sigma <- 1
mu <- 0
h <- makeFun( -(x-mu)^2/(2*sigma^2) ~ x, mu=mu, sigma=sigma)
slice_plot(h(x) ~ x, bounds(x=sigma*c(-1.5, 1.5))) %>%
gf_hline(yintercept = c(0,-0.5), color=c("dodgerblue", "orange3"))53 Diffusion
In Draft
This chapter is still in a draft state.
53.1 Origins of the gaussian function
From the start of MOSAIC Calculus we have used a small set of basic modeling functions which will by now be familiar to you:
- exponential
- logarithm: inverse to exponentials
- power-law
- sinusoid
- gaussian and sigmoid
This chapter gives a more detailed introduction to the gaussian function and provides a specific algebraic formula that composes an exponential with a low-order polynomial.
Start with the low-order polynomial: \[h(x) = - \frac{(x-\mu)^2}{2 \sigma^2}\] This is, of course a parabola with an argmax \(x^\star = \mu\) and a maximum value 0. It is written this way by convention, the point of which is to give names to two features of the function:
- The mean, \(\mu\), is the argmax of the function.
- The variance, \(\sigma^2\), how “fat” the parabola is.
(Recall that the Greek letters \(\mu\) and \(\sigma\) are pronounced “mu” and “sigma” respectively.)
A reasonable person can point out that the domain of the low-order polynomial is \(-\infty < x < \infty\). It is sensible to define “width” to refer to that part of the domain where the function’s value is non-zero and, better, where “most” of the function is. One way to define “how much” of the function there is uses the area under the curve. The convention that you are about to see defines the width as the domain that contains the central 2/3 of the overall area.
The sandbox defines the function \(h(x)\) and graphs it, with particular emphasis on the range (vertical scale!) from -1 to 0. The graph is annotated with blue and red horizontal lines with y-intercept of 0 and \(-\frac{1}{2}\) respectively.
The width of the parabola is based on the length of the horizontal line segment between the two branches of the parabola. Specifically, the width is defined as half the length of this line segment. to avoid confusion, we will use “width” in the usual English sense and a special term, standard deviation, to refer to half the length of the line segment. (“Standard deviation” is a good candidate for the worst name ever for a simple concept: a length. Another, equivalent term you will hear for this length is “root mean square,” which is almost as bad. Still, those are the standard terms and you should be careful to use instead of non-standard alternatives.)
**Part A** In the above sandbox, set `sigma <- 2`. What *standard deviation* corresponds to $\sigma = 2$? 1/4 1 \(\sqrt{2}\) 2 4
**Part B** Still holding $\sigma = 2$, what is the *variance* of the function? 1/4 1 \(\sqrt{2}\) 2 4
**Part C** Set $\sigma = 3$, and read off the graph what is the *standard deviation* of the function? 1/3 1 \(\sqrt{3}\) 3 9
**Part D** When $\sigma = 3$, what is the *variance* parameter? 1/3 1 \(\sqrt{3}\) 3 9
**Part E** Pick a $\sigma$ of your choice, try a few non-zero values for $\mu$. Read off from the graph the standard deviation. How does the standard deviation depend on $\mu$? - The standard deviation is \(\mu + \sigma\).
- The standard deviation is \(\sqrt{\strut\mu + \sigma^2}\).
- The standard deviation is \(\ln(\mu + e^\sigma)\).
- The standard deviation is not affected by \(\mu\).
**Part F** What is the relationship between the *variance* $\sigma^2$ and the *standard deviation* $\sigma$? - The standard deviation is the square root of the variance.
- The standard deviation is 1 over the variance.
- They are completely unconnected concepts.
- The variance is the square of the mean, \(\mu\).
One of the features that make bump functions useful is that they are local, the function is practically zero except on a domain of limited width. The parabola \(h(x) \equiv - \frac{(x - \mu)^2}{2 \sigma^2}\) is non-zero everywhere except at \(x = \mu\), so not at all local.
To produce our pattern-book bump function, we compose an exponential function \(e^x\) with the polynomial \(h(x)\) to get \[f(x) \equiv e^{h(x)} = \exp\left(-\frac{(x - \mu)^2}{2 \sigma^2}\right)\] This is not yet the “official” gaussian function, but are getting close!
The sandbox defines \(f(x)\) and graphs it. As with the previous sandbox, the graph is annotated with a blue horizontal line that touches the curve at the argmax and a red horizontal line with a y-intercept at \(e^{-1/2}\).
sigma <- 1
mu <- 0
f <- makeFun( exp( -(x-mu)^2/(2*sigma^2) ) ~ x, mu=mu, sigma=sigma)
slice_plot(f(x) ~ x, bounds(x=sigma*c(-3.5, 3.5))) %>%
gf_hline(yintercept = c(0,exp(-0.5)), color=c("dodgerblue", "orange3"))
sigmoid <- antiD(g(x) ~ x, lower.bound = -Inf)
# Graph the sigmoid on the domain -10 < x < 10Notice that the vertical range of the function is \(0 < f(x) \leq 1\). The argmax is \(\mu\), so \(f(\mu) = 1\). This seems easy and convenient, but one of the purposes of the standard gaussian function is to define a standard sigmoid function. It is the sigmoid that we want to have a range from 0 to 1.
How to scale the gaussian \(f(x)\) to produce a sigmoid with the range 0 to 1? Recall that a sigmoid is the anti-derivative of the corresponding gaussian. In the sandbox, we use antiD() to compute \[\int_{-\infty}^x f(u) du\], which we called sigmoid(). From the graph of sigmoid() you can read off the scaling factor that will make the vertical range of the resulting sigmoid zero to one.
**Part G** Where did the variable $u$ come from in $$\int_{-\infty}^x f(u) du ?$$ - The instructors made a mistake. They will try to be more careful in the future!
- You can use any name for the variable of integration. The function \(\int_{-\infty}^x f(u) du\) will be a function of \(u\), not \(x\).
- You can use any name for the variable of integration. The function \(\int_{-\infty}^x f(u) du\) will be a function of \(x\), not \(u\).
- \(u\) is the Latin equivalent of \(\mu\).
**Part H** This question will take a bit of detective work in the sandbox. Make a table of a few combinations of different values for $\mu$ and $\sigma$. For each combination, find the maximum value of the corresponding `sigmoid()` function. Using this data, choose the correct formula for the maximum value of the sigmoid as a function of $\mu$ and $\sigma$. - \(\sqrt{\strut 2 \pi \sigma^2}\)
- \(\pi \sigma\)
- \(\sqrt(\strut \mu \pi \sigma)\)
- \(\sqrt(\strut \pi \sigma^2 / \mu)\)
Putting all this together, we arrive at our “official” standard gaussian function, called the Gaussian function:
\[g(x) \equiv \frac{1}{\sqrt{\strut2\pi\sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2}\] The Gaussian function is important to many quantitative disciplines and has a central role in statistics. The function is named after physicist and mathematician Carl Friedrick Gauss (1777-1855). But in the social sciences, it is usually called the “normal” function; that is how common it is.
In R, the Gaussian function is provided as dnorm(x, mu, sigma). (The corresponding sigmoid, that is, the anti-derivative of dnorm() with respect to x is available as pnorm(x, mu, sigma).
The Gaussian function is so important, that it is worth pointing out some recognizable landmarks in the algebraic expression. Knowing to look for such things is one trait that defines an expert.
- The term \(1/\sqrt{2 \pi \sigma^2}\) is not a function of \(x\), it is a constant related to the variance \(\sigma^2\). It is just a number arranged to make \[\int_{-\infty}^\infty g(x) dx = 1 .\]
- The exponential means that, whatever the values of \(\mu\) and \(\sigma\), the function value \(0 < g(x)\).
- The argmax is at \(x^\star = \mu\). This is also the “center” of the function, which is symmetrical around the argmax.
- The variance \(\sigma^2\) appears directly in the formula. In no place does \(\sigma\), the standard deviation, appear without the exponent 2. This is a hint that the variance is more fundamental than the standard deviation.
**Part I** Go back to the sandbox where we defined the function `f(x)` and graphed it. The function has a distinctive shape which is almost always described in terms of a familiar word. Which one is it? breadloaf-shaped ghost-shaped bell-shaped sombrero-shaped
Optional background. Now for a bit of irony. We’ve taken a lot of care to define a specific form of gaussian function with a formula that strikes many people as complicated. It must be that all these specifics are important, right? In reality, any function with a roughly similar shape would work in pretty much the same way. We could have defined our “official” gaussian function in any of a number of ways, some of which would be algebraically simpler. But the specific gaussian shape is a kind of fixed point in the differential equation that we will study next.
53.2 Net flux
Recall Newton’s Law of Cooling, \(\dot{T} = - k (T - T_a)\) Although temperature was hardly understood as a physical phenomenon in Newton’s era, with today’s sensibility you can understand that energy is flowing into or out of the object from the ambient environment. The word flux is often used in mathematics to refer to such flows.
We’ve studied cooling in a spatially discrete context, the cooling of a single point (e.g. “a cup of coffee”) in an environment that has only one property, the “ambient” temperature.
Let’s switch to a spatially continuous context, a bar of iron with one end lying in a bed of hot coals and the other end in the open air, as in the picture:

The iron rod is incandescent at the right end and cooler toward the left. If the picture were a movie, you likely would be able to predict what the action will be: Heat will flow down the rod from right to left. The free end of the rod will eventually get burning hot.
The temperature \(T\) at each point \(x\) in the rod is a function of position. But at any given position, the temperature is a function of time \(t\). That is, the temperature of the rod is a function of two variables: \(T(x,t)\).
If we were thinking about the movie frame-by-frame, we might prefer to treat \(t\) as a discrete variable and could write \(T(x,t)\) as \(T_t(x)\). It does not really matter which, but it helps to think about \(T()\) as a function of \(x\) whose shape evolving in time.
Now back to Newton’s Law of Cooling. The flux of heat is the difference between the object’s temperature and the ambient temperature. But in the continuous spatial system, the difference in temperature between two infinitely close neighboring points is zero. That suggests no flux. Of course, a major theme in Calculus is to provide means to discuss the rate of difference of a value at two infinitely close points: the derivative \(\partial_x T(x, t)\). This derivative gives the flux of heat from right to left.
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.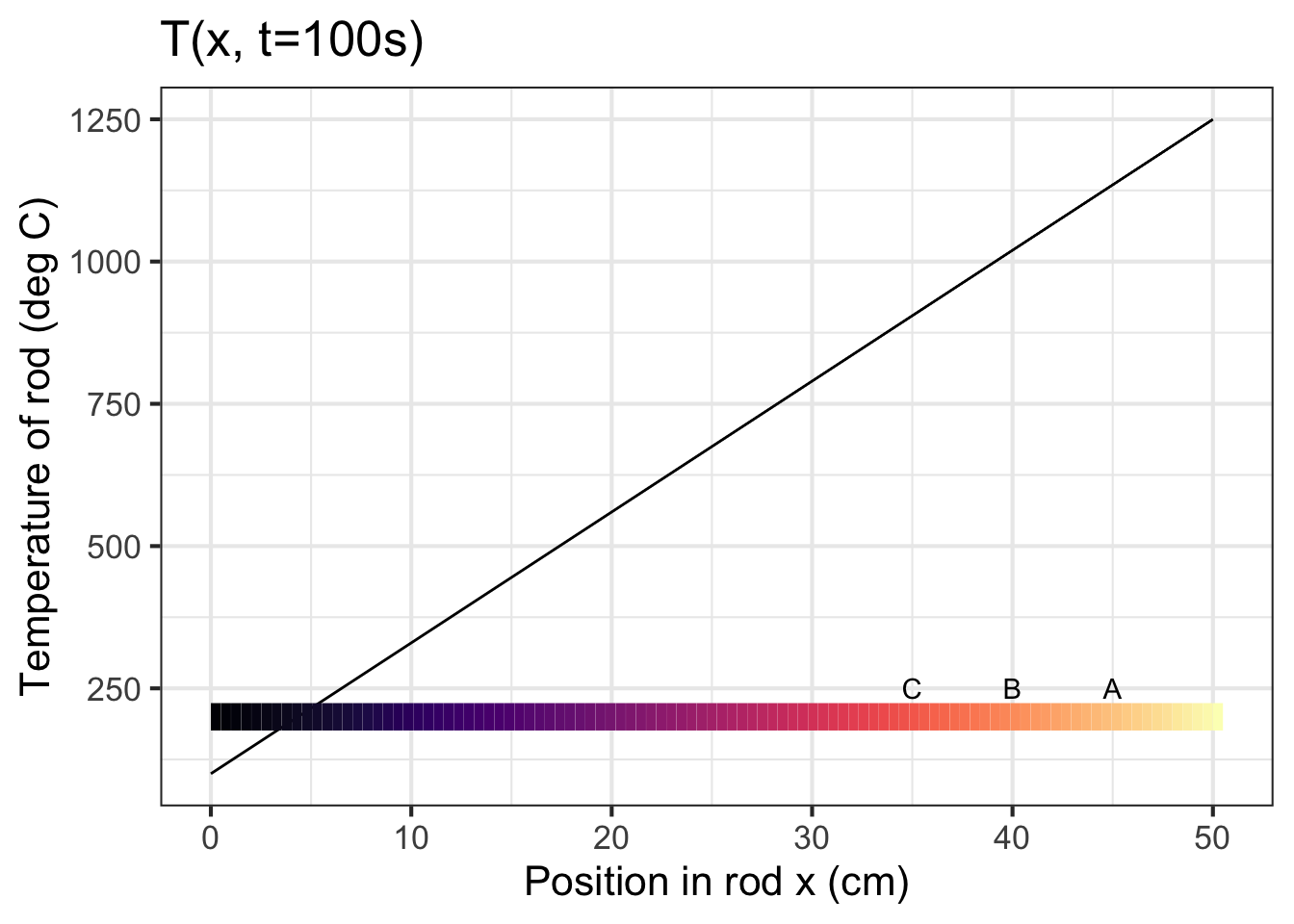
It might be tempting to translate this directly into the terms of Newton’s Law of Cooling and claim, wrongly that \(\partial_t T(x, t) = -k \partial_x T(x, t)\). Why is this wrong? In the spatially discrete setting—cup of coffee, ambient environment—there are only two spatial points of interest. But along the continuous iron rod, there are at least three points to be considered. Let’s call them \(x_A\), \(x_B\), and \(x_C\) as in the diagram. We are interested in \(\partial_t T(x_B, t)\). This change in temperature at point B is driven by the flux from point C to point B and is proportional to \(\partial_x T(x_B, t)\). But the change in temperature at point B is equally influenced by the flux from B to A. That is, the change in temperature at point B is set by the difference in flux, the flux coming from A to B and the flux going from B to C.
In the spatially continuous context, the net flux or difference in differences (A to B, B to C) is represented by the second derivative with respect to \(x\). That is, along the rod, Newton’s Law of Cooling amounts to \[\partial_t T(x, t) = k\, \partial_{xx} T(x, t)\] This is called the heat equation and was introduced in 1807 by Jean-Baptiste Joseph Fourier (1786-1830). The same equation is now also called the diffusion equation.
Some people might be more comfortable thinking about the discrete-time dynamics of the movie, which could be written \[T_{t+h}(x) \approx T_t(x) + h\,k\, \partial_{xx} T_t(x)\]
Exercise: Turn away from the iron rod of the picture and imagine being presented with four new rods each of which has been heated in some way to produce a temperature profile at time 0, that is \(T_0(x)\) as shown in the four graphs below.
## Warning: All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.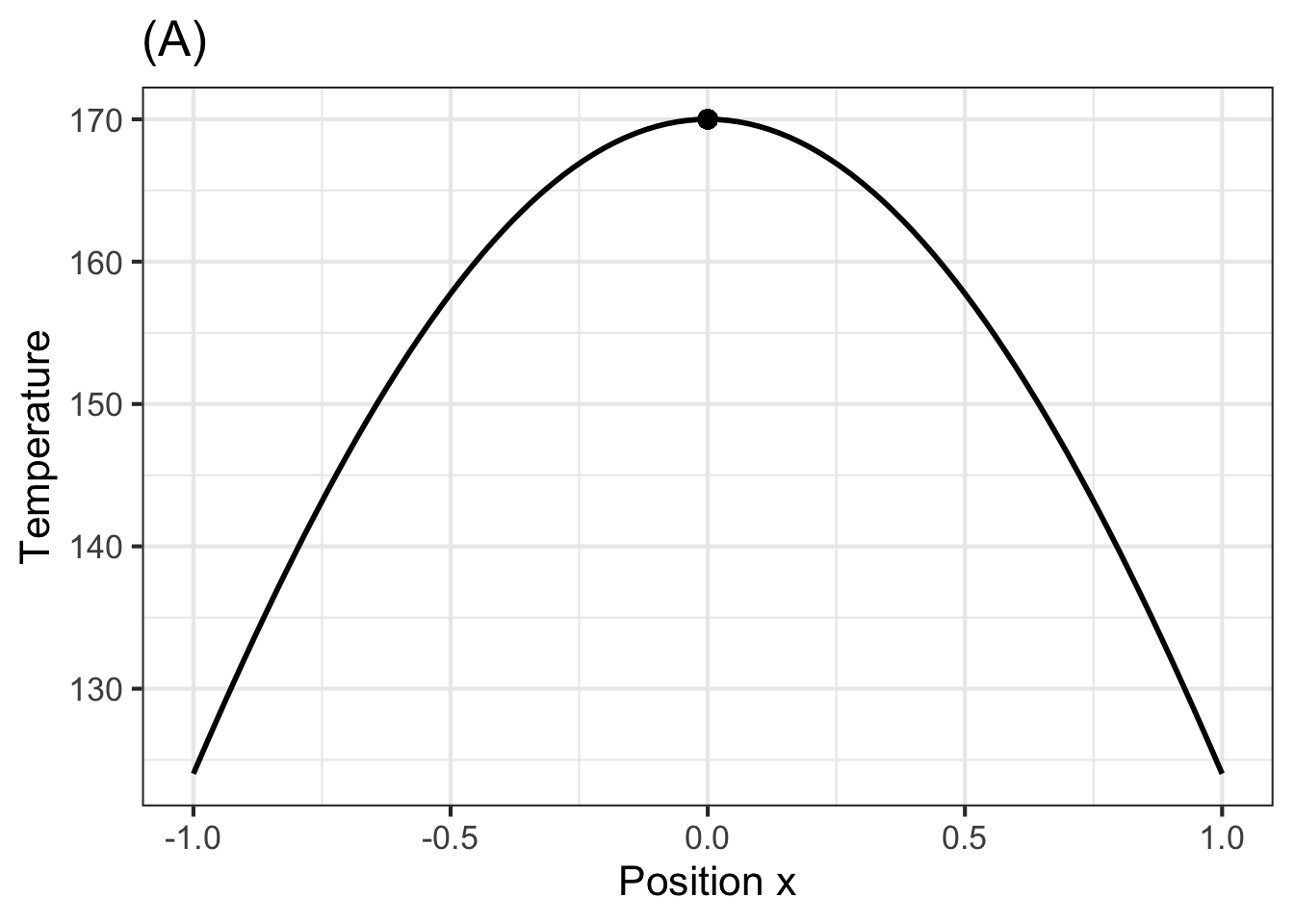
## Warning: All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.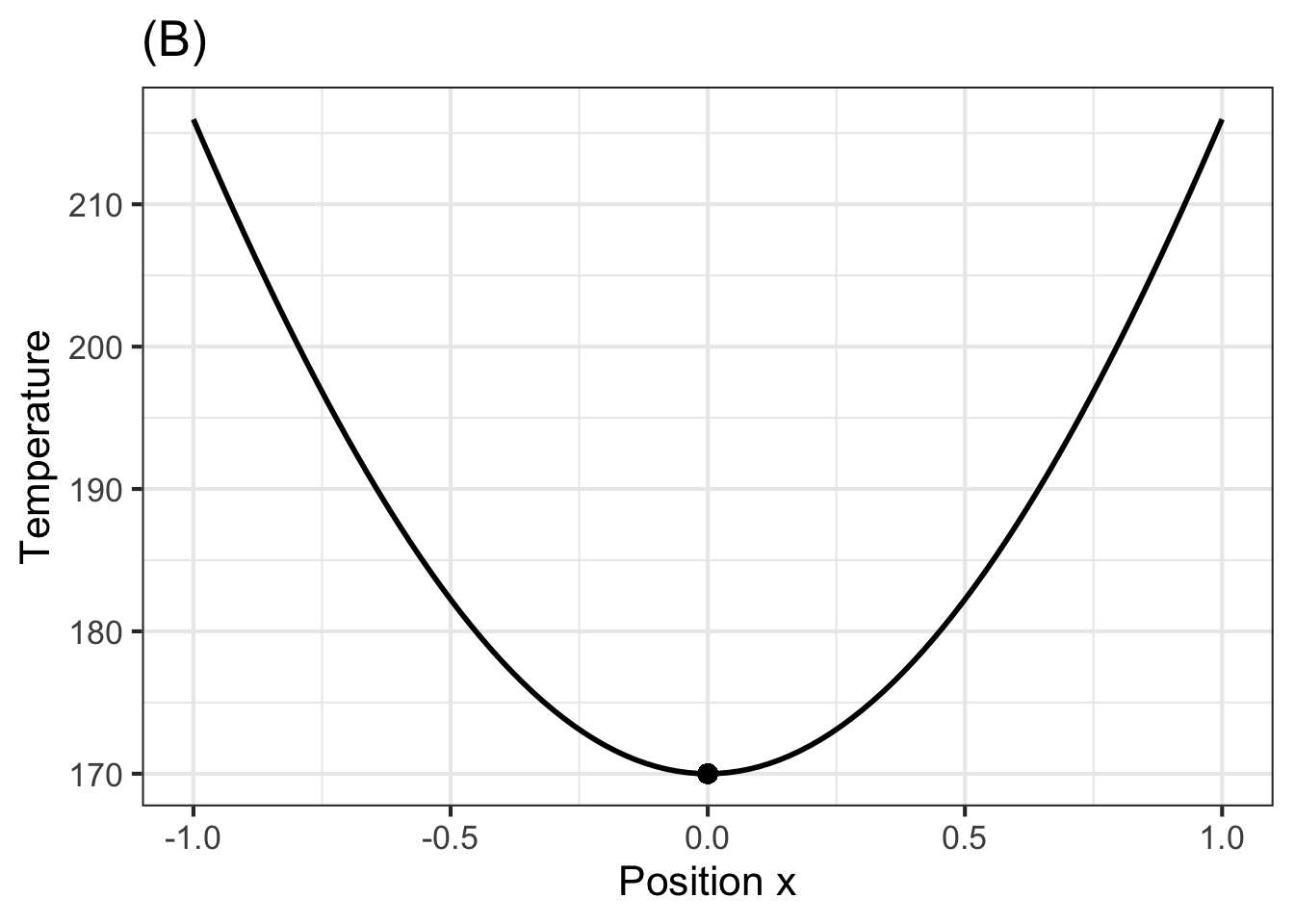
## Warning: All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.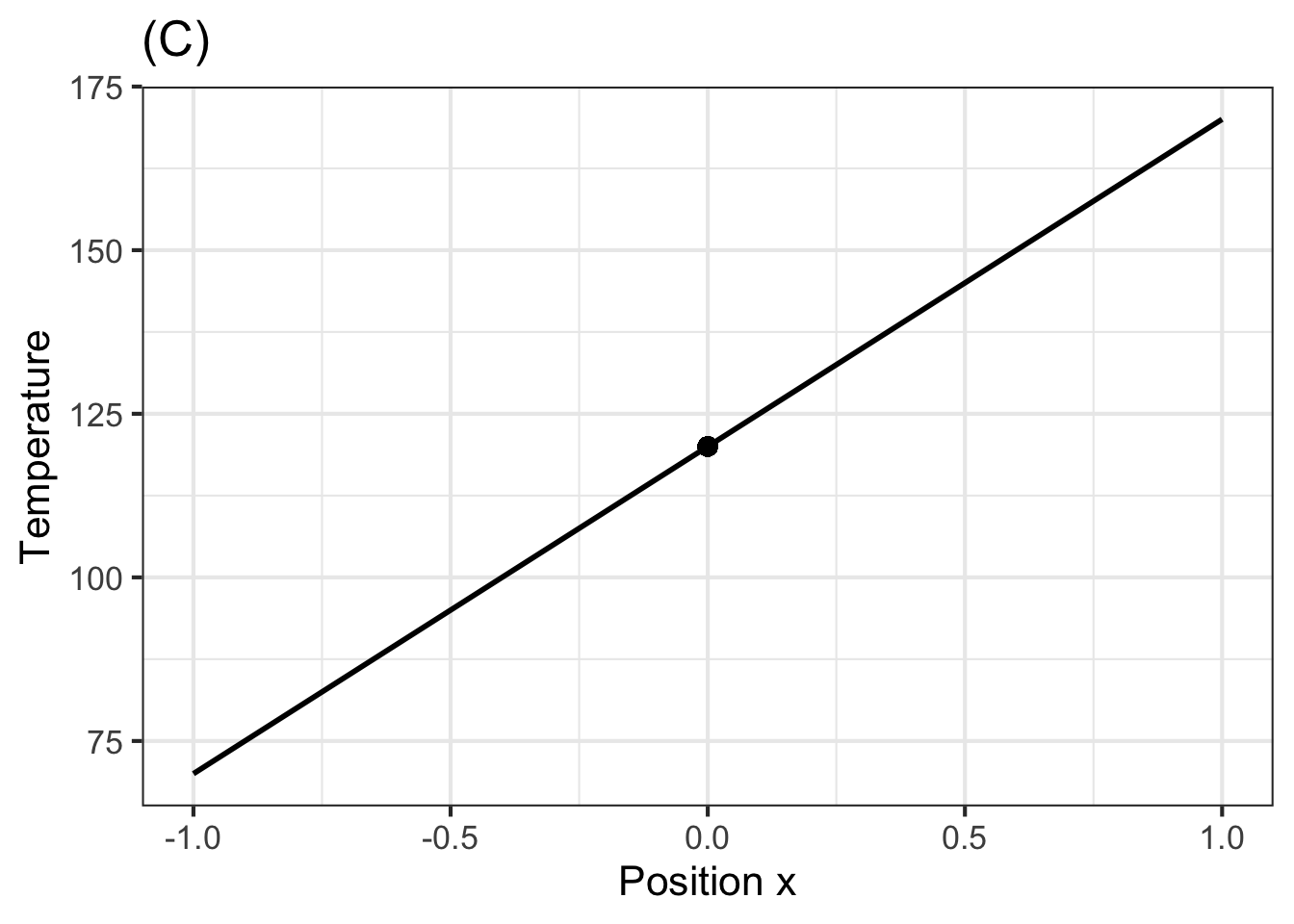
## Warning: All aesthetics have length 1, but the data has 101 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.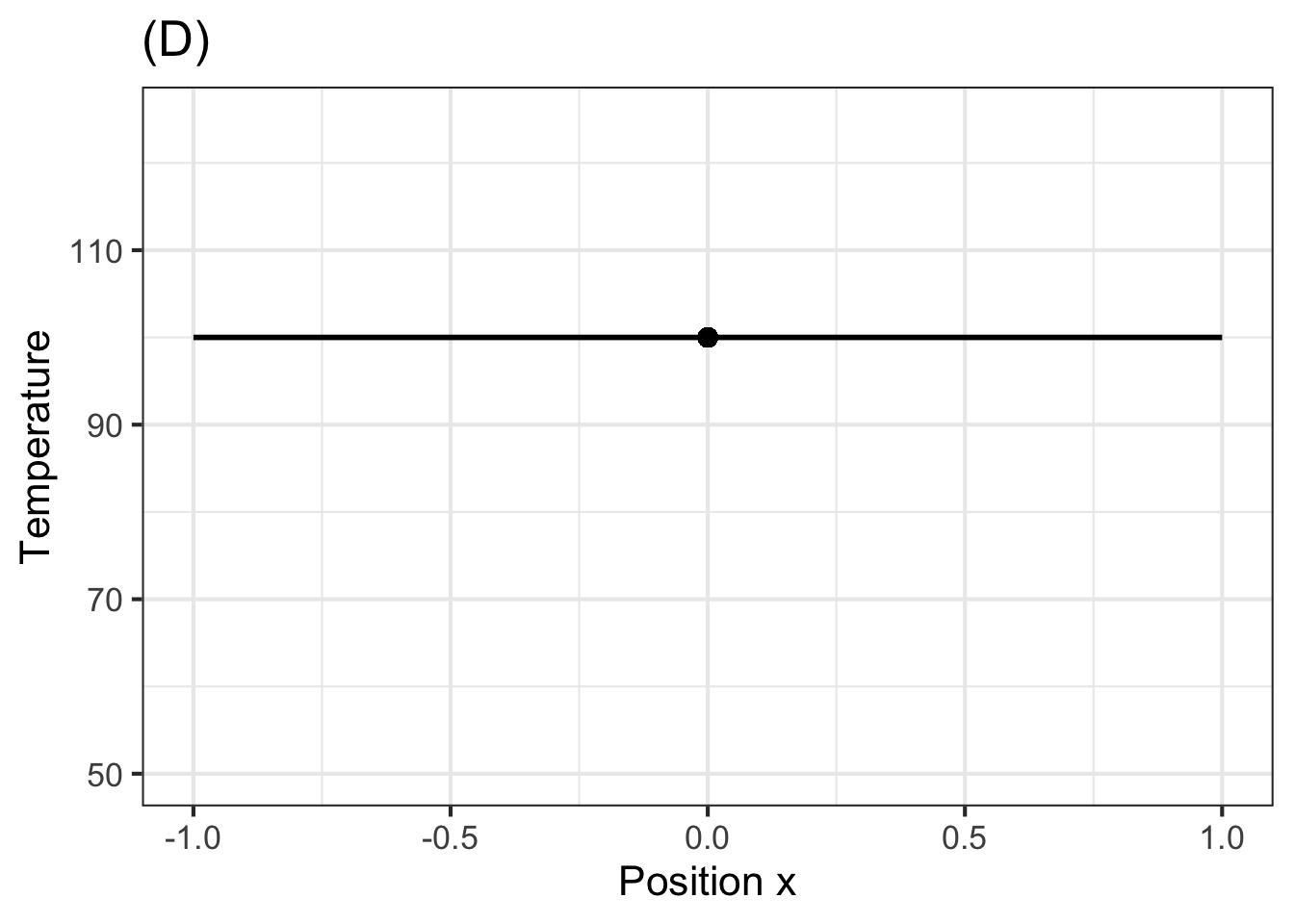
- For the function \(T(x, t=0)\) shown in Graph (A), how will the temperature at \(x=0\) change instantaneously? (That is, what is \(\\partial_t T(x, t=0)\)?)
“+Temperature decreases+”, “No change in temperature”, “Temperature increases”, “Temperature oscillates” = “The temperature cannot oscillate instantaneously. The value of a derivative function at a point is a real number, not an oscillation.” , random_answer_order = FALSE )
For the function \(T(x, t=0)\) shown in Graph (B), how will the temperature at \(x=0\) change instantaneously? (That is, what is \(\\partial_t T(x, t=0)\)?) “Temperature decreases”, “No change in temperature”, “+Temperature increases+”, “Temperature oscillates” = “The temperature cannot oscillate instantaneously. The value of a derivative function at a point is a real number, not an oscillation.” , random_answer_order = FALSE )
For the function \(T(x, t=0)\) shown in Graph (C), how will the temperature at \(x=0\) change instantaneously? (That is, what is \(\\partial_t T(x, t=0)\)?) “Temperature decreases”, “+No change in temperature+”, “Temperature increases”, “Temperature oscillates” = “The temperature cannot oscillate instantaneously. The value of a derivative function at a point is a real number, not an oscillation.” , random_answer_order = FALSE )
askMC( 4. For the function \(T(x, t=0)\) shown in Graph (D), how will the temperature at \(x=0\) change instantaneously? (That is, what is \(\\partial_t T(x, t=0)\)?) “Temperature decreases”, “+No change in temperature+”, “Temperature increases”, “Temperature oscillates” = “The temperature cannot oscillate instantaneously. The value of a derivative function at a point is a real number, not an oscillation.” , random_answer_order = FALSE )
53.3 Diffusion
Recall that the heat equation describes how the temperature along a approximately 1-dimensional object—an iron bar, for example—changes with time due to spatial differences in temperature from point to point. The heat equation is
\[\underbrace{\partial_t T(x, t)}_\text{change in time} = \ \ \ k\, \underbrace{\partial_{xx} T(x, t)}_\text{pattern in space}\]
**Part J** Suppose the inputs to the temperature function have units centimeters (for $x$) and seconds (for $t$) and that the output is in degrees Kelvin (which we will write "K"). What are the units of the coefficient $k$? \(K cm^{1}\) \(K cm^{2} s^{-1}\) \(cm^{2} s^{-1}\) \(s cm^{2}\)
At the time Fourier was working, there was no molecular theory of matter and very little understanding of what the “heat substance” might consist of. Now we know that heat is the energy of molecular vibrations. This energy diffuses through the material.
Similarly, “diffusion” is one mode of physical motion of material, for example movement of sugar molecules within a cell. Other things can diffuse as well, for example the action of viscosity in fluids can be seen as the diffusion of momentum.
Starting in the 20th century and in support of the developing molecular theory of gasses, mathematicians and physicists undertook to follow the trajectories of individual diffusing particles and to develop a means to describe them mathematically. This included the concept of a “random walk,” movement of a particle shifting direction and speed randomly as it collides with other moving molecules and particles in its environment.
The movie shows a simulation of a few particle (in yellow) undergoing a random walk. The path followed by each diffusing particle is shown in blue; the velocity of one particle is indicated with a red vector.

The idea of random walks has become especially important in economics and finance. The walking “particle” might be the price of a stock or other derivative asset. The “collisions” happen as individual trades are made in the market, each trade being influenced by some news or situation or the passing whims, fancies, or fears of investors. The work on this point of view started about 1900 by a mathematics graduate student, Louis Bachelier, who undertook to study the movements of the Bourse, the Parisian stock exchange. The 1997 Nobel Prize in economics was awarded for a “new method to determine the value of [market] derivatives.”
For these reasons, we will focus and the mathematics of diffusion instead of the equivalent but historically prior mathematics of heat. We will work with a function \(C(x, t)\) which stands for the concentration of particles in some medium such as a gas as a function of space and time. In economics, \(x\) will stand for the value of some asset such as an investment, and \(C()\) gives a probability density for each possible value of \(x\).
For the sake of visualization, suppose some odor molecules are released in at the midpoint of a pipe with absolutely still air. Over time, the molecules will diffuse throughout the along the extent of the pipe.
If \(C(x, t)\) is the concentration of odor molecules at each point \(x\) and time \(t\), then the change in concentration with time is:
\[\partial_t C(x, t) = D\, \partial_{xx} C(x, t)\] This is called the “Diffusion equation.” \(D\) is called the “diffusion coefficient” and depends on the size of the molecule and the temperature in the pipe. The “diffusion equation” is the same as the “heat equation,” with different names used for the quantities involved.
**Part K** Suppose the inputs to the concentration function have units centimeters (for $x$) and seconds (for $t$) and that the output is in nanograms per cubic centimeter ($ng\ cm^{-3}$) . What are the units of the coefficient $k$? \(ng cm^{-1}\) \(ng cm^{1} s^{-1}\) \(cm^{2} s^{-1}\) \(s cm^{1}\)
Many people have difficulty imagining the sorts of frequent collisions that are behind diffusion. They think, for instance, that in still air the molecules are pretty much still. This is wrong. A typical velocity of a water molecule in air at room temperature and pressure is 650 m/sec. (The speed of sound is about 350 m/sec.) But the time between molecular collisions is on the order of \(10^{-10}s\), so the typical distance travelled between collisions is about \(10^{-7}m\). For a root mean square distance of 1m, we need roughly \(10^{14}\) collisions, which would occur in \(10^{4}\) seconds (a couple of hours).
53.4 Dynamics of variance
In this section, we will explore the connection between diffusion and the gaussian function. Recall that we modeled the temperature along a one-dimensional spatial domain (a “bar of iron”) as it evolves in time as a function of both position and time: \(C(x, t)\). The same sort of function—of position and time—can be used to describe the concentation of particles freely diffusing along a medium such as air in a pipe.
We constructed a differential equation to describe the dynamics of \(C(x, t)\) called the “heat” equation or the “diffusion” equation, depending on context. Before using that differential equation, let’s explore a little bit what we might mean about the “dynamics of a function.”
In studing dynamics we worked first with time taken discretely, e.g. a sequence of states \({\mathbf x}_0\), \({\mathbf x}_1\), \({\mathbf x}_2\), \(\ldots\), \({\mathbf x}_n\), \(\ldots\). The vector \({\mathbf x}_n\) is the “state” of the system at time step \(n\). In our work, we looked at 1-dimensional and 2-dimensional states, tracing out a trajectory from one time step to the next and the next and so on. Exactly the same ideas would apply to 3- and higher-dimensional states, say an ecosystem involving growing grass, and populations of mice, rabbits, foxes, birds, and so on.
In our present contexts, heat or diffusion, we are working with functions. Let’s return to the earlier metaphor of a movie of \(C(x, t)\) with the frames taken every \(h\) seconds. The movie is the sequence of frames \(C_0(x)\), \(C_h(x)\), \(C_{2h}(x)\), \(\ldots\), \(C_t(x)\), \(\ldots\).
To describe the dynamics—that is, the change from frame to frame in the movie—we write a finite-difference equation, generically: \[C_{n+1}(x) = f(C_n(x))\] In the movie of diffusion, that equation will be this:
\[C_{t+h}(x) = C_n(x) + h\, \alpha\, \partial_{xx} C_n(x)\] The term \(\partial_{xx} C(x)\) tells us the net flux of heat/particles/probability into the point \(x\).
In English, this says, “The concentration at \(x\) in one frame of the movie is the amount that was there in the previous frame plus the net flux of heat/particles from the neighboring points.”
Now imagine making the movie using an ultra-high-speed camera that takes a new frame every \(h\) microseconds. We will label the time of one frame as \(t\) and the time of the next frame as \(t+h\). The frame-to-frame change is therefore \[C_{t+h}(x) = C_t(x) + h\, \alpha \partial_{xx} C_t(x)\] We can equally well write \(C_t(x)\) as \(C(x, t)\), our notation for functions on a continuous domain. Doing this, and re-arranging the formula, gives: \[\frac{C(x,t+h) - C(x,t)}{h} = \alpha \partial_{xx} C(x, t)\] The left side of this equation is the differencing operator applied to \(C(x, t)\) (with respect to \(t\)). In the limit as \(h\rightarrow 0\) (that is, as you turn the video frame rate faster and faster) we can replace the left side of the equation with the partial derivative \(\partial_t C(x,t)\). That is the heat/diffusion equation.
We will find the solution \(C(x,t)\) to the differential equation using Euler’s method. In other words, we will make movies of the functions \(C_t(x)\) one frame at a time. We know the dynamics; to start we need is an initial condition, the function \(C_0(x)\).
C_funs <- list()
flux_funs <- list()
tmp <- list()
xpts <- seq(-50, 50, length=1000)
C_funs[[1]] <- tibble::tibble(
x = xpts,
y = dnorm(x, 0, 1)
)
for (k in 1:500) {
tmp <- spliner(y ~ x, data = C_funs[[k]])
foo <- flux_funs[[k]] <- D(tmp(x) ~ x + x, .hstep=1)
C_funs[[k+1]] <- tibble::tibble(
x = xpts,
y = tmp(x) + 0.1*foo(x)
)
}Imagine that we have a long, thin pipe filled with still air and we inject at position \(x=0\) a concentration of particles, say 1600 per cm^3. Equivalent, you could picture a freezing-cold iron bar and, at time \(t=0\), we place a white-hot coal on the center point, heating it to 1600 (deg C) and then removing the coal. The initial condition looks like this:
top <- max(C_funs[[1]]$y)
gf_line(y ~ x, data = C_funs[[1]] |> filter(abs(x) < 25)) %>%
gf_labs(y="Temperature (deg C)", x="Position along bar", title="Initial condition C(x,t=0)") %>%
gf_hline(yintercept = exp(-.5)*top, color="orange3")The red horizontal line is positioned to enable you to read off the standard deviation of the bell-shaped function.
The next frame of the movie will show \(C_h(x)\). To construct that, we will compute the net flux into each point on the bar.
tmp <- spliner(y ~ x, data = C_funs[[1]])
foo <- D(tmp(x) ~ x & x, .hstep=1)
slice_plot(foo(x) ~ x, bounds(x=c(-25, 25)), npts=500) %>%
gf_labs(y="Net flux (deg C/cm^2)", x="Position along bar", title="Net flux at time t=0")You can see that there is a strong net flux out of the center point and a net flux in to neighboring regions: the heat will be spreading out. Far from the center point, the net flux is zero. In the next graphs, we will zoom in on the center of the domain, \(-2.5 \leq x \leq 2.5\).
To find the next Euler step, that is, the function \(C_h(x)\), we add the net flux (scaled by \(h \alpha\)) to \(C_0(x)\). As usual, we take one Euler step after the other to reach whatever time \(t\) we want.
Here is the solution \(C(x, t=0.5)\) shown with \(C(x, t=0)\) superimposed in blue. (We set \(\alpha=2\) and used 5 Euler steps with \(h=0.1\).)
draw_C <- function(n, compare_n=1, show_sd=TRUE, domain=5) {
Dat <- C_funs[[n]] |> filter(abs(x) < domain)
ylab <- glue::glue("C(x, t={(n-1)*0.1}) in deg C.")
title <- glue::glue("C(x, t={(n-1)*0.1})")
redline <- exp(-0.5) * max(Dat$y)
P <- gf_line(y ~ x, data = C_funs[[n]] |> filter(abs(x) < domain)) %>%
gf_labs(y=ylab,
x="Position along bar", title=title)
if (compare_n > 0) {
P <- P |>
gf_line(y ~ x, alpha=0.5, color="dodgerblue",
data = C_funs[[compare_n]] |> filter(abs(x) < domain))
}
if (show_sd) {
P |> gf_hline(yintercept=redline, color="orange3")
} else {
P
}
}
draw_C(6, domain=25, show_sd=FALSE)At time \(t=0.5\) , the temperature at the center has gone down. Less obviously, \(C(x, h)\) is a tiny bit wider than \(C(x,t=0)\). That is, heat has spread out a bit from the center.
Here is the function \(C(x,t)\) at \(t=1, 2, 3, 4\). You can see the function spreading out as \(t\) increases. We’ve zoomed in on the x-axis to where the action is.
axis5 <- function(P, xlim=5, dxlim=xlim/50) {
P |> gf_refine(scale_x_continuous(breaks=(-xlim):xlim,
minor_breaks = seq(-xlim,xlim,by=dxlim)))
}
draw_C(11, domain=5, show_sd=TRUE) |> axis5()
draw_C(21, domain=5, show_sd=TRUE) |> axis5()
draw_C(31, domain=5, show_sd=TRUE) |> axis5()
draw_C(41, domain=5, show_sd=TRUE) |> axis5()Use the intersection between the red horizontal line and the black curve to find the width of the black curve, that is, the standard deviation. Which of these sequences correspond to the standard deviation at times 1, 2, 3, and 4?
“\(\\sigma_1 = 1.7, \\sigma_2 = 2.1, \\sigma_3 = 2.5, \\sigma_4 = 2.9\)”, “+\(\\sigma_1 = 1.7, \\sigma_2 = 2.2, \\sigma_3 = 2.6, \\sigma_4 = 2.9\)+”, “\(\\sigma_1 = 1.7, \\sigma_2 = 2.2, \\sigma_3 = 2.7, \\sigma_4 = 3.2\)”, “\(\\sigma_1 = 1.7, \\sigma_2 = 2.2, \\sigma_3 = 2.8, \\sigma_4 = 3.5\)”,
Here is a similar set of graphs for \(t=10, 20, 30, 40\):
draw_C(101,0, domain=15, show_sd=TRUE) |> axis5(xlim=15, dxlim=0.5)
draw_C(201,0, domain=15, show_sd=TRUE) |> axis5(xlim=15, dxlim=0.5)
draw_C(301,0, domain=15, show_sd=TRUE) |> axis5(xlim=15, dxlim=0.5)
draw_C(401,0, domain=15, show_sd=TRUE) |> axis5(xlim=15, dxlim=0.5)Which of these sequences correspond to the standard deviation at times 10, 20, 30, and 40?
“+\(\\sigma_{10} = 4.5, \\sigma_{20} = 6.4, \\sigma_{30} = 7.7, \\sigma_{40} = 9.0\)+”, “\(\\sigma_{10}= 4.5, \\sigma_{20} = 6.0, \\sigma_{30} = 7.5, \\sigma_{40} = 9.0\)”, “\(\\sigma_{10} = 4.5, \\sigma_{20} = 5.8, \\sigma_{30} = 7.1, \\sigma_{40} = 8.4\)”, “\(\\sigma_{10} = 4.9, \\sigma_{20} = 6.0, \\sigma_{30} = 7.9, \\sigma_{40} = 9.3\)”,
The standard deviation increases with time. Which one of these power-law relationships best corresponds to the standard deviations you measured off the graphs?
“\(\\sigma_t = k t\)”, “\(\\sigma_t = k t^2\)”, “+\(\\sigma_t = k \\sqrt{t}\)+”, “\(\\sigma_t = k t^{1.5}\)”
Essay: A more fundamental way to measure the increase in width of \(C(x, t)\) with time is to use the variance rather than the standard deviation. Describe briefly the very simple pattern that the variance of \(C(x, t)\) follows over time. (You don’t have to give a formula, just say what function it is.)
53.5 Random walk
The solution to diffusion differential equation gives the concentration of the diffusing particles \(C(x, t)\) at any \(x\) and \(t\). At any given value of \(t= t_1\), the shape of \(C(x,t=t_1)\) tends to a smooth bell-shaped curve: the gaussian function. The width of the gaussian is a function of \(t\). Conventionally, the width corresponds to the variance parameter \(\sigma^2\). This changes with \(t\) in a very simple way: \[\sigma(t)^2 = D t\]
Everything is smooth and nicely behaved. But this is an abstraction which summarizes the concentation of a theoretically infinite population of particles. Looking at the position of a single particle as a function of time gives a very different impression. The figure shows individually the trajectories of 50 (randomly selected) particles.
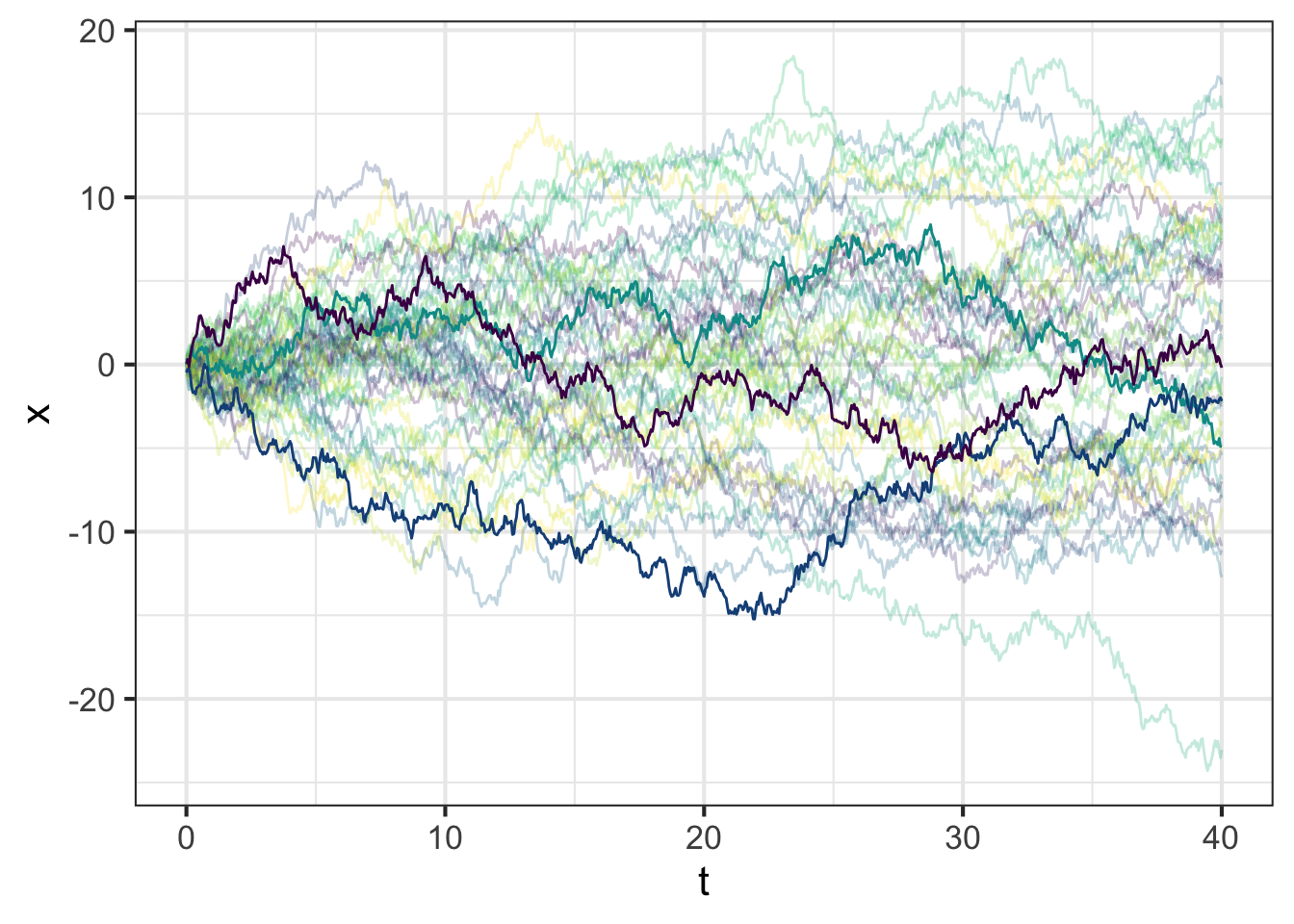
Do take note that the position of each particle in the pipe at time \(t\) is shown on the vertical axis.
Each of the trajectories is called a random walk, as if a walker were randomly taking steps forward or backward.
r insert_calcZ_exercise(“XX.XX”, “KktWcD”, “Exercises/Dynamics/fox-write-oven.Rmd”)
53.6 Investment volatility
When people invest money, they expect a return. Generally, the return is measured as a percentage per year. An \(r=10\%\) annual return—that is pretty high these days—means that at the end of the year your investment of, say, $500 will be worth $550. And remember, saying \(r=10\%\) is the same thing as saying \(r=0.10\).
Banks and such do things in discrete time, e.g. crediting your savings account with interest once a month. But this is calculus, so we focus on continuous time. (And, of course, Nature does things in continuous time!)
If \(S\) is the amount of money you have invested at a return of \(r\), the evolution of \(S\) over time is given by a familiar, linear differential equation: \[\dot{S} = r S\ \ \ \implies \ \ \ S(t) = S_0 e^{r t}\]
Quick review questions:
- Which of those two equations is the differential equation and which is the solution?
- What symbol is being used to stand for the “state” of the system?
- What is the form of the dynamical function of state?
- Is there a fixed point? If so, is it stable?
Investments in the stock market provide two types of return. We will focus on the return that comes from the changing price of the stock, which can go up or down from day to day. The other kind of return is dividends, the typically quarterly payment made by the company to stock holders. In investments, dividends should not be ignored, but we aren’t interested in them here.
Now imagine that you expect, for whatever reason, the stock price to go up by 2% per year (\(r=0.02\)) on average. Of course, the price is volatile so the 2% is by no means guaranteed. We will imagine the volatility is 25% per year.
This situation, which includes volatility, is modeled by a modification of differential equations called “stochastic differential equations.” (“Stochastic” comes from the Greek word for “aiming”, as in aiming an arrow at a target. You won’t necessarily hit exactly.) The math is more advanced and we will not go into details. Our point here is to warn you: Now that you are expert about (ordinary) differential equations, you need to be aware that things are somewhat different in a stochastic situation.
To that end, we will show you trajectories that follow the mathematics of stochastic exponential growth (with \(r=0.2\) per year and volatility \(\sigma = 0.25\) per year). On top of that, we will show in red the trajectory from (ordinary, non-stochastic) exponential dynamics \(\dot{S} = r S\). In blue, we will show the theoretical average stochastic dynamics. In all cases, we will set the initial condition to be \(S_0 = 100\). We will follow the trajectories for three years.
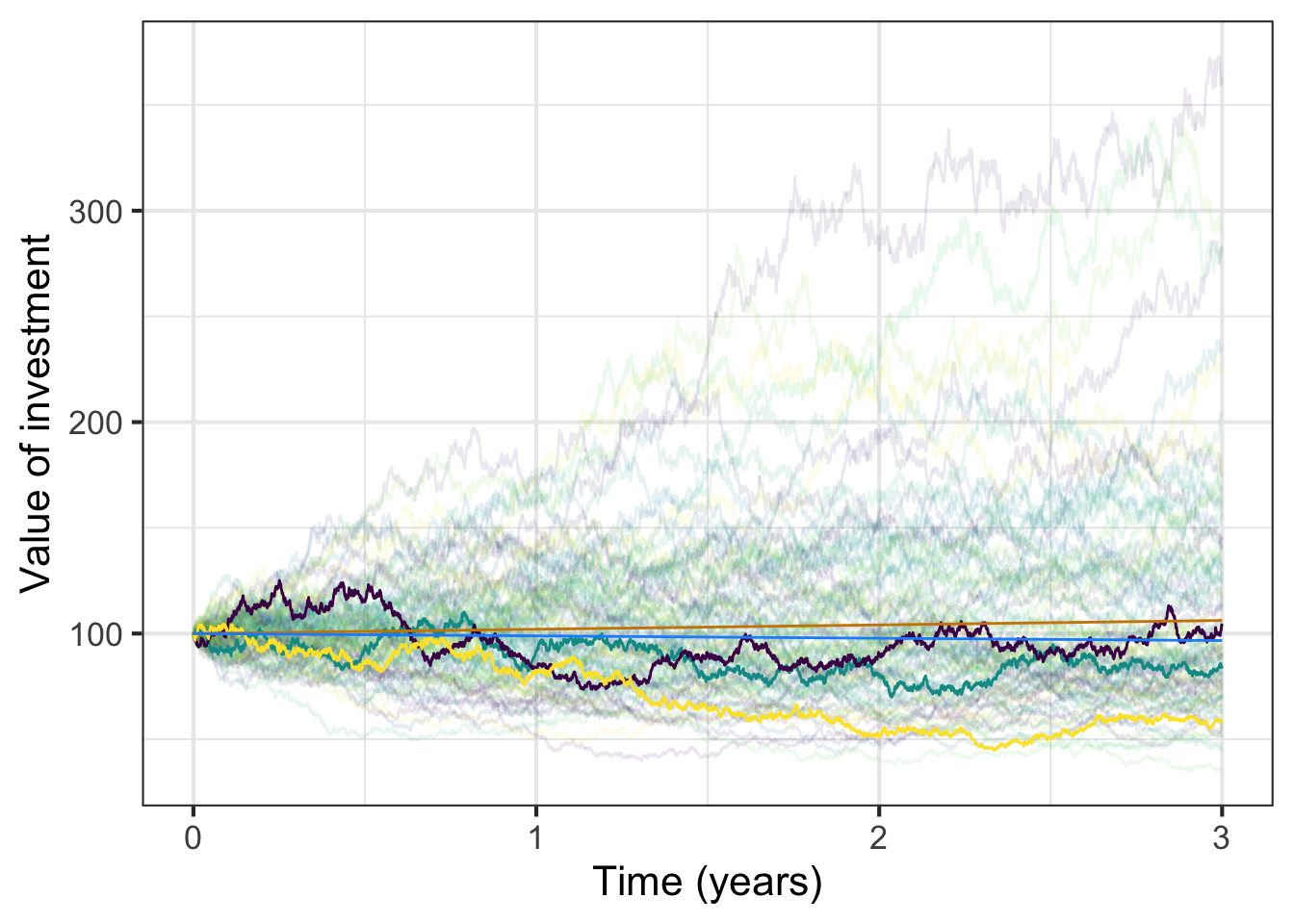
The eye is drawn to the trajectories leading to large returns. That is misleading. Although there are a few trajectories that show a 3-year return above 50% (that is, to $150 or higher) in fact the majority of trajectories fall below that of a purely deterministic \(r=2\%\) annual return exponential process. The volatility causes a decrease in the median return.
It is easy to understand why the stochastic shocks cause a loss in return. Consider a stock with an initial price of $100 that in two successive days goes up by 50% and down by 50%. These ups and downs should cancel out, right? that is not what happens:
\(\$100 \times 1.5 \times 0.5 = \$75\)
Some class notes in www/2021-03-31-classnotes.Rmd