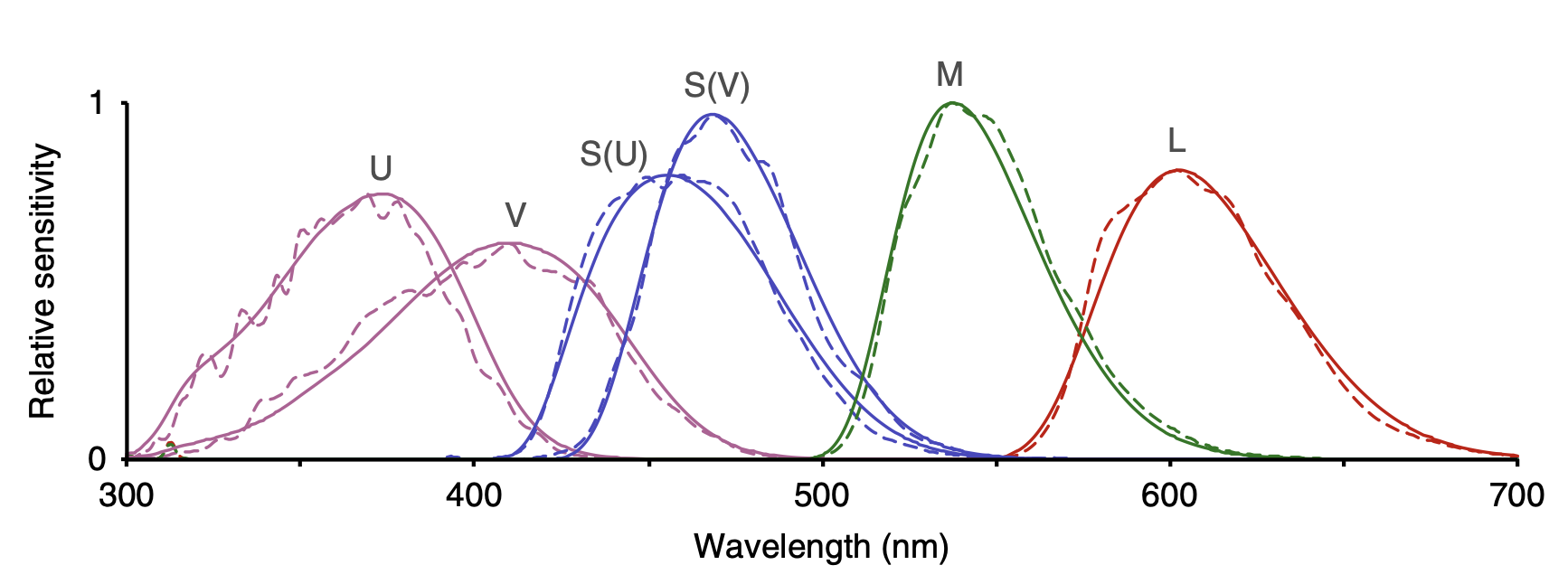
Creating the false-color pictures on the computer requires a mathematical model of the sensitivities of each type of cone. The graph of each sensitivity function resembles a Gaussian function.
The Gaussian has two parameters: the “mean” and the “sd” (short for standard deviation). It is straightforward to estimate values of the parameters from a graph, as in Figure fig-gauss-param-estimates.
## Warning: All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.
## All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.
## All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.
## All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.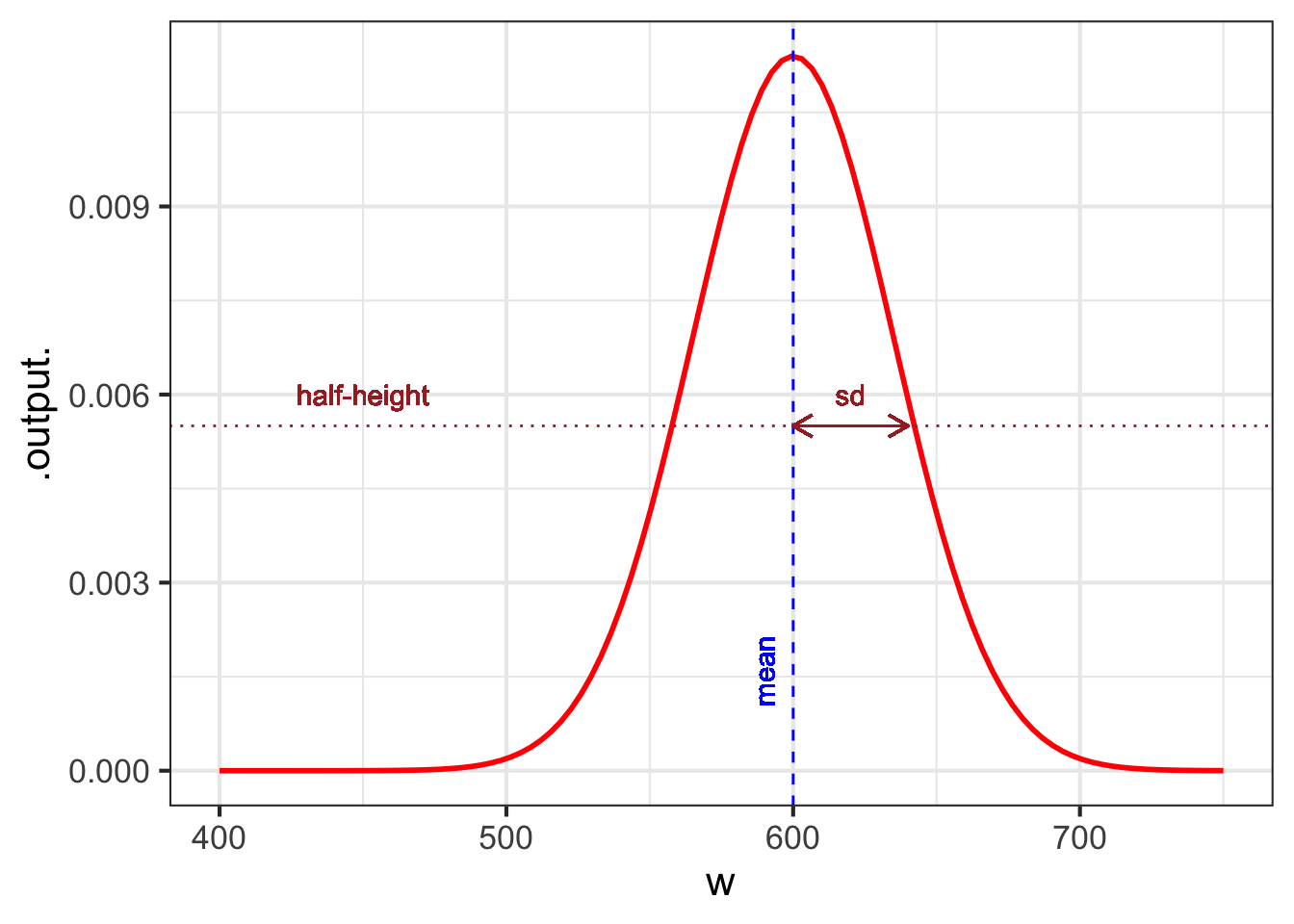
The parameter “mean” is the location of the peak. The standard deviation is, roughly, half the width of the graph at a point halfway down from the peak.
11.2 Sinusoid
We will use three parameters for fitting a sinusoid to data: \[A \sin\left(\frac{2\pi}{P}\right) + B\] where
- \(A\) is the “amplitude”
- \(B\) is the “baseline”
- \(P\) is the period.
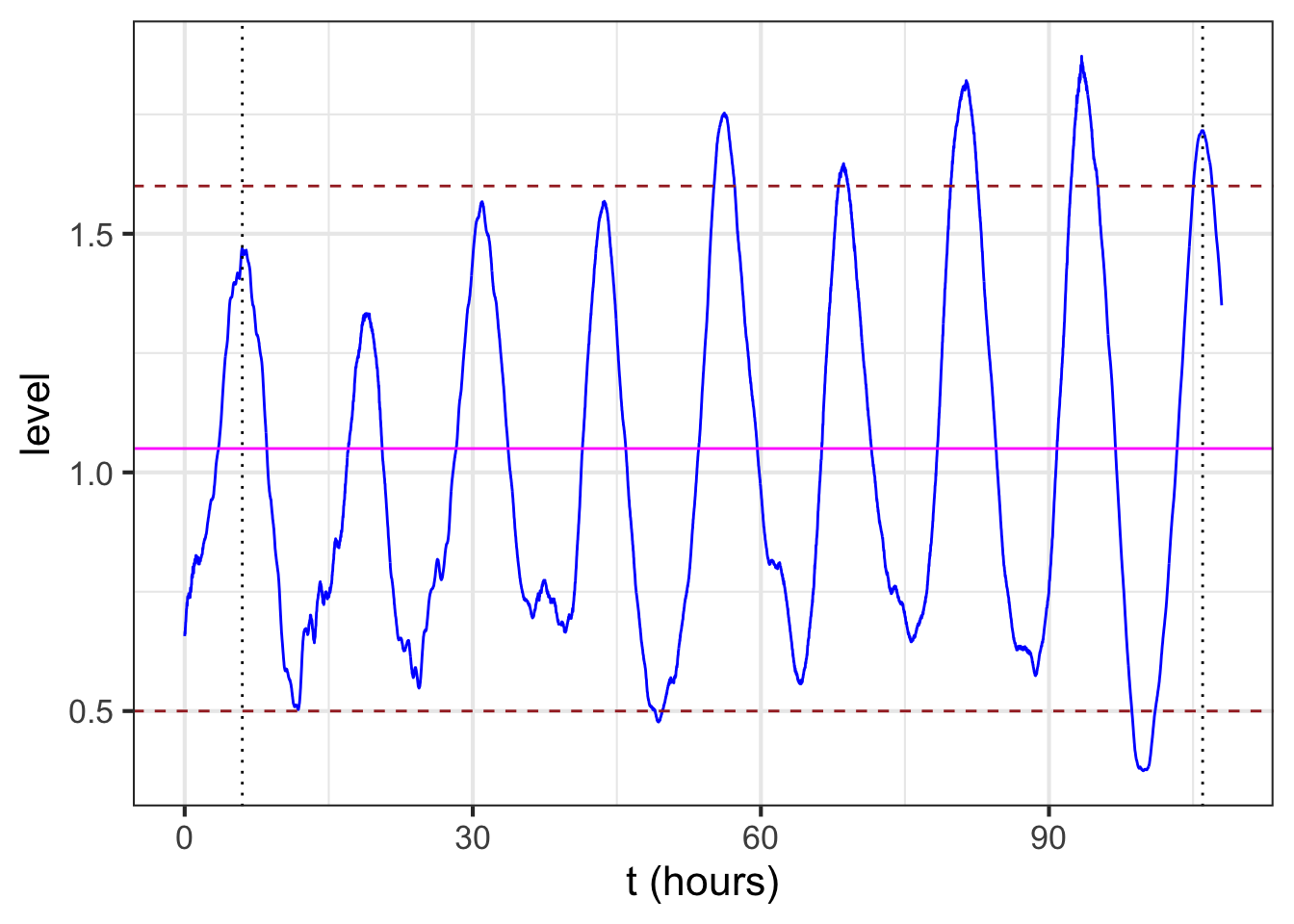
The baseline for the sinusoid is the value mid-way between the top of the oscillations and the bottom. For example, Figure fig-tides-ri1 shows the sinusoidal-like pattern of tide levels. Dashed horizontal lines (\(\color{brown}{\text{brown}}\)) have been drawn roughly going through the top of the oscillation and the bottom of the oscillation. The baseline (magenta) will be halfway between these top and bottom levels.
The amplitude is the vertical distance between the baseline and the top of the oscillations. Equivalently, the amplitude is half the vertical distance between the top and the bottom of the oscillations.
In a pure, perfect sinusoid, the top of the oscillation—the peaks—is the same for every cycle, and similarly with the bottom of the oscillation—the troughs. The data in Figure fig-tides-ri1 is only approximately a sinusoid so the top and bottom have been set to be representative. In Figure fig-tides-ri2, the top of the oscillations is marked at level 1.6, the bottom at level 0.5. The baseline is therefore \(B \approx = (1.6 + 0.5)/2 = 1.05\). The amplitude is \(A = (1.6 - 0.5)/2 = 1.1/2 = 0.55\).
To estimate the period from the data, mark the input for a distinct point such as a local maximum, then count off one or more cycles forward and mark the input for the corresponding distinct point for the last cycle. For instance, in Figure fig-tides-ri2, the tide level reaches a local maximum at an input of about 6 hours, as marked by a black dotted line. Another local maximum occurs at about 106 hours, also marked with a black dotted line. In between those two local maxima you can count \(n=8\) cycles. Eight cycles in \(106-6 = 100\) hours gives a period of \(P = 100/8 = 12.5\) hours.
11.3 Exponential
To fit an exponential function, such as the ones in Figure fig-two-exponentials, we estimate the three parameters: \(A\), \(B\), and \(k\) in \[A \exp(kt)+ B\]
| Exp. growth | Exp. decay | |
|---|---|---|
|
 |
The data in Figure fig-stans-data illustrates the procedure. The first question to ask is whether the pattern shown by the data resembles an exponential function. After all, the exponential pattern book function grows in output as the input gets bigger, whereas the water temperature is getting smaller—the word decaying is used—as time increases. To model exponential decay, use \(\exp(-k t)\), where the negative sign effectively flips the pattern-book exponential left to right.
The exponential function has a horizontal asymptote for negative inputs. The left-to-right flipped exponential \(\exp(-k t)\) also has a horizontal asymptote, but for positive inputs.
The parameter \(B\), again called the “baseline,” is the location of the horizontal asymptote on the vertical axis. Figure fig-stans-data suggests the asymptote is located at about 25 deg. C. Consequently, the estimated value is \(B \approx 25\) deg C.
11.3.1 Estimating A
The parameter \(A\) can be estimated by finding the value of the data curve at \(t=0\). In Figure Figure fig-exp-water-k that is just under 100 deg C. From that, subtract off the baseline you estimated earlier: (\(B = 25\) deg C). The amplitude parameter \(A\) is the difference between these two: \(A = 99 - 25 = 74\) deg C.
11.3.2 Estimating k
The exponential has a unique property of “doubling in constant time” as described in sec-doubling-time. We can exploit this to find the parameter \(k\) for the exponential function.
The procedure starts with your estimate of the baseline for the exponential function. In Figure fig-exp-water-k the baseline has been marked in magenta with a value of 25 deg C.
Pick a convenient place along the horizontal axis. You want a place such that the distance of the data from the baseline to be pretty large. In Figure fig-exp-water-k the convenient place was selected at \(t=25\).
## Warning: All aesthetics have length 1, but the data has 222 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.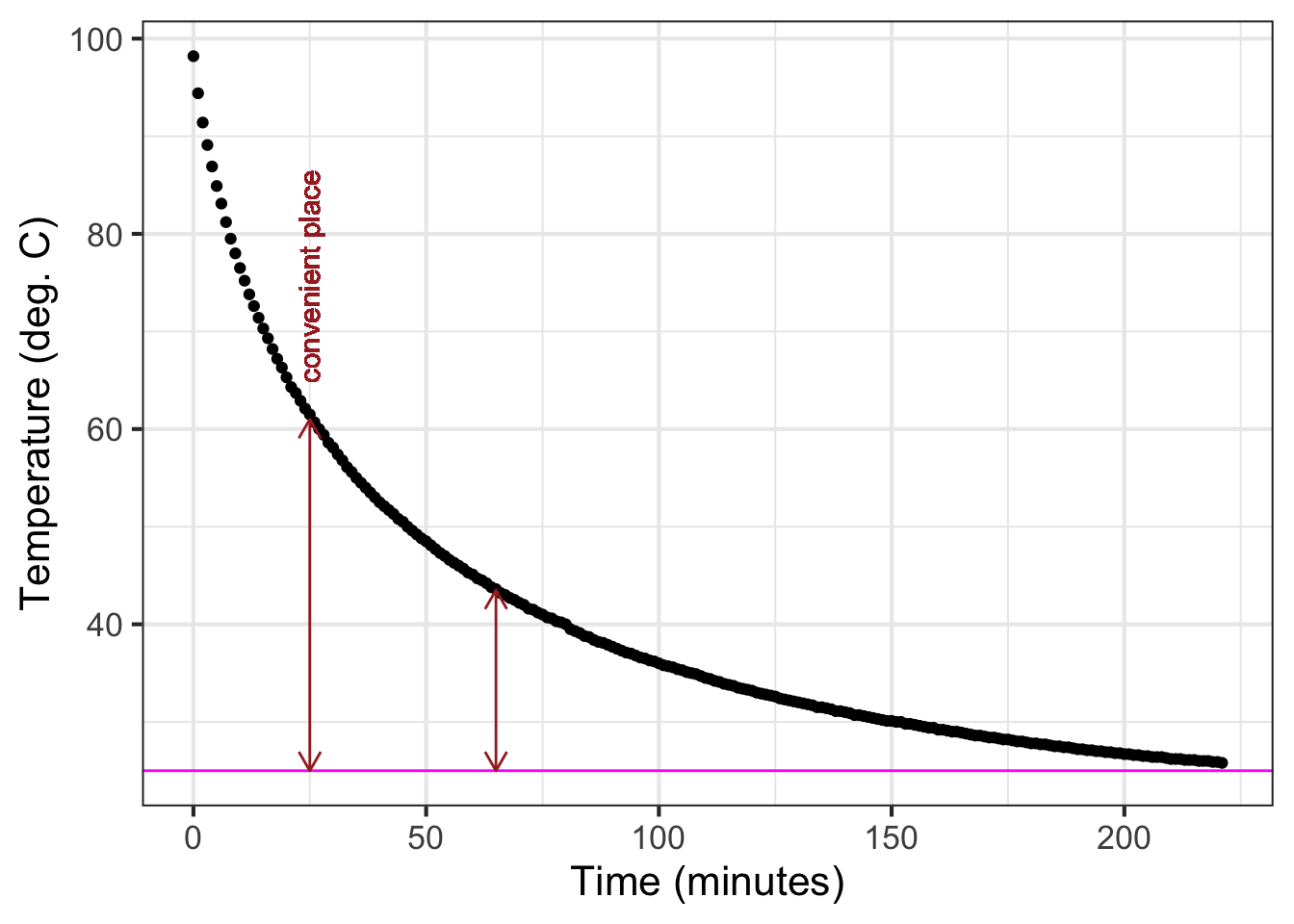
Measure the vertical distance from the baseline at the convenient place. In Figure fig-exp-water-k the data curve has a value of about 61 deg C at the convenient place. This is \(61-25 = 36\) deg C from the baseline.
Calculate half of the value from (c). In Figure fig-exp-water-k this is \(36/2=18\) deg C. But you can just as well do the calculation visually, by marking half the distance from the baseline at the convenient place.
Scan horizontally along the graph to find an input where the vertical distance from the data curve to the baseline is the value from (d). In Figure fig-exp-water-k that half-the-vertical-distance input is at about \(t=65\). Then calculate the horizontal distance between the two vertical lines. In Figure fig-exp-water-k that is \(65 - 25 = 40\) minutes. This is the doubling time. Or, you might prefer to call it the “half-life” since the water temperature is decaying over time.
Calculate the magnitude \(\|k\|\) as \(\ln(2)\) divided by the doubling time from (e). That doubling time is 40 minutes, so \(\|k\|= \ln(2) / 40 = 0.0173\). We already know that the sign of \(k\) is negative since the pattern shown by the data is exponential decay toward the baseline. So, \(k=-0.0173\).
11.4 Graphics layers
When fitting a function to data, it is wise to plot out the resulting function on top of the data. This involves making graphics with two layers, as described in sec-data-and-data-graphics. As a reminder, here is an example comparing the cooling-water data to the exponential function we fitted in sec-exponential-water.
The fitted function we found was \[T_{water}(t) \equiv 74 \exp(-0.0173 t) + 25\] where \(T\) stands for “temperature.”
To compare \(T_{water}()\) to the data, we will first plot out the data with gf_point(), then add a slice plot of the function. We will also show a few bells and whistles of plotting: labels, colors, and such.
T_water <- makeFun(74*exp(-0.0173*t) + 25 ~ t)
gf_point(temp ~ time, data = CoolingWater, alpha = 0.5 ) %>%
slice_plot(T_water(time) ~ time, color = "blue") %>%
gf_labs(x = "Time (minutes)", y = "Temperature (deg. C)")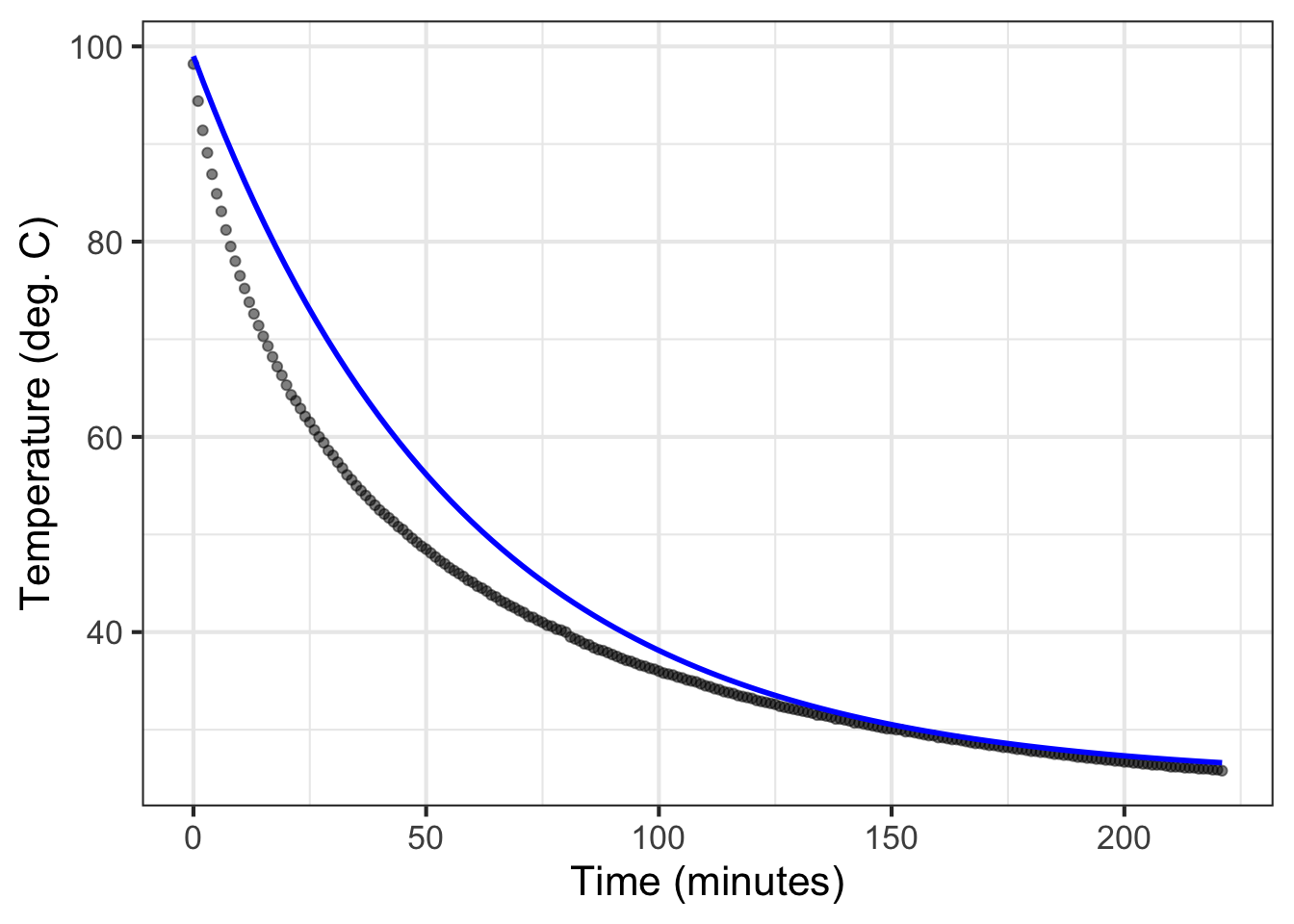
The slice_plot() command inherited the domain interval from the gf_point() command. This happens only when the name of the input used in slice_plot() is the same as that in gf_point(). (it is time in both.) You can add additional data or function layers by extending the pipeline.
By the way, the fitted exponential function is far from a perfect match to the data. sec-modeling-science-method returns to this mismatch in exploring the modeling cycle.
11.5 Fitting other pattern-book functions
This chapter has looked at fitting the exponential, sinusoid, and Gaussian functions to data. Those are only three of the nine pattern-book functions. What about the others?
| const | prop | square | recip | gaussian | sigmoid | sinusoid | exp | ln |
|---|---|---|---|---|---|---|---|---|
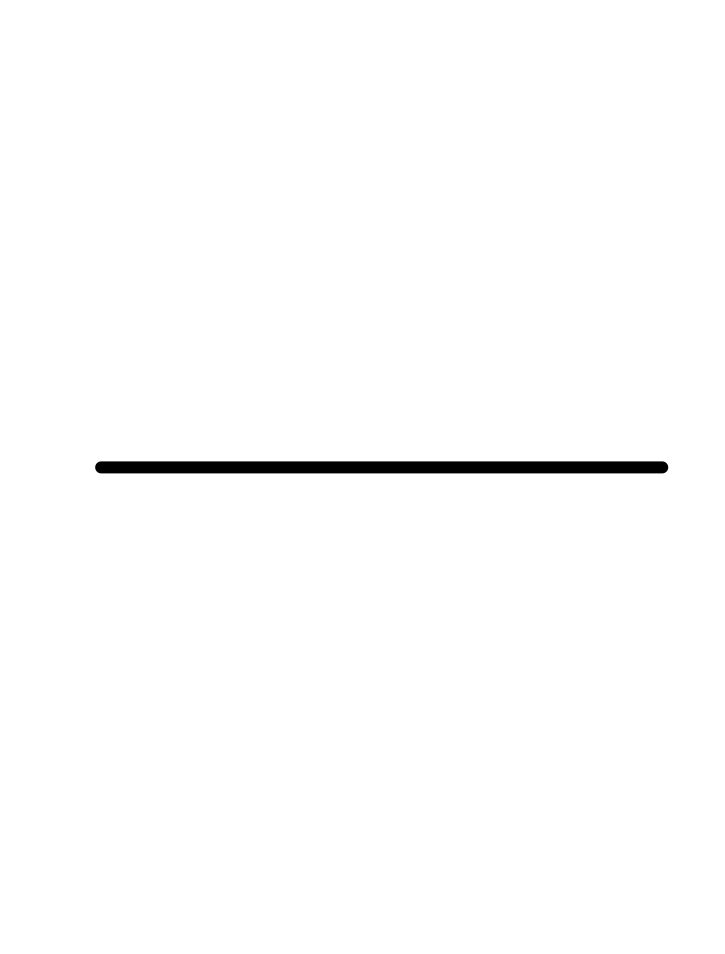 |
 |
 |
 |
 |
 |
 |
 |
 |
In Blocks 2 and 4, you will see how the Gaussian and the sigmoid are intimately related to one another. Once you see that relationship, it will be much easier to understand how to fit a sigmoid to data.
The remaining five pattern-book functions, the ones we haven’t discussed in terms of fitting, are the logarithm and the four power-law functions included in the pattern-book set. sec-magnitude introduces a technique for estimating from data the exponent of a single power-law function.
In high school, you may have done exercises where you estimated the parameters of straight-line functions and other polynomials from graphs of those functions. In professional practice, such estimations are done with an entirely different and completely automated method called regression. We will introduce regression briefly in sec-modeling-science-method. However, the subject is so important that all of Block 3 is devoted to it and its background.
11.6 Polishing parameters
Often, fitting parameters to match a pattern seen in data can be done automatically (or semi-automatically) by software. When there are multiple inputs to the function, practicality demands that automated techniques be used. And even when it’s easy to estimate parameters by eye, as with the examples in this chapter, they can be improved by use of function-fitting software. We call this improvement in estimated parameters “polishing.”
An example of such automated fitting is given in Active R chunk lst-first-two-layers. sec-modeling-science-method covers the topic in more depth.
Cynthia Tedore & Dan-Eric Nilsson (2019) “Avian UV vision enhances leaf surface contrasts in forest environments”, Nature Communications 10:238 fig-bird-views and fig-bird-cones ↩︎