8 Finding parameters for the basic modeling functions
Seen very abstractly, a mathematical model is a set of functions that represent the relationships between inputs and outputs.  900
900
At the most simple level, building a model can be a short process:
- Develop an understanding of the relationship you want to model. Often, part of this “understanding” is the pattern seen in data.
- Choose a function type—e.g. exponential, sinusoidal, sigmoid—that you think would be a good match to the relationship.
- Find parameters that scales your function to be able to accept real-world inputs and generate real-world outputs.
It’s important to distinguish between two basic types of model:
- Empirical models which are rooted in observation and data.
- Mechanistic models such as those created by applying fundamental laws of physics, chemistry, and such.
We are going to put off mechanistic models for a while, for two reasons. First, the “fundamental laws of physics, chemistry, and such” are often expressed with the concepts and methods of calculus. We are heading there, but at this point you don’t yet know the core concepts and methods of calculus. Second, most students don’t make a careful study of the “fundamental laws of physics, chemistry, and such” until after they have studied calculus. So examples of mechanistic models will be a bit hollow at this point.
We’ll start then with empirical modeling: finding functions that are a good summary of data. The process of constructing a model that is a good match for data is called curve fitting, or, more generally, fitting a model.
8.1 Variations from scaling
A good place to start building a model is to pick one of the basic modeling functions. This works surprisingly often. To remind you, here are our nine pattern-book functions: 910
| Pattern name | Traditional notation | R notation |
|---|---|---|
| exponential | \(e^x\) | exp(x) |
| logarithm (“natural log”) | \(\ln(x)\) | log(x) |
| sinusoid | \(\sin(x)\) | sin(x) |
| square | \(x^2\) | x^2 |
| proportional | \(x\) | x |
| constant | \(1\) | 1 |
| reciprocal | \(1/x\) or \(x^{-1}\) | 1/x |
| gaussian | \(\dnorm(x)\) | dnorm(x) |
| sigmoid | \(\pnorm(x)\) | pnorm(x) |
The basic modeling functions are the same, but replace the plain \(x\) in the pattern-book function with a straight-line function, for instance \(ax + b\) or, equivalently \(a(x - x_0)\). In use, the parameter \(a\) is often written with some other letter and, often, the \(b\) or \(-x_0\) part is not needed.
Here are some of the common forms of the basic modeling functions you will encounter:
| Name | Common forms | note |
|---|---|---|
| Exponential | \(e^{k t}\) or \(e^{-k t}\) or \(e^{-t/ \tau}\) | |
| Sinusoid | \(\sin\left(\frac{2 \pi}{P} (t-t_0)\right)\), \(\sin\left(\frac{2 \pi}{P} t\right)\), or \(\sin(\omega t)\) | \(P\) is “period,” \(\omega\) is “angular frequency.” |
| Monomials | \([x-x_0]\) or \([x-x_0]^2\), and so on | |
| Power-law generally | \(x^p\) or \([x-x_0]^p\) | \(p\) is “power.” |
| Gaussian | \(\dnorm(x, mean, sd)\) | Interpret “mean” as “center.” |
| Sigmoid | \(\dnorm(x, mean, sd)\) | \(sd\) is “standard deviation” or “spread.” |
It helps in making the selection to have ready to mind the basic shape of each of these function families. To review, revisit Section 2.4.
Remember also that, in general, we scale the inputs and scale the output. This means that in choosing a model family, we don’t have to worry at first about the numbers on the axes. (Of course, those numbers will be critically important later on in the process!) The scaling does, however, allow us to consider some variations on the shapes of the modeling functions. In particular, the input scaling lets us flip the shape right-for-left. And the output scaling lets us flip the shape top-for-bottom.
- \(f(t)\), basic shape
- \(f(-t)\), flipped right-for-left
- \(-f(t)\), flipped top-for-bottom
- \(-f(-t)\), flipped both top-for-bottom and right-for-left
For functions such as the sinusoid, flipping is not much use, since the flipped sinusoid curve is still a sinusoid, although with a shifted input. Similarly, a right-for-left flipped gaussian function has the same shape as the original. For the straight-line function, flipping of either sort accomplishes the same thing: changing the sign of the slope.
For the exponential function, the two possible types of flipping—right-for-left and top-for-bottom—produce four different curves, all of which are exponential, shown in Figure 8.1.
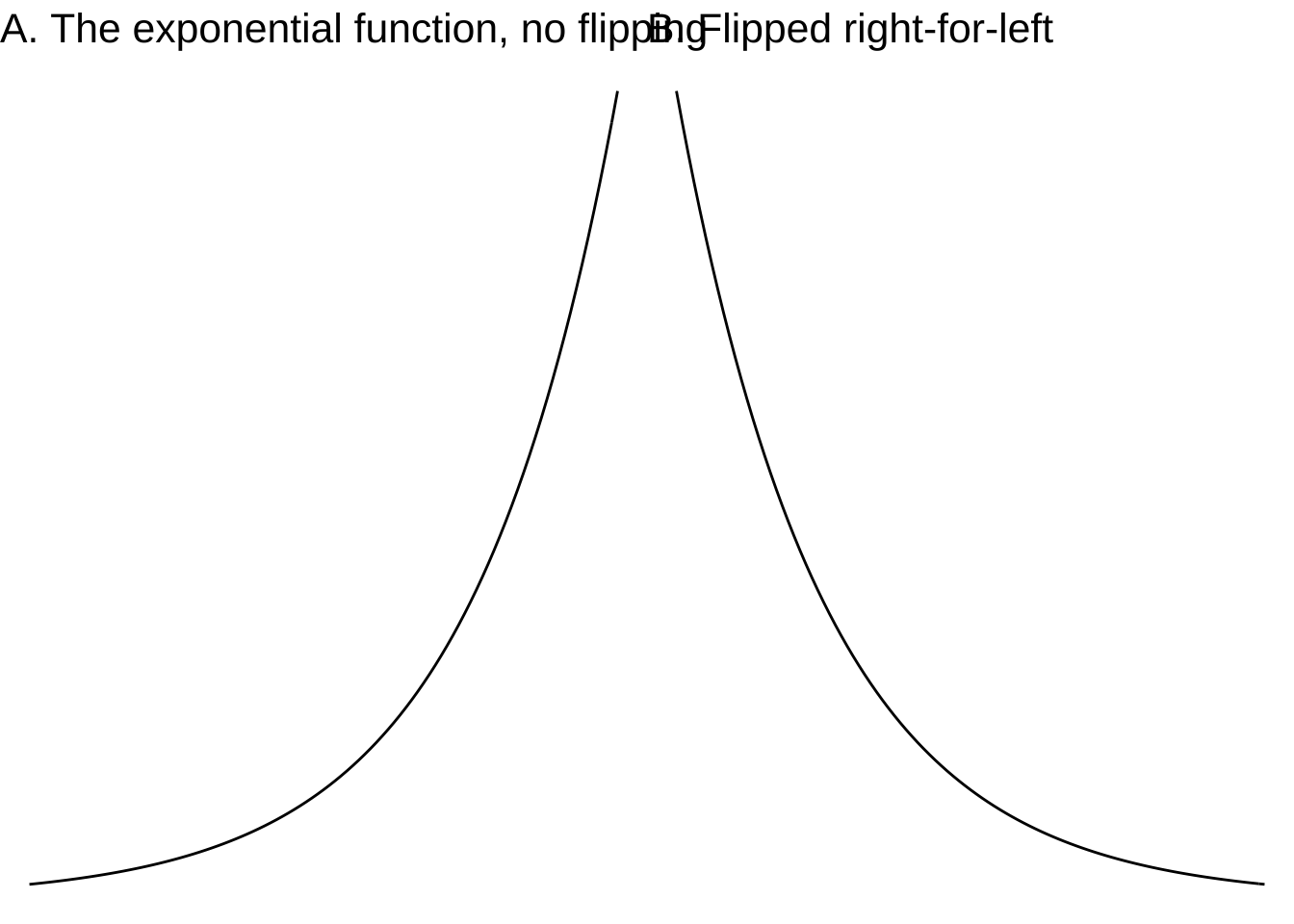
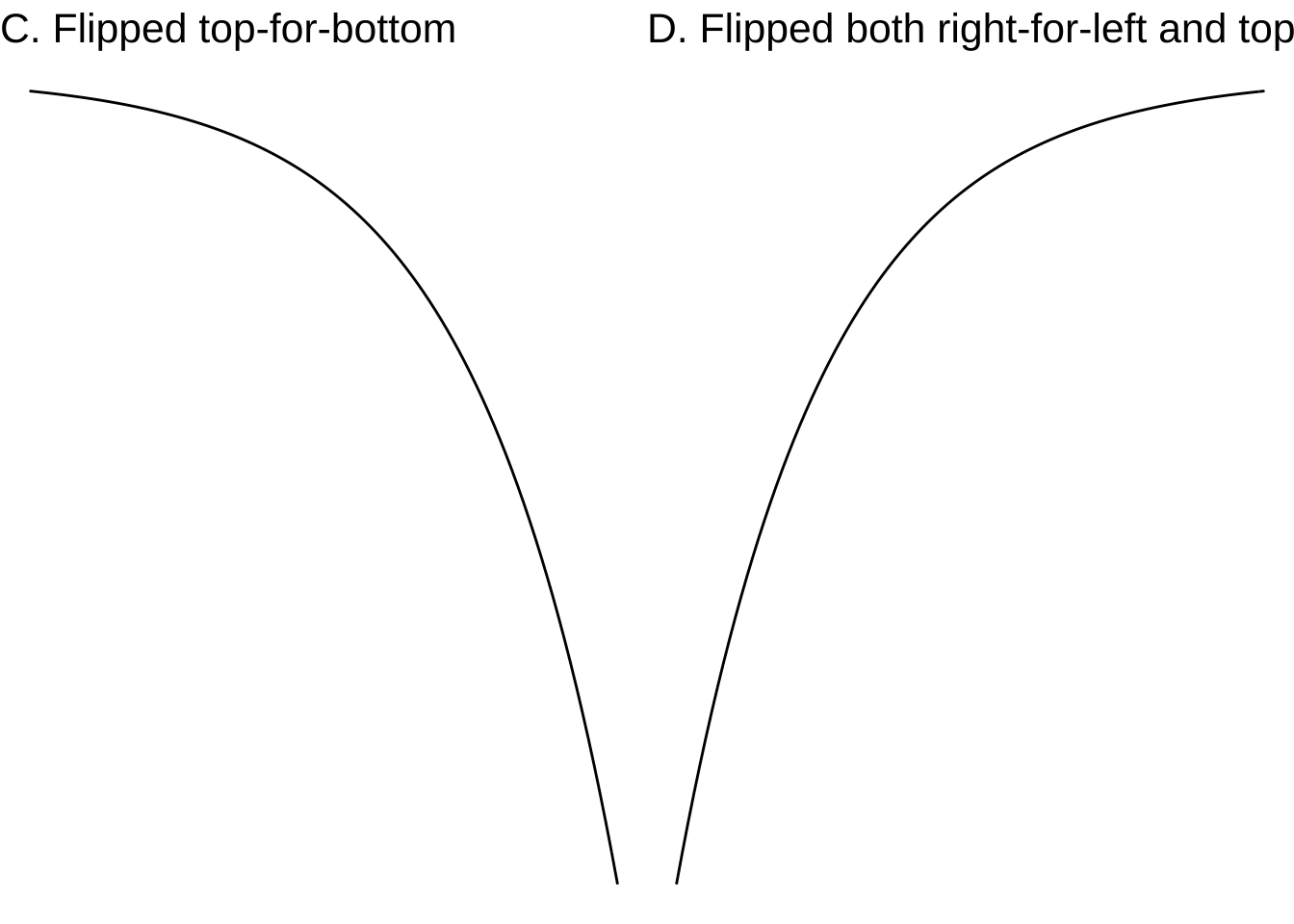
Figure 8.1: Four variations of the exponential function.
8.2 Curve fitting a periodic function
Figure 8.2 shows the tide level in Providence, Rhode Island, starting at midnight on April 1, 2020 and recorded every minute for four and a half days. (These data were collected by the US National Oceanic and Atmospheric Administration. Link) 960
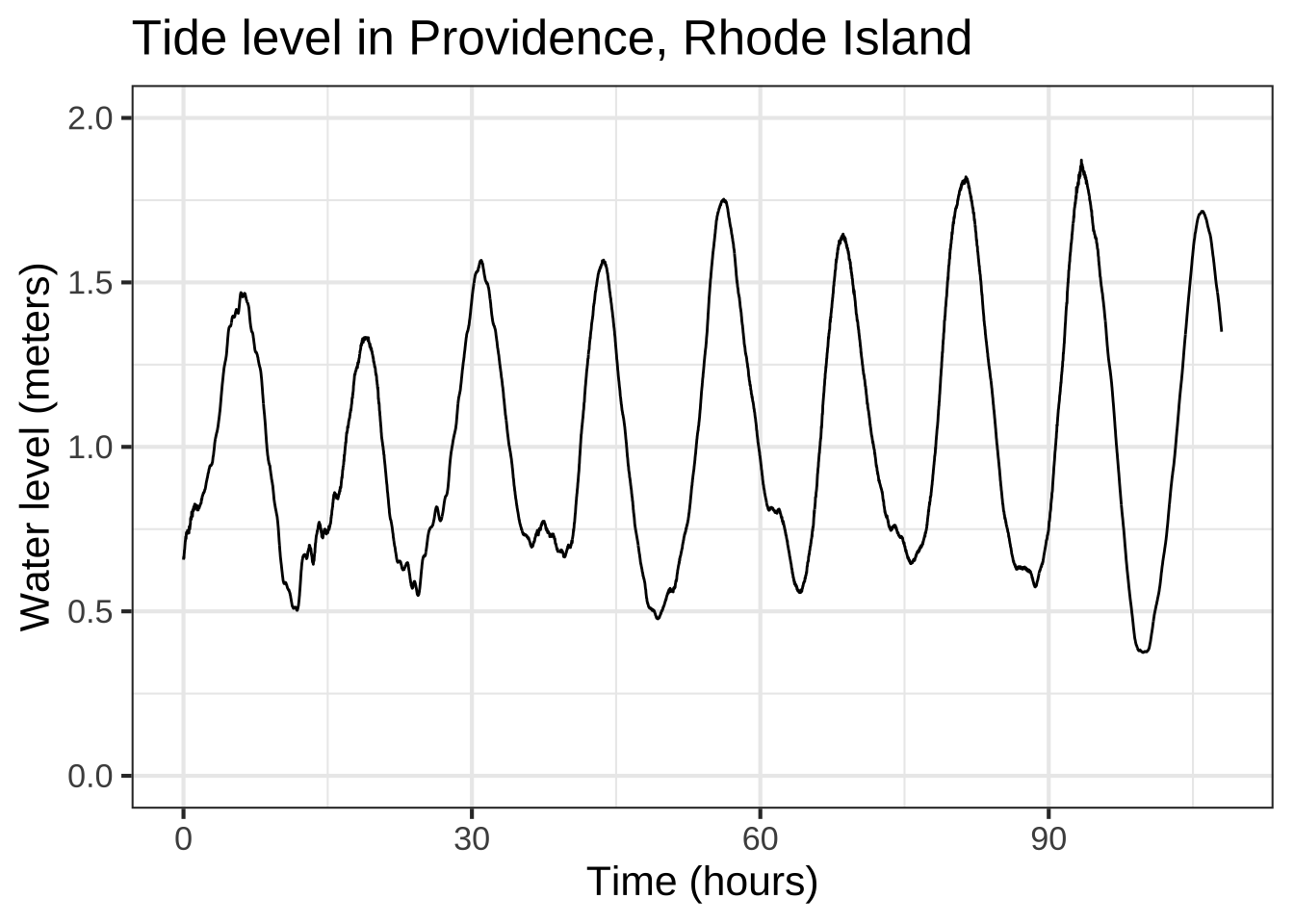
Figure 8.2: About four days of tide-level data from Providence, Rhode Island
It’s not too hard to see what’s going on. The tide rises and falls about every 12 hours. The difference between high tide and low tide is a little more than one meter. The tide gauge is calibrated so that a typical reading is 1 meter, although we don’t know what that is respect to. (Certainly not sea level, since then the typical reading would be around zero.)
This simple description tells almost everything needed to match a basic modeling function to the tide level. Given the clear pattern in the data, we’ll use a sinusoid, that is, a function of the form \[\text{tide}(t) \equiv A \sin(2\pi t/P) + B\] The procedure is straightforward:
Step 0: Determine whether a sinusoid model is appropriate. As you know, sinusoids oscillate up and down repeatedly with a steady period. That certainly seems the case here. But sinusoids are also steady in the peak and trough values for each cycle. That’s only approximately true in the Providence data. Models inevitably involve approximation. We’ll have to keep an eye on whether modeling with sinusoids and their fixed amplitude still lets us extract useful information.
Step 1: Choose a sensible value to represent the low point repeatedly reached. 0.5 m seems appropriate here, but obviously the exact position of the trough of each cycle varies over the 4.5 day duration of the data. Similarly, the peak is near 1.6 m. Parameter \(B\) is the mean of the peak and trough values: \(\frac{1.6 + 0.5}{2} = 1.05\) m here. Parameter \(A\) is half the difference between the peak and trough values: \(\frac{1.6 - 0.5}{2} = 0.55\). Parameter \(B\) is called the baseline of the sinusoid. Parameter \(A\) is the amplitude. (Note that by convention, the amplitude is always half the high-to-low range of the sinusoid.)
Step 2: Estimate the period \(P\) of the sinusoid. This can be done with the horizontal axis scale: measure the horizontal duration of a complete cycle. I like to use the time between peaks, but the time between troughs would work just as well. Another good choice is the time between positive sloping crossings of the baseline. (But be careful. The time between successive baseline crossings, one positive sloping and the other negative, give just half the period.)
On the scale of the above plot, it’s hard to read off the time of the first peak. So, zoom in until it becomes more obvious.
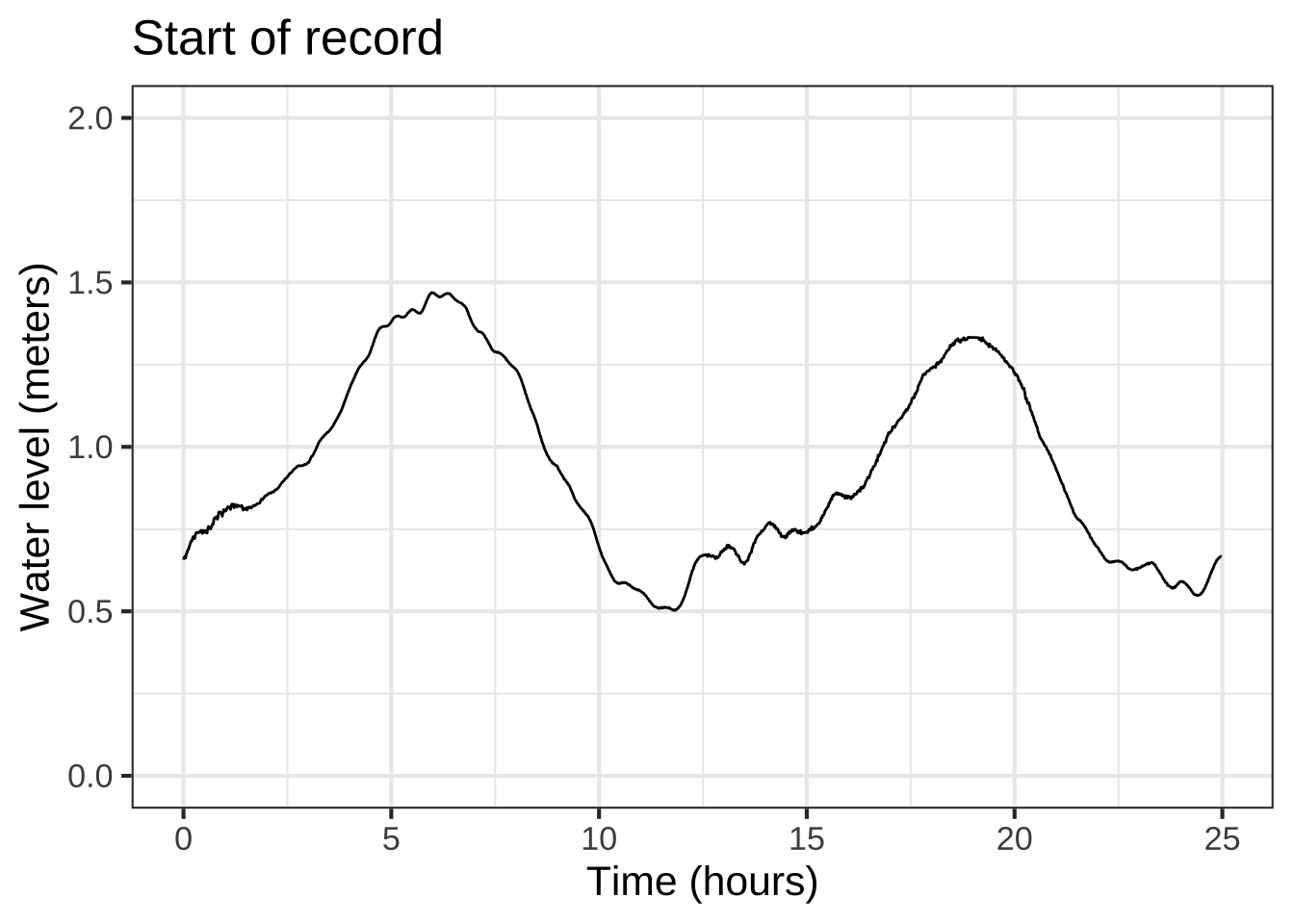
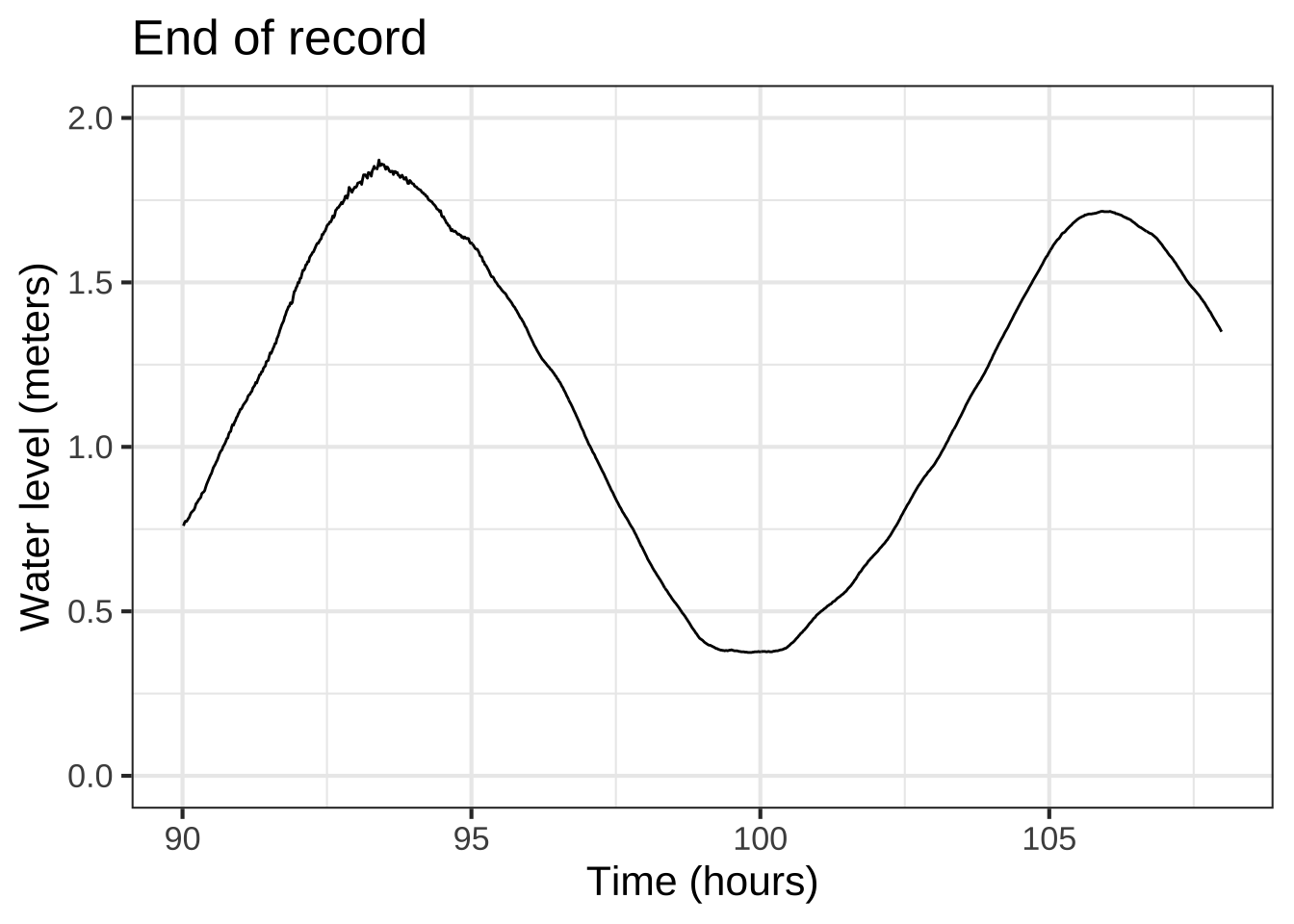
Figure 8.3: Zooming in on the start of the data (left) and on the last part of the data (right).
The left panel in Figure 8.3 shows about 24 hours at the start of the record. The first peak is at about 6 hours, the second at about 19 hours. That indicates that the period is roughly 19 - 6 = 13 hours.
Step 3 Plot out the model over the data. Replacing the symbols \(A\), \(B\), and \(P\) with our estimates, the model is
\[{\color{magenta}\text{tide}(t) \equiv 1.05 + 0.55 \sin(2\pi t/13)}\]
Figure 8.4 shows this model in \(\color{magenta}\text{magenta}\).
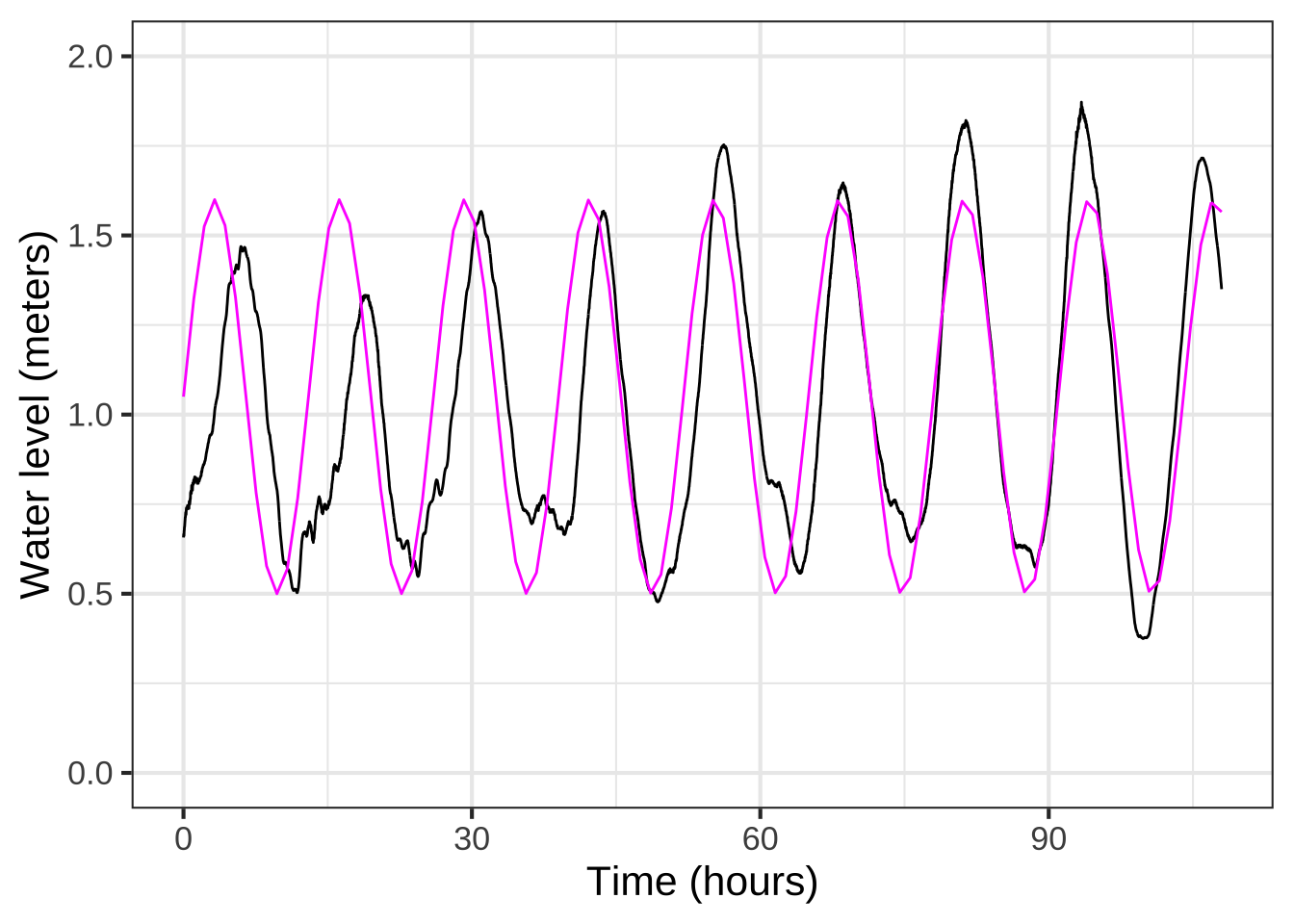
Figure 8.4: The sinusoid fails to align with the timing of peaks and troughs.
Figure 8.4 shows the model aligning beautifully with the data at around time 80 hours, but not so well near the very beginning of the record. Looking carefully, you can see the magenta peak gradually move to the left compared to the data as you look at the peaks of the cycles one at a time moving backward from \(t=80\) hours. This is diagnostic of our 13-hour estimate for the period being a little too long.
A good way to refine the estimate is to change the model slightly and re-graph the data and model. Keep doing this until you have found the right alignment. In other words, parameter estimation is often an iterative process of estimate-and-refine. This is one of the aspects of the modeling cycle, where a modeler builds a tentative model, looks for systematic deviations from the data, and refines the model.
Another sort of deviation of the model from the data seen in Figure 8.4 concerns the varying heights of the peaks and troughs in the data, which is not captured by the simple sinusoid pattern. Perhaps you can see that at the beginning of the record, the troughs are also wider than the peaks. Later on, as this extra width disappears, the amplitude of the peaks and troughs increases.
You don’t yet have the calculus tools or experience to know how or whether this phenomenon can be modeled. For now, a hint: Earth has two large orbiting bodies, the Sun and the Moon. These have slightly different periods: 24 hours for the Sun and slightly longer for the Moon.
Step 4 Our model omitted one of the parameters of the sinusoid basic modeling function: the time shift \(t_0\). A more complete model would be: \[\text{tide}_\text{shifted}(t) \equiv A \sin(2\pi (t - t_0)/P) + B\] Whether including this parameter is important depends on our purpose for the model. If the goal is to find the period of the tides, the time shift hardly matters. But if the goal is to predict a future tide level, the time shift is critical.
Estimating \(t_0\) can only be done once the period \(P\) is known precisely. In practice, as you’ll see in Chapter 14, we use a numerical method called polishing to estimate both \(P\) and \(t_0\) at the same time.
8.3 Curve fitting an exponential function
The exponential function is particularly useful when the quantity we want to model shows constant proportional increase. Many quantities in everyday life are this way. For instance, an increase in salary is typically presented in a format like “a 3% increase.” The population growth of a country is often presented as “percent per year.” Inflation in the price of goods is similarly described in percent per year. Interest on money in a bank savings account is also described as percent per year. But if you have the bad fortune to owe money to a loan shark, the proportional increase might be described as “percent per month” or “percent per week.” 920
When you know the “percent increase per time” of a quantity whose initial value is \(A\), the exponential function is easy to write down: \[f(t) = A (1+r)^t\] The number \(r\) is often called the interest rate or discount rate and is given in percent.
Regrettably, it’s extremely easy and common to forget the rules for addition with percent. If \(r = 5\%\), then \((1+r) = 1.05\), not 6. Always keep in mind that \(5\%\) means \(\frac{5}{100}\).
Another source of error stems from the tradition in mathematics of using the number \(e=2.718282\) as the “natural” base of the exponential function, whereas in \(f(t) = A (1+r)^t\) the base is \(1+r\).
You can translate an exponential \(b^t\) in any base \(b\) to the “natural” base. This is just a matter of calculating the appropriate parameter \(k\) such that \(e^k = b\). Using logarithms, \[e^k = b\ \ \implies \ \ k=\ln(b)\] For instance, if \(r=5\%\) per year, we’ll have \(k = \ln(1+r) = \ln(1.05) = 0.488\) per year.
Almost everybody is happier doing arithmetic with numbers like 2 and 10 rather than \(e=2.718282\). For this reason, you may see formulations of the exponential function as \(g(t) \equiv 2^{a t}\) or \(h(t) \equiv 10^{c t}\). Remember that \(2^{a t}\) and \(e^{at}\), although both exponential functions, are quantitatively different. If you want to write \(2^{at}\) using the “natural” base, it will be \(e^{\ln(2) a\, t }\). Similarly, \(10^{ct} = e^{\ln(10) c\, t}\).
Exponential functions also describe decrease or decay. Just replace \(t\) with \(-t\). That is, a movie of a decreasing quantity is just the movie of an increasing quantity played backwards in time! 930
Figure 8.5 shows some data collected by Prof. Stan Wagon to support his making a detailed mechanistic model of an everyday phenomenon: The cooling of a mug of hot beverage to room temperature. The mug started at room temperature, which was measured at 26 degrees C. At time 0 he poured in boiling water from a kettle and measured the temperature of the water over the next few hours.
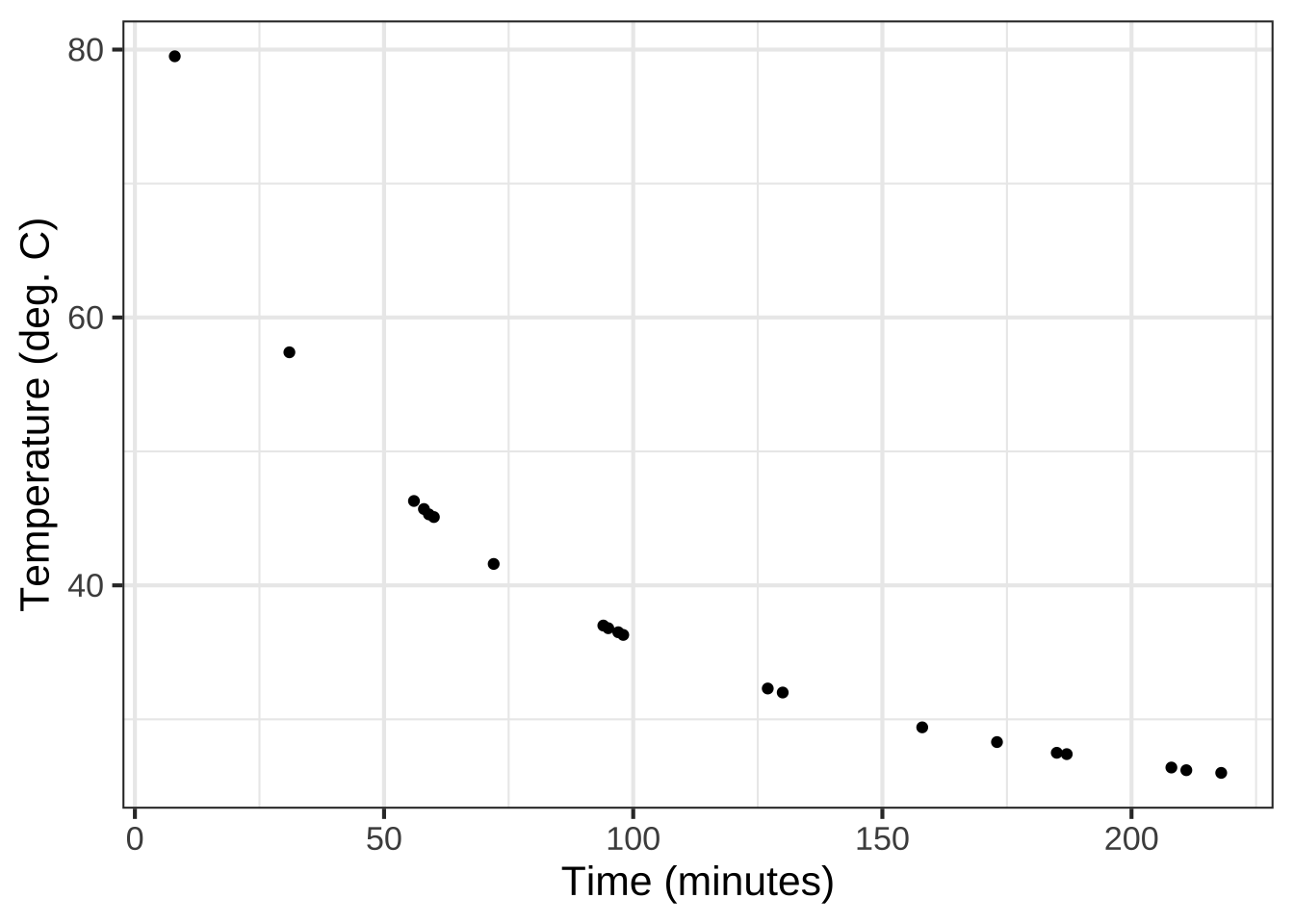
Figure 8.5: Stan’s data
Our task is to translate this data into the form of a function that takes time as input and returns temperature as output. Such a model would be useful for, say, filling in the gaps of the data. For instance, we might want to find the temperature of the water immediately after being poured from the kettle into the mug.
Looking at the data, one sees that the temperature decreases along a curve: cooling fast at first and then more slowly. This is the pattern of the flipped right-for-left exponential. (Figure 8.1(B)) We can imagine then that an exponential, \(A e^{kt} + C\) will be a suitable model form for the cooling water.
What remains is to find the parameters \(A\), \(k\), and \(C\). Here is a general process for curve-fitting an exponential. Later, we’ll apply this process specifically to the water-cooling situation.
General process for curve-fitting an exponential
The goal is to find the parameters \(A\), \(k\), and \(C\) in the formula \(A e^{kx} + C\).
Step 0: Check that the data show an exponential pattern in one of its varieties, namely a smooth increase or decrease and leveling out beyond some value of \(x\). If this isn’t true, reconsider whether you should be using an exponential function in the first place. Using your mind’s eye (or paper, if you like) sketch out an exponential-shaped curve that follows the overall trend of the data. We’ll call this imagined curve \(f(x)\).
Step 1: Find the baseline. This is the output level at which the function has a horizontal asymptote, that is, at which the function levels off. \(C\) is this baseline level.
Step 2: Find the numerical value of the imagined function \(f()\) at input \(x = 0\). We’ll call this value \(f(0)\). Then \(A \equiv f(0) - C\).
Step 3 Estimate parameter \(k\) using these steps:
Pick any input value, which we’ll call \(x_2\), such that \(f(x_2)\) is far from the baseline.
Find an input value, which we’ll call \(x_1\) such that \(f(x_1)\) is halfway14 between the baseline \(C\) and \(f(x_2)\), that is \[f(x_1) = \frac{f(x_2) + C}{2}\]
Once you have \(x_1\) and \(x_2\), you can immediately find \(k\): \[k = \frac{\ln(2)}{x_2 - x_1} \approx \frac{0.693}{x_2 - x_1}\]
Using this simple test to double-check your work. If the horizontal asymptote of \(f()\) (that is, approach to the baseline) is for \(x \rightarrow \infty\), then \(k\) should be negative. If the horizontal asymptote is for \(x \rightarrow - \infty\), then \(k\) will be positive.
Notice that the question of “growth or decay” depends only on the sign of the parameter \(k\). You can have an exponentially decaying process that’s increasing. Consider, for instance, the speed of a car as it merges onto a highway from a slow speed on the entrance ramp. The car’s velocity is increasing, but as you approach highway speed the rate of increase gets smaller. That’s exponential decay.
The procedure in Step 3 for estimating \(k\) stems from a very important property of exponential functions: Exponential functions always double/half at a constant pace. By design, the parameter \(k\) directly determines that pace. Picking an \(x_2\) and finding the corresponding \(x_1\) gives the length of the input interval, \(x_1 - x_2\) over which the distance from the baseline doubles/halves.
What’s remarkable about the doubling/halving time is that, for a genuinely exponential function, it doesn’t matter which point we choose for \(x_1\). In practice working with graphed data, it’s best to choose so that \(f(x_1)\) is discernibly far from the baseline.
The \(2\) in \(\ln(2)\) corresponds to idea of doubling/halving. The logarithm converts \(2\) to a scale that will generate 2 when exponentiated.
Step 4 If you can plot the data, do so. Add to that a graphics layer showing the function \(A e^{k x} + C\) using the values for \(A\), \(C\), and \(k\) that you just found. If you are not satisfied with the way the plotted function approximates the data, tweak the parameters a bit until you are.
Exponential curve fitting applied to the water-cooling data
Let’s illustrate the general process on the water-cooling data, redrawn in Figure 8.6. 950
## `geom_smooth()` using method = 'loess'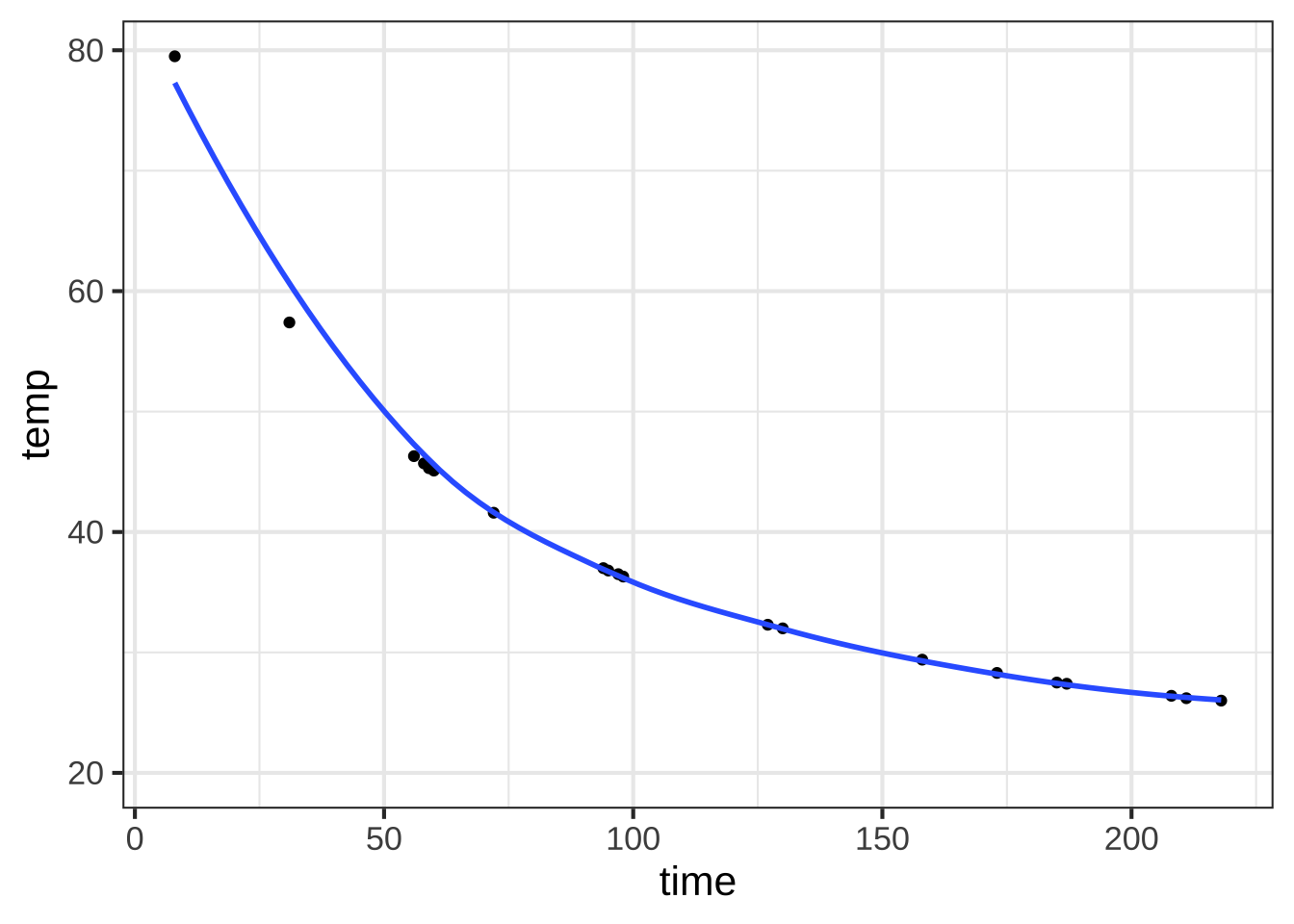
Figure 8.6: The cooling-water data, repeated here for convenience. We’ve sketched in an exponential-like curve that matches the data pretty well.
Step 0: The data indicate a smooth curve. As \(t\) gets large, the curve approaches a constant. So an exponential model is reasonable.
Step 1: The curve looks like it’s leveling out at a temperature of about 25 degrees C for large \(t\). So \(C \approx 25^{\circ} \text{C}\).
Step 2: Looking at our imagined curve (sketched in blue in Figure 8.6), it appears to intersect the \(t=0\) vertical axis at about \(f(0) = 85^\circ\text{C}\). Thus, \[A = 85^\circ\text{C} - 25^\circ\text{C} = 60^\circ\text{C}\]
Step 3:
- Now choose a time \(t_2\) where \(f(t_2)\) is far from the baseline. … It looks like \(t_2 = 25\) will do the job, at which point we can read off the graph that the function value is \(f(25) \approx 65\).
- Find an input value \(t_1\) such that \(f(t_1) -C = (f(t_2)-C)/2.\) This tells us that \(f(t_1) = 25 + (65-25)/2 = (65+25)/2 = 45\). Referring to the graph, the time at which the function is about 45 is \(t_1 \approx 65\), that is, \(f(t_1) \approx 65\).
- We have \(t_1 \approx 65\) and \(t_2 = 25\). From this, we calculate \(k\): \[ k = \frac{\ln(2)}{25 - 65} = 0.693/(-40) = -0.0173\]
- The data show exponential decay, so we expect \(k\) to be negative. Happily, it is. If it hadn’t been, we would go back to look for a sign error someplace.
Step 4. Graph the function on top of the data to confirm the fitted function is a good match to the data.
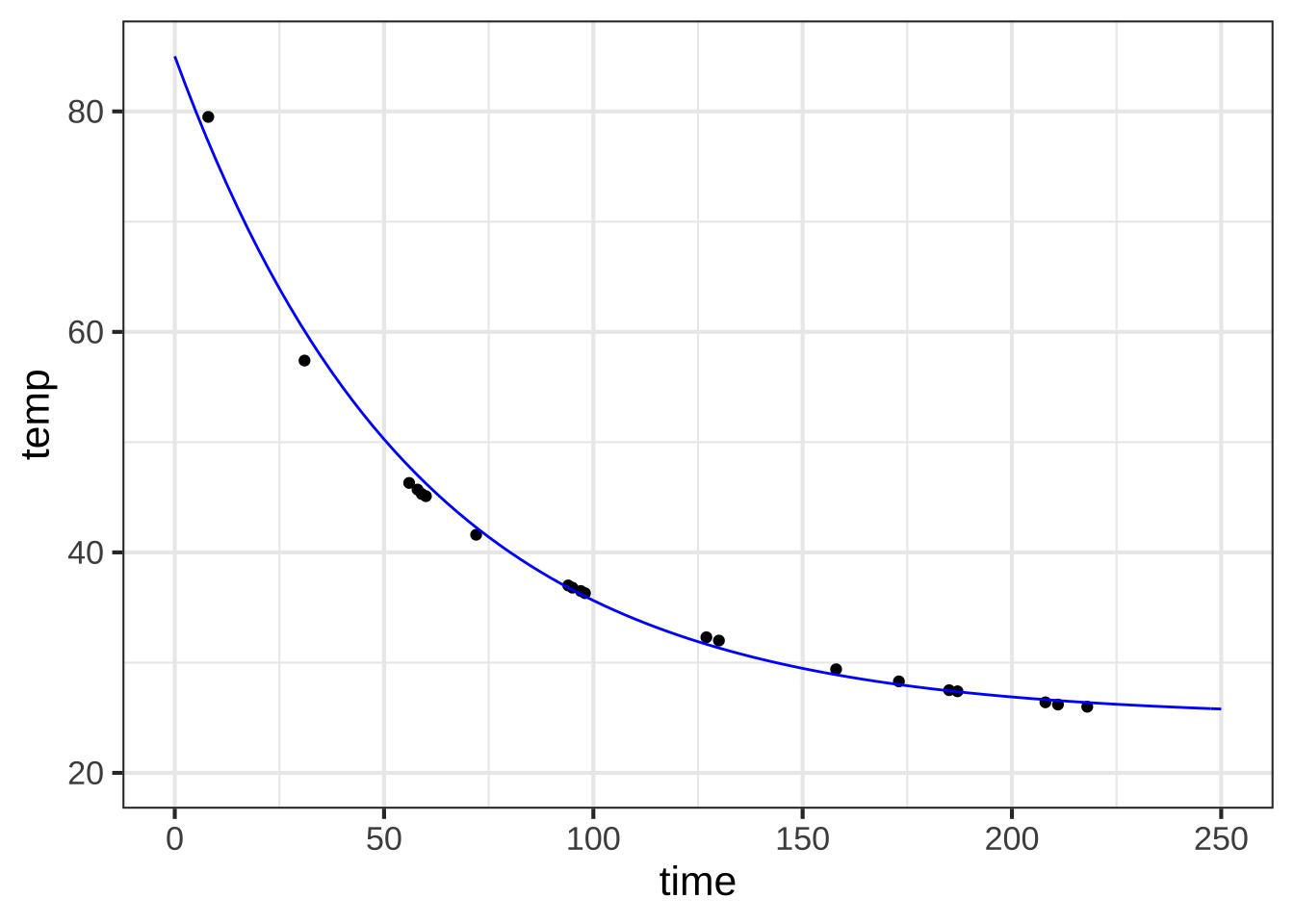
Figure 8.7: An exponential function that roughly aligns with the data.
Step 5: The flat zone of the data is to the right. So we’ve got exponential decay and \(k < 0\).
8.4 Curve fitting a power-law function
You have been using power-law functions from early in your math and science education. Some examples: 970
| Setting | Function formula | exponent |
|---|---|---|
| Circumference of a circle | \(C(r) = 2 \pi r\) | 1 |
| Area of a circle | \(A(r) = \pi r^2\) | 2 |
| Volume of a sphere | \(V(r) = \frac{4}{3} \pi r^3\) | 3 |
| Distance traveled by a falling object | \(d(t) = \frac{1}{2} g t^2\) | 2 |
| Gas pressure versus volume | \(P(V) = \frac{n R T}{V}\) | \(-1\) |
| … perhaps less familiar … | ||
| Distance traveled by a diffusing gas | \(X(t) = D \sqrt{ \strut t}\) | \(1/2\) |
| Animal lifespan (in the wild) versus body mass | \(L(M) = a M^{0.25}\) | 0.25 |
| Blood flow versus body mass | \(F(M) = b M^{0.75}\) | 0.75 |
One reason why power-law functions are so important in science has to do with the logic of physical quantities such as length, mass, time, area, volume, force, power, and so on. We’ll discuss this at length later in the course and the principles will appear throughout calculus.
As for finding the power law \(f(x) \equiv A x^p\) that provides a good match to data, we’ll need some additional tools to be introduced in Chapter 15.
8.5 Gaussian and sigmoid functions
Our last two basic modeling functions express an important idea in modeling: localness. To put this in concrete terms, imagine creating a function to depict the elevation above sea level of a long road as a function of distance in miles, \(x\), from the start of the road. If the road were level at 1200 feet elevation, a sensible model would be \(\text{elevation}(x) = 1200 \text{ft}\). If the road were gently sloping, a better model would be \(\text{elevation}(x) = 1200 + 0.01 x\). 980
Now let’s add a bump to the road. A bump is a local feature, often only a few feet wide. Or, perhaps the road is crossing a mountain range. That’s also a local feature, but unlike a bump in the road a mountain range extends for many miles.
The basic modeling function suited to represent bumps in the road, or potholes, or mountain ranges is generically called a “hump function.” In this book, we use a specific hump function called the gaussian function (dnorm()).
A gaussian function has two parameters: the location15 of the peak, which we’ll call the center parameter, and the sideways extent of the gaussian, which is called the standard deviation. Figure 8.8 shows a few gaussian functions with different parameters.
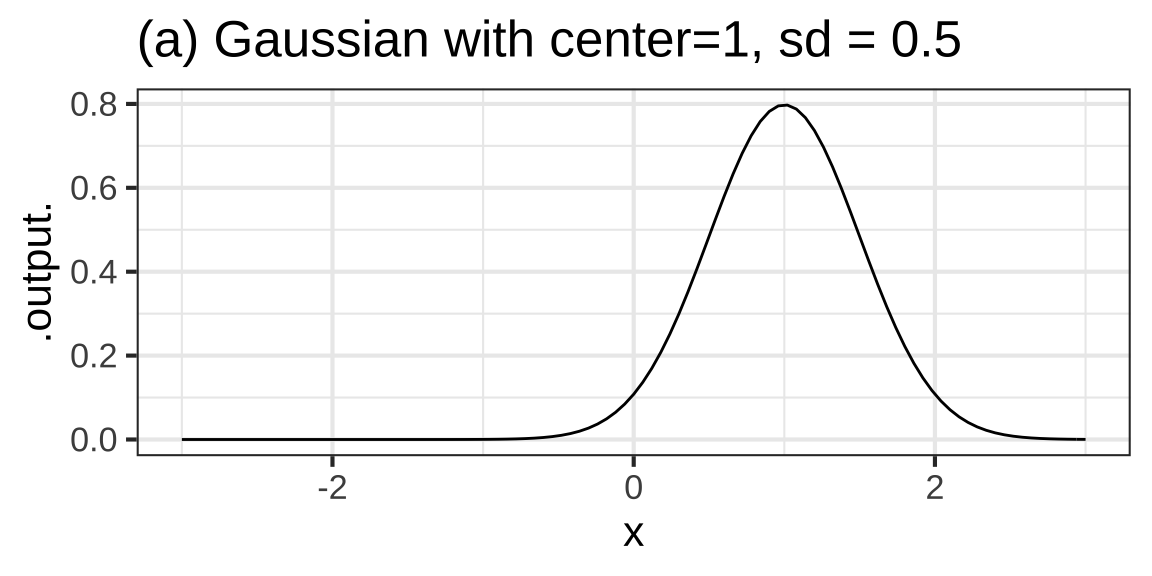
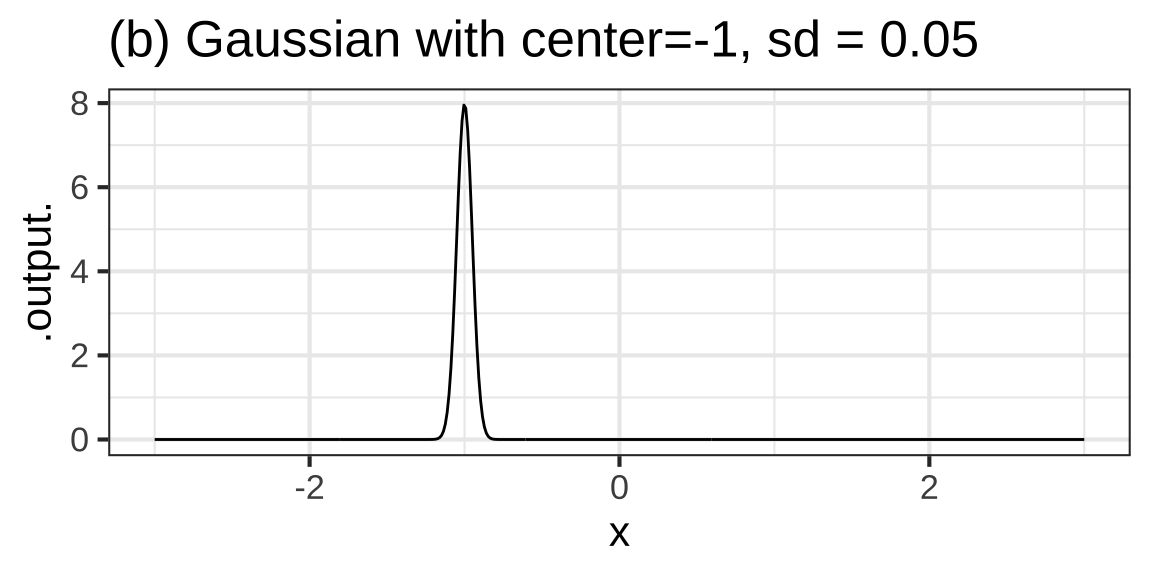
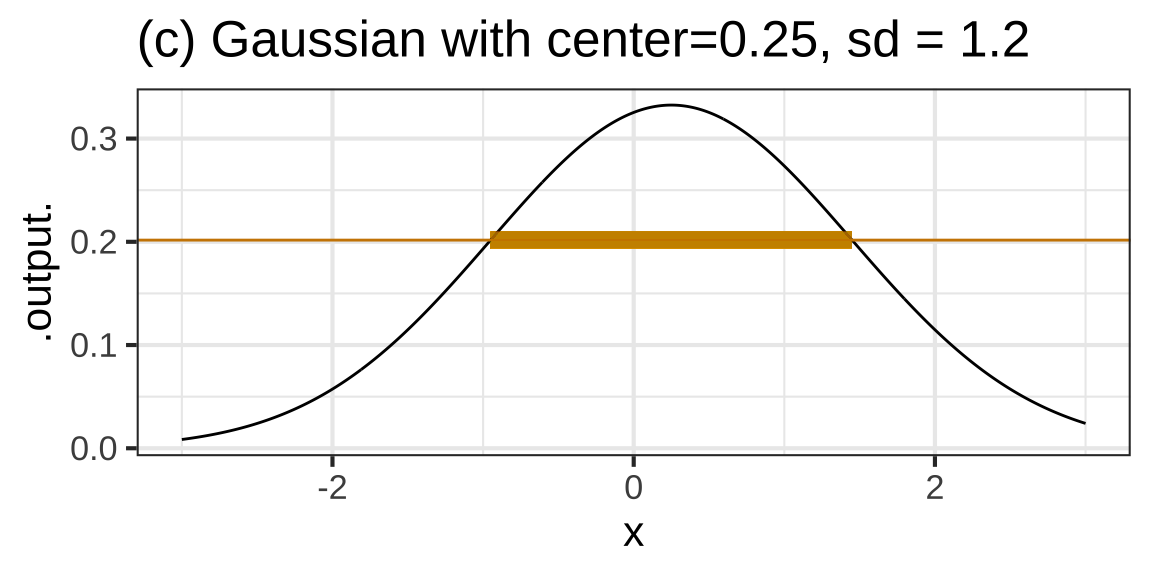
Figure 8.8: Gaussians with various centers and standard deviations (sd).
It’s easy to read off the center parameter from a graph of a gaussian. It’s the location of the top of the function graph. (We mentioned before that a mathematical word for “the location of the top” is argmax; the value for the input of the function that produces the maximum output.)
The spread parameter is also pretty straightforward, but you first have to become familiar with an unusual feature of the gaussian function. The output of the gaussian far from the center is practically zero. But it is not exactly zero. You can see from the graphs that the gaussian function has long flanks which approach zero output more or less in the manner of an exponential function. This means that we can’t measure the spread of the gaussian function by the distance between the zeros on either side of the peak. Instead, we need a convention that will allow us to be precise in quantifying what is admittedly a vague concept of width.
Technically, the convention is that the spread is the length of the interval from the argmax to the inflection point. This can be hard to judge from a graph, but a reasonable approximation is that the spread is the “half-width at half-height.” Come down half-way from the peak value of the output. Panel (c) of Figure 8.8 marks that elevation with a thin, tan, horizontal line. Along that line, measure the width of the gaussian, as marked by the thick tan line in Panel (c). The spread parameter is half the width of the gaussian measured in this way. 990
If you have a keen eye, you’ll notice that the tan line in Figure 8.8 is not exactly half-way down from the peak. It’s down 39.35% from the peak. This corresponds exactly to the technical convention.
Another seeming oddity about the gaussian function is the value of the maximum. It would have seemed natural to define this as 1, so-called “unit height.” The way it actually works is different: the maximum height is set so that the area under the gaussian function is 1.
This business with the area will make more sense when you’ve learned some calculus tools, specifically “differentation” and “integration.” For now though …
Consider another road feature, a local change from one elevation to another as you might accomplish with a ramp. The basic modeling function corresponding to a local change from one level to another is the sigmoid function. Figure 8.9 shows three sigmoid functions.
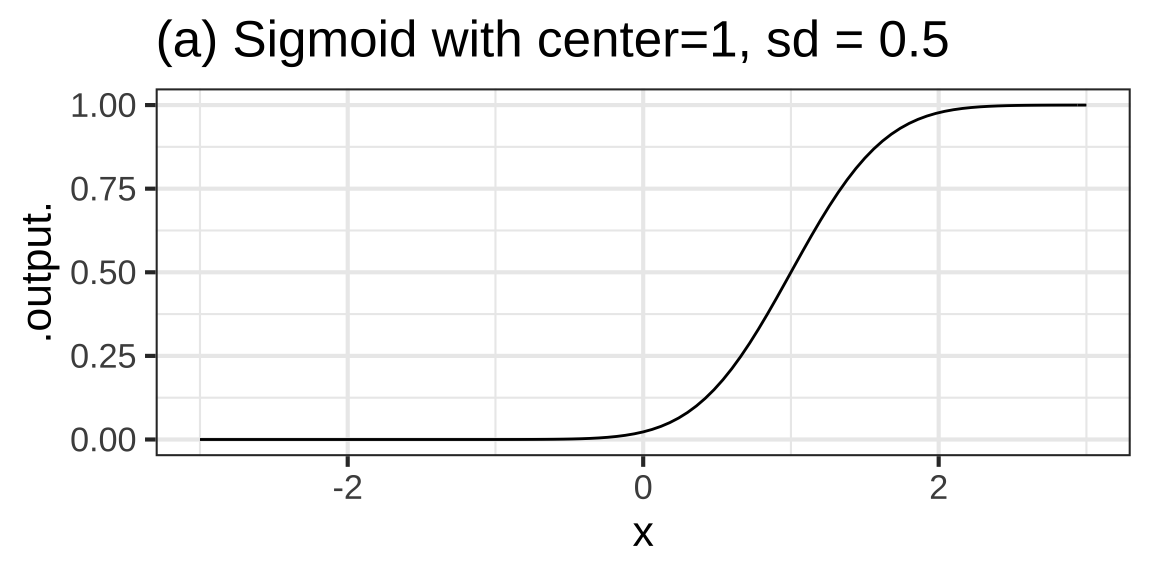
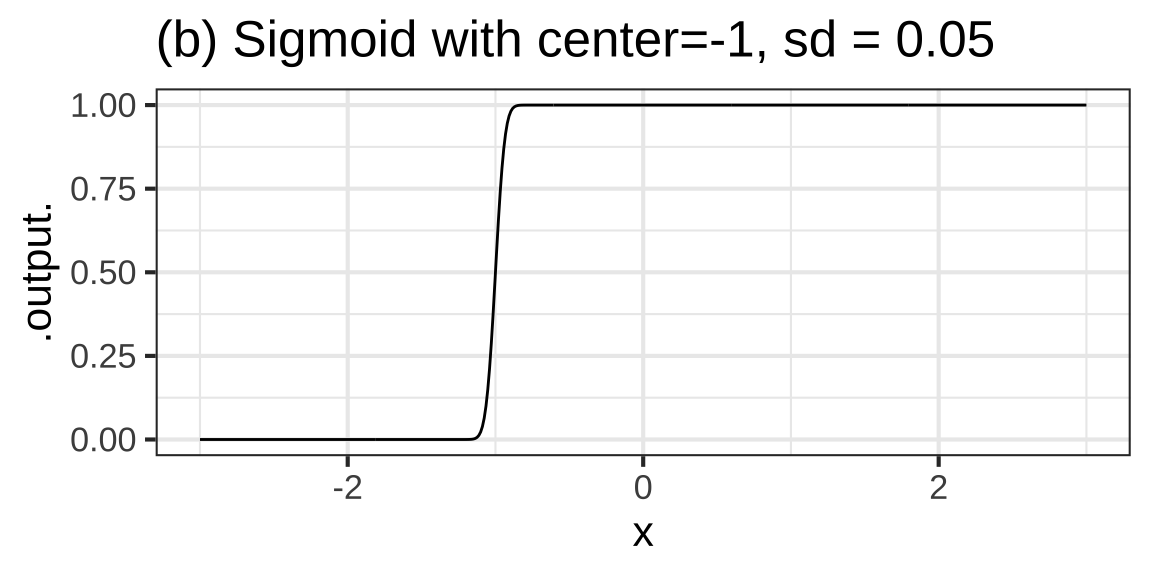
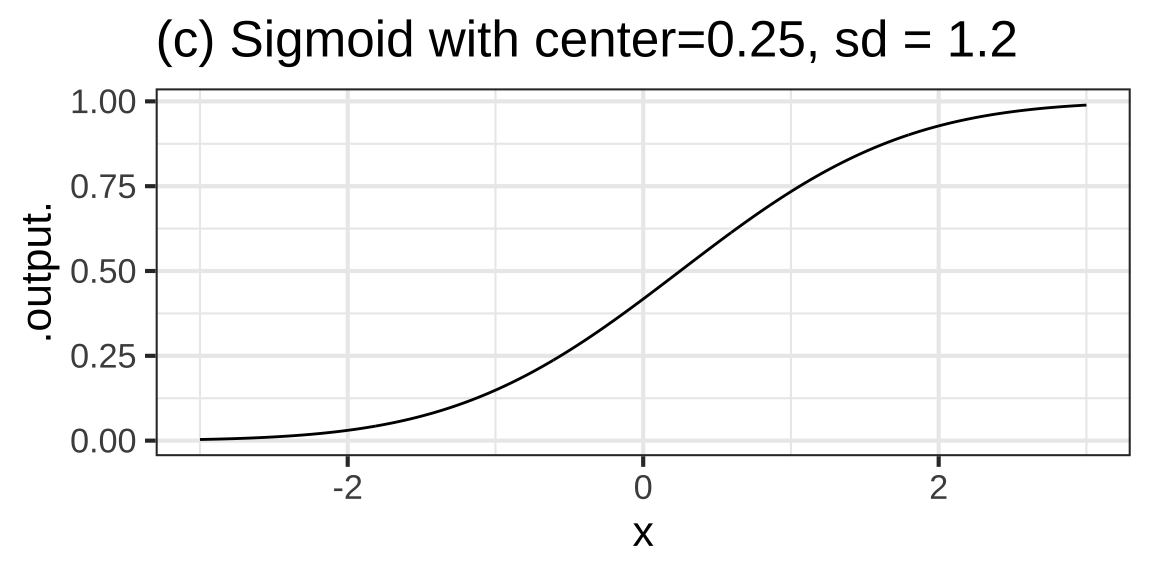
Figure 8.9: Sigmoids with various centers and standard deviations
 ).
).The parameters of the sigmoid function are the same as for the gaussian function: center and width. The center is easy to estimate from a graph. It’s the value of the input that produces an output of 0.5, half-way between the max and min of the sigmoid. As with the gaussian function, the width is measured according to a convention. The width is the change in input needed to go from an output of 0.5 to an output of 0.8413. This use of 0.8413 must seem loony at first exposure, but there is a reason. We’ll need more calculus tools before it can make sense.
Gaussian functions and sigmoid functions with the same center and width parameters have a very close relationship. The instantaneous rate of change of the sigmoid function is the corresponding gaussian function. Figures 8.8 and 8.9 show corresponding gaussian and sigmoid functions. To the very far left, the sigmoid function is effectively flat: a slope near zero. Moving toward the center the sigmoid has a gentle slope: a low number. In the center, the sigmoid is steepest: a higher number. Then the slope of the sigmoid becomes gentle again before gradually falling off to zero. Near zero, then low, then higher, then low again, then falling off to zero: that’s also the description of a gaussian function!
In R, the name of the sigmoid function is pnorm(). The gaussian is dnorm(). The parameters that specify center and spread are named mean and sd. The word “mean” accurately conveys the idea of “center.” It would be nice to be able to say that sd comes from spread, but in fact sd is short for standard deviation, a term familiar to students of statistics. 1000
Figure 8.10 shows the cumulative number of Ebola cases during an outbreak in Sierra Leone from May 1, 2014 to December 16, 2015.
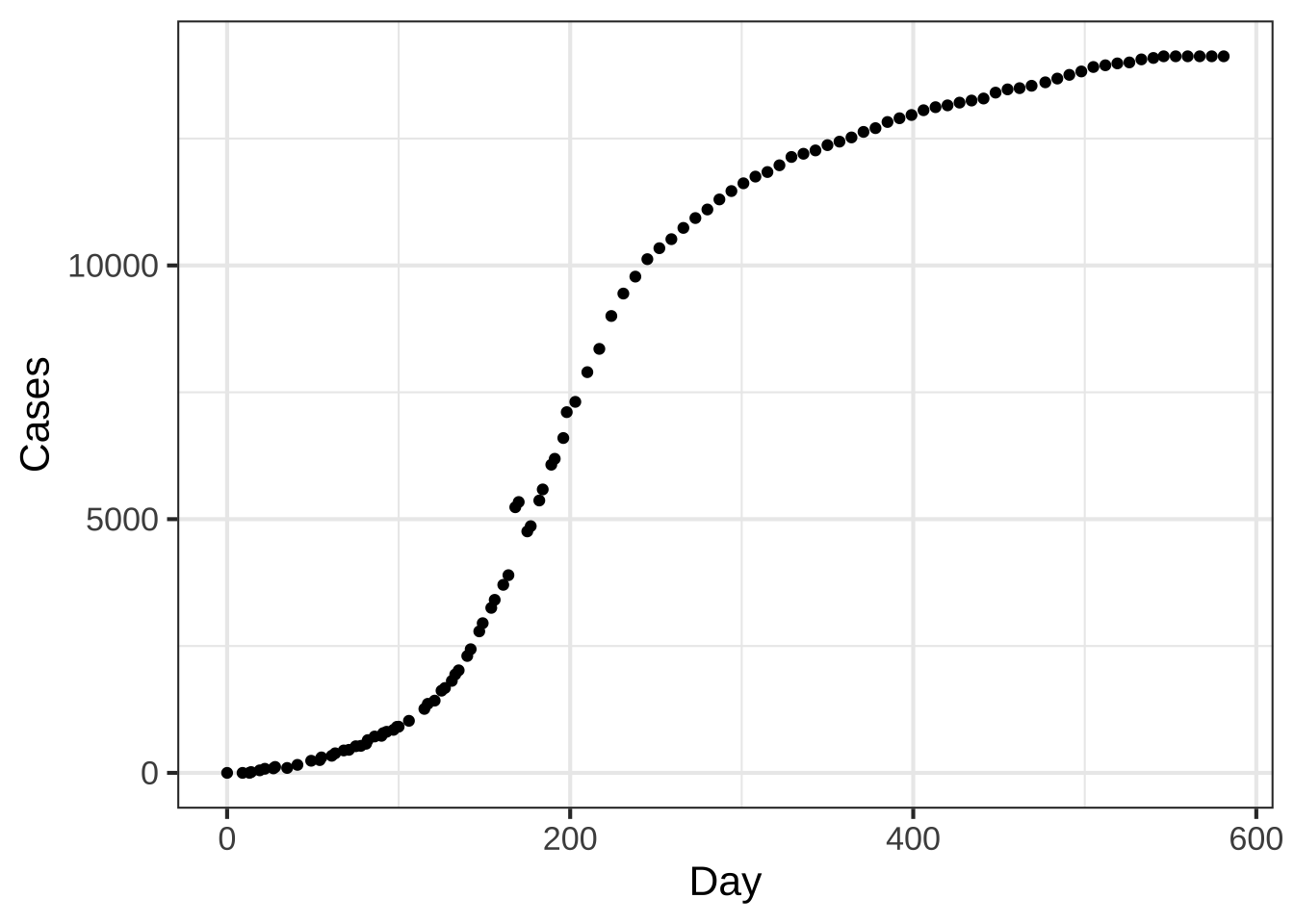
Figure 8.10: Cumulative Ebola cases in Sierra Leone
Although the cumulative case data are roughly sigmoidal in shape, there are systematic differences in shape from a true sigmoid. For comparison, Figure 8.11 is a graph of genuinely sigmoidal data.
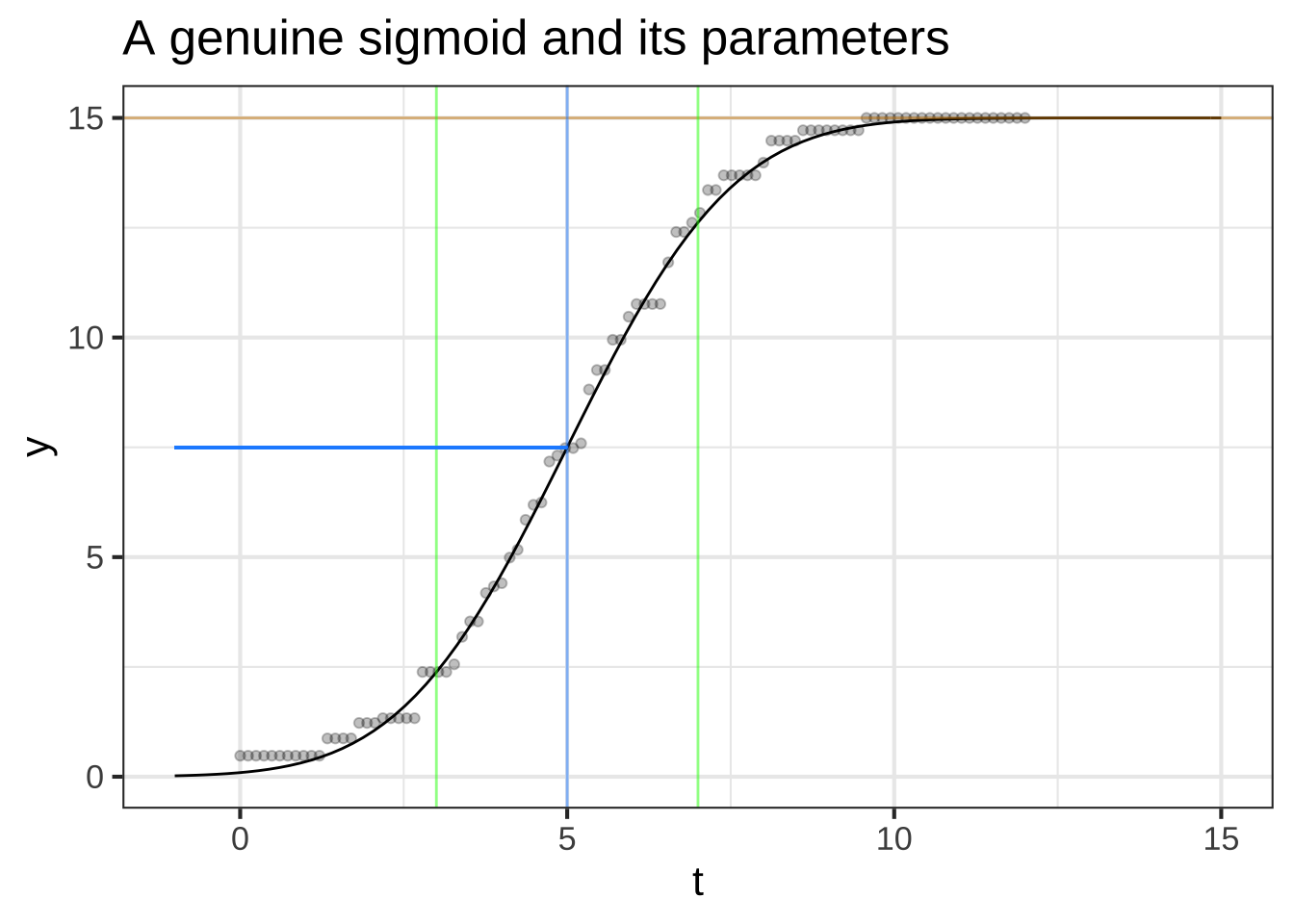
Figure 8.11: A simulated sigmoidal growth process.
The Ebola data have only a rough similarity to the sigmoid shape. Still, fitting a model and then examining closely the deviations of the model from the data can prompt questions that can lead to a better understanding of the data and what’s needed in an appropriate model.
Here’s a methodology for estimating the parameters mean and sd of a sigmoid graphically.
Sketch in a S-shaped curve that smoothly follows the data. In Figure 8.11 this has already been done for you. For the Ebola data, you will have to use your judgment.
Find the top plateau of the S-curve. This is indicated by the tan line in Figure 8.11. The parameter
Ais simply the height of the plateau, in this case \(y \approx 15\).Come down half way from the plateau. Here, that’s 15/2 or 7.5, indicated by the horizontal blue line segment. Find the inverse of the S-curve from that half-way point onto the horizontal-axis. Here, that gives \(t \approx 5\). The parameter
centeris that value.From the center of the S-shaped curve, follow the curve upward about 2/3 of the way to the plateau. In the diagram, that point is marked with a green line at \(t \approx 7\). The
widthis the distance along the horizontal axis from the blue centerline to the green line. Here, that’s \(7 - 5\) giving 2 as thewidth.You might also want to trace the S-curve downward from the centerline about 2/3 of the way to zero. That’s indicated by the left green line. In the standard sigmoid, the two green lines will be equally spaced around the centerline. Of course the data may not be in the shape of the standard sigmoid, so you might find the two green lines are not equally spaced from the center.
8.6 Exercises
Exercise 8.1: 0rvpbu
These three expressions
\[e^{kt}\ \ \ \ \ 10^{t/d} \ \ \ \ \ 2^{t/h}\]
produce the same value if \(k\), \(d\) and \(h\) have corresponding numerical values.
The scaffolding has an expression for plotting out \(2^{t/h}\) for \(-4 \leq t \leq 12\) where \(h = 4\). It also plots out \(e^{kt}\) and \(10^{t/d}\)
Your task is to modify the values of d and k such that all three curves lie on top of one another. (Leave h at the value 4.) You can find the appropriate values of d and k to accomplish this by any means you like, say, by using the algebra of exponents or by using trial and error. (Trial and error is a perfectly valid strategy regardless of what your high-school math teachers might have said about “guess and check.” The trick is to make each new guess systematically based on your previous ones and observation of how those previous ones performed.)
After you have found values of k and d that are suited to the task …
What is the numerical value of your best estimate of `k`? ( ) 0.143 (x ) 0.173 ( ) 0.283 ( ) 0.320 [[Excellent!]]
What is the numerical value of your best estimate of `d`? ( ) 11.2 ( ) 11.9 (x ) 13.3 ( ) 15.8 [[Right!]]
Exercise 8.3: YLWP1
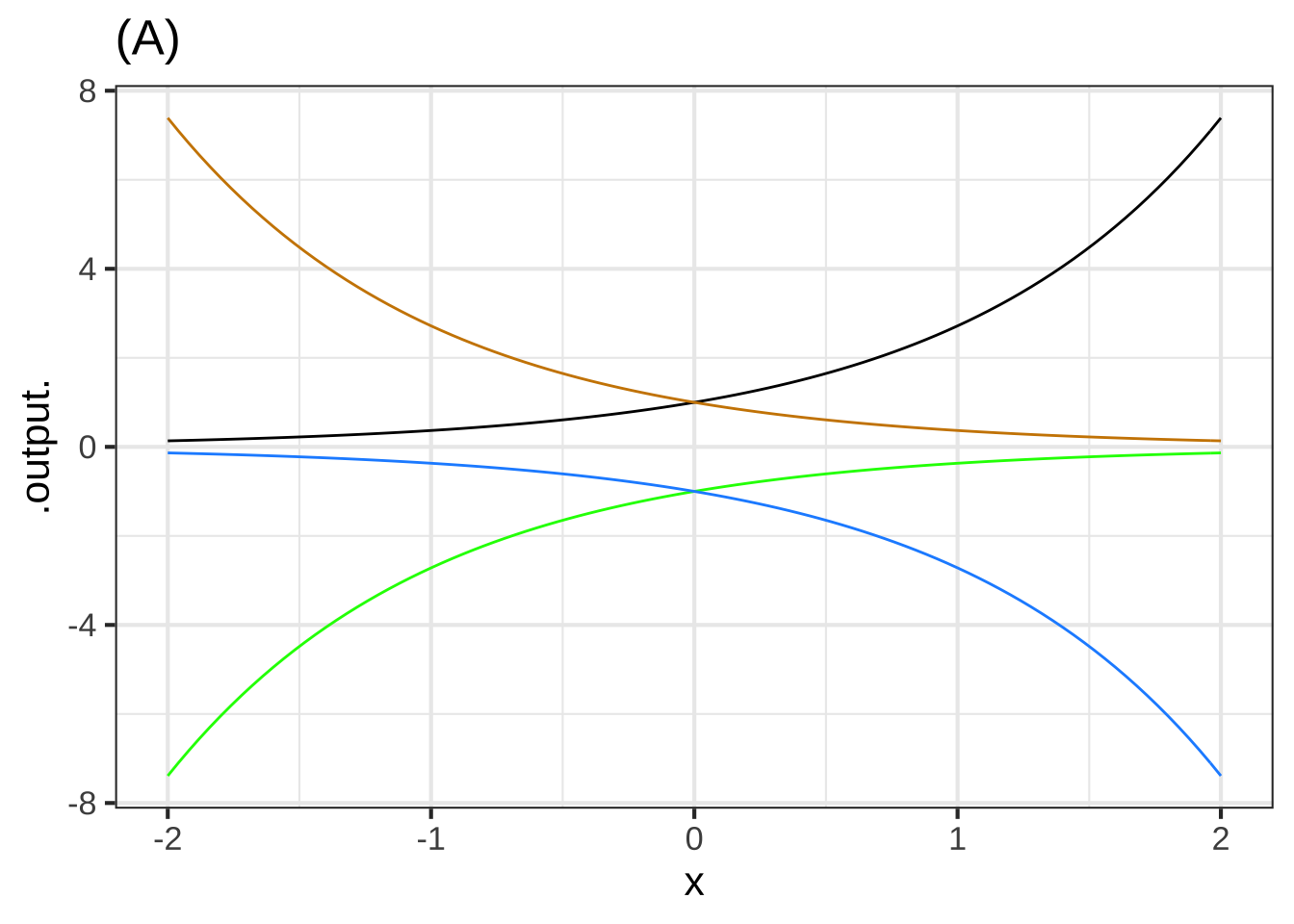
One of the curves in plot (A) is a pattern-book function. Which one? (x ) black ( ) blue ( ) green ( ) tan ( ) none of them [[It's the exponential function.]]
Taking $$f()$$ to be the pattern-book function in plot (A), which one of the curves is $$f(-x)$$? ( ) black ( ) blue ( ) green (x ) tan ( ) none of them [[Right!]]
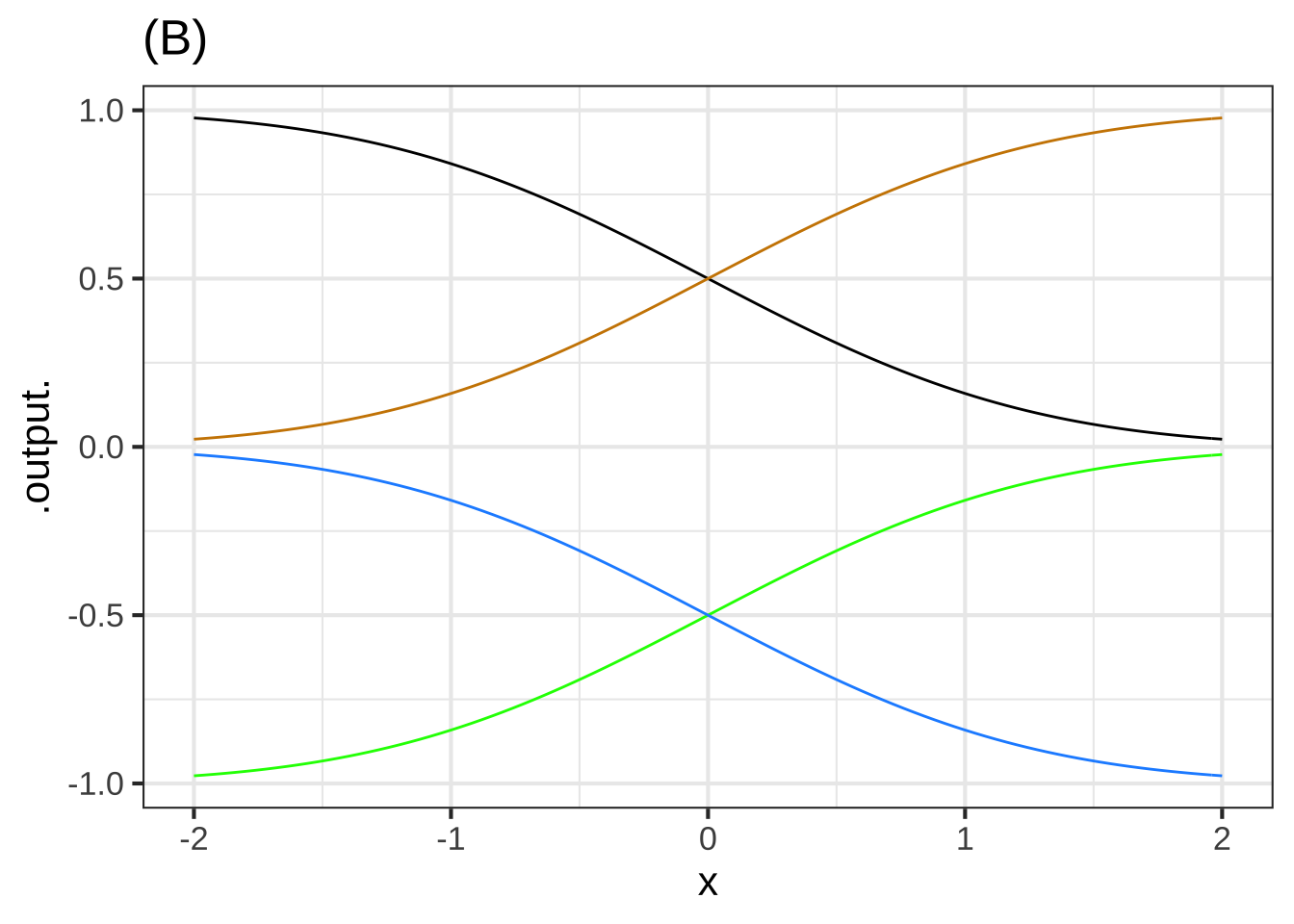
One of the curves in plot (B) is a pattern-book function. Which one? ( ) black ( ) blue ( ) green (x ) tan ( ) none of them [[Right!]]
Taking $$f()$$ to be the pattern-book function in plot (B), which one of the curves is $$-f(x)$$? ( ) black (x ) blue ( ) green ( ) tan ( ) none of them [[Correct.]]
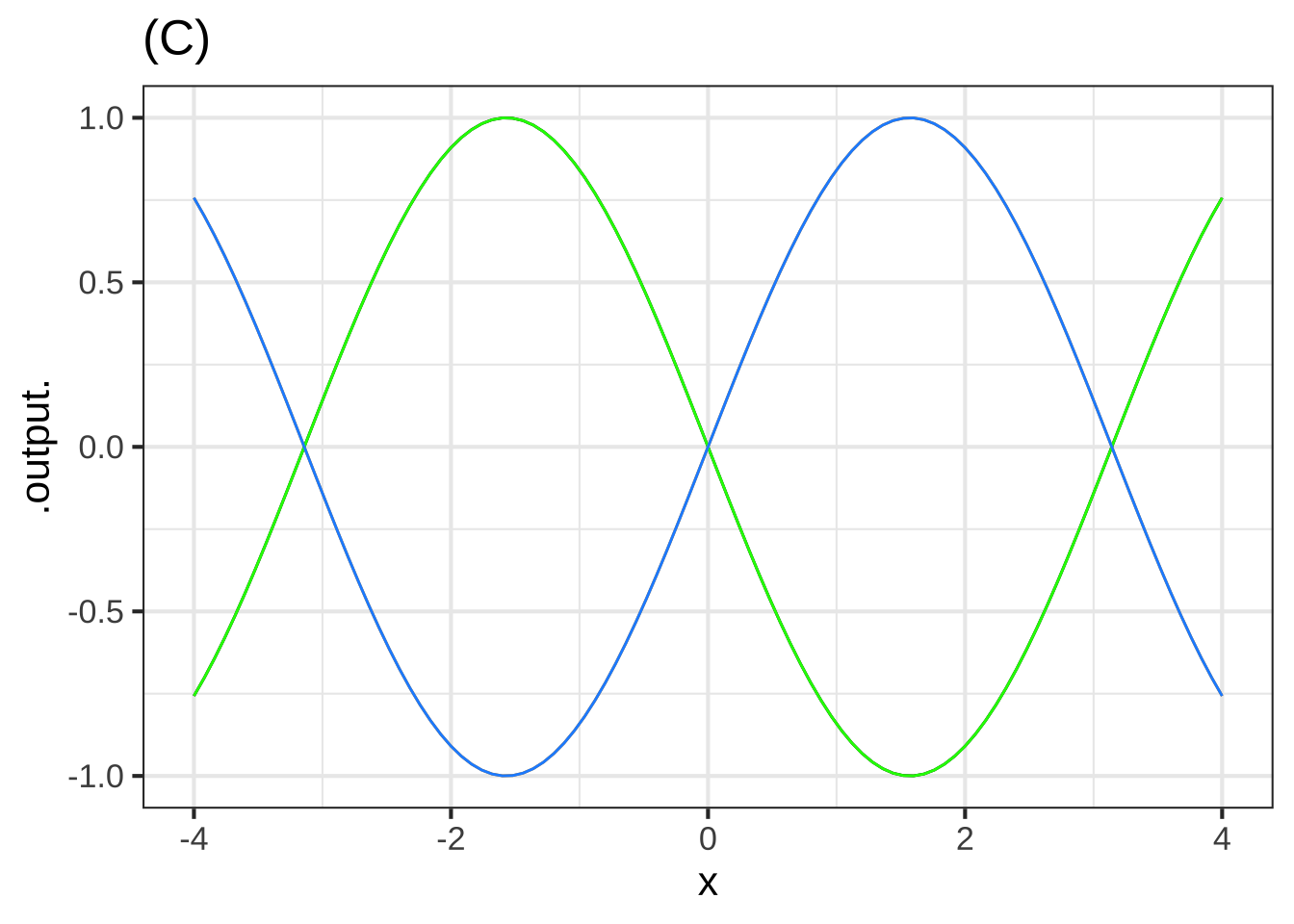
The blue curve in plot (C), as you know, is the sinusoid pattern-book function.
Which of these functions is the green curve? ( ) $$\sin(-x)$$ ( ) $$-\sin(x)$$ ( ) $$-\sin(-x)$$ ( ) Both $$\sin(-x)$$ and $$-\sin(-x)$$ (x ) Both $$\sin(-x)$$ and $$-\sin(x)$$ [[The sine function has so-called "odd" symmetry around $$x=0$$.]]
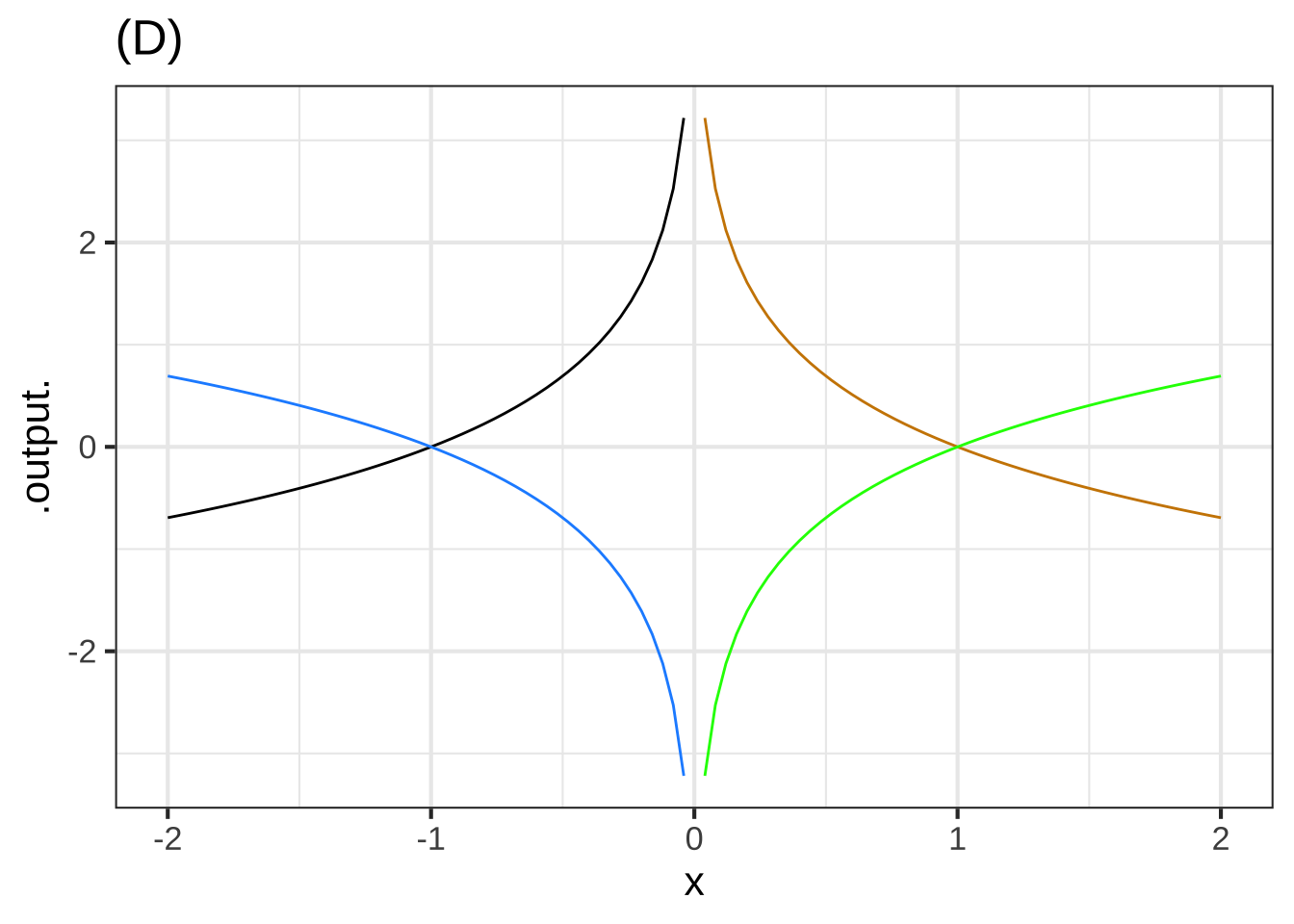
One of the curves in plot (D) is a pattern-book function. Which one? ( ) black ( ) dodgerblue (x ) green ( ) tan ( ) none of them [[Nice!]]
Taking $$f()$$ to be the pattern-book function in plot (D), which one of the curves is $$-f(-x)$$? (x ) black ( ) dodgerblue ( ) green ( ) tan ( ) none of them [[Nice!]]
Exercise 8.5: YELXG
A person breathes in and out roughly every three seconds. The volume \(V\) of air in the person’s lungs varies between a minimum of \(2\) liters and a maximum of \(4\) liters. Assume time \(t\) is measured in seconds.
Remember that a full cycle of the sine wave \(\sin(x)\) involves \(x\) going from its starting value to that value plus \(2 \pi\).
Which of the following is the most appropriate of these models for $$V(t)$$?
( ) $$V(t) \equiv 2 \sin \left( \frac{\pi}{3} t \right) + 2$$
(x ) $$V(t) \equiv \sin \left( \frac{2\pi}{3} t \right) + 3$$
( ) $$V(t) \equiv 2 \sin \left( \frac{2\pi}{3} t \right)+ 2$$
( ) $$V(t) \equiv \sin \left( \frac{\pi}{3} t \right) + 3$$
[[Good. In this class, we generally write the sine function like $$\sin(2 \pi t/P)$$ which means that the overall argument to the sine function will go from 0 to $$2 \pi$$ when $$t$$ goes from 0 to $$P$$.]]
A respiratory cycle can be divided into two parts: inspiration and expiration. Please do an experiment. Using a clock or watch, breath with a total period of 3 seconds/breath, that is, complete one breath every three seconds. Once you have practiced this and can do it without forcing either phase of breathing, make a rough estimate of what fraction of the cycle is inspiration and what fraction is expiration. (The “correct/incorrect” answers here are right for most people. Your natural respiration might be different.)
Which is true? (x ) Inspiration lasts longer than expiration ( ) Expiration lasts longer than inspiration ( ) Inspiration and expiration each consume about the same fraction of the complete cycle. [[Excellent!]]
Exercise 8.7: VBWD
The graph below shows a recording from a “spirometer,” an instrument for recording respiration. Like many old instruments, the trace from this spirometer is made by a pen at the end of a swinging arm with paper moving steadily beneath it. The arm is not exactly aligned with the horizontal axis. Nonetheless, you should be able to estimate an appropriate amplitude and period for the trace. (dm\(^3\) is cubic-decimeters: a tenth of a meter cubed. This is the same as a liter.)
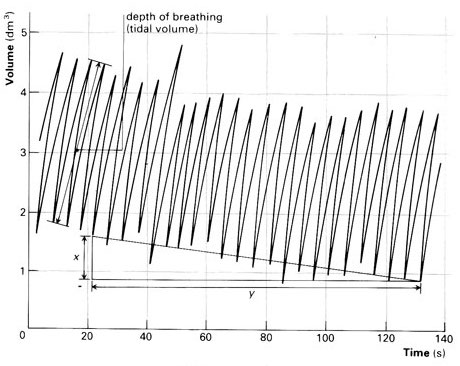
What are appropriate estimates for the period and amplitude of the respiration trace? ( ) About $$\pm 1$$ liter and 3 seconds. (x ) About $$\pm 1$$ liter and 5 seconds. ( ) About $$\pm 1$$ liter and 7.5 seconds. [[Right!]]
Exercise 8.9: vkwl4
The Bargain Basement store wants to sell its goods quickly. Consequently, they reduce each product’s price \(P\) by 5% per day.
If a jacket costs $$80 today, how much will it cost in $$t$$ days? ( ) $$P = 80 - 5t$$ ( ) $$P = 80 - 4t$$ ( ) $$P = 80 - 0.05t$$ ( ) $$P = 80 (0.05)^t$$ (x ) $$P = 80 (0.95)^t$$ [[Excellent!]]
You’ll need to open a sandbox for the next question.
You’re on your own here! Remember, to raise a number to a power, you can use an expression like 0.95^7.
You decided that you like the $$80 jacket, but you have a budget of only $$60. How long should you wait before coming back to the Bargain Basement store.? ( ) 3 days ( ) 4 days ( ) 5 days (x ) 6 days [[Nice!]]
Exercise 8.11: asevss
The Wikipedia entry on “Common Misconceptions” used to contain this item:
Some cooks believe that food items cooked with wine or liquor will be non-alcoholic, because alcohol’s low boiling point causes it to evaporate quickly when heated. However, a study found that some of the alcohol remains: 25% after 1 hour of baking or simmering, and 10% after 2 hours.
The modeler’s go-to function type for events like the evaporation of alcohol is exponential: The amount of alcohol that evaporates would, under constant conditions (e.g. an oven’s heat), be proportional to the amount of alcohol that hasn’t yet evaporated.
A) Assume that 25% of the alcohol remains after 1 hour? If the process were exponential, how much would remain after 2 hours? ( ) 10% ( ) 25% (x ) 25% of 25% ( ) 75% ( ) 75% of 75% [[We know that 75% is eliminated over 1 hour, leaving 25%. The continuing exponential process will, over the next hour eliminate 75% of the amount at the start of that hour. So after hour 2 we'll have 25% of the amount we had at hour 1, which was 25% of the original amount.]]
B) What is the half-life of an exponential process that decays to 25% after one hour? ( ) 15 minutes (x ) 30 minutes ( ) 45 minutes ( ) none of the above [[This gives time for two halvings in one hour, bringing us to 25% as observed.]]
Let’s change pace and think about the “10% after 2 hours” observation. First, recall that the amount left after \(n\) halvings is \(\text{amount.left}(n) \equiv \frac{1}{2}^n\) This is an exponential function with base 1/2.
You’re going to carry out a guess-and-check procedure to find \(n\) that gives \(\text{amount.left}(n) = 0.10\).
Open a sandbox and copy over the scaffolding, which includes the definition of the amount.left() function. We started with a guess of \(n=0\), which is wrong. Change the guess until you get the output 10%.
amount.left <- makeFun((1/2)^n ~ n)
amount.left(0)C) Use `amount.left()` as defined in the scaffolding to guess-and-check how many halvings it takes to bring something down to 10% of the original amount. ( ) 2.58 (x ) 3.32 ( ) 3.62 ( ) 3.94 ( ) 4.12 [[Nice!]]
Another way to find the input \(n\) that generates an output of 10% is to construct the inverse function to \(\text{amount.left}()\).
The computer already provides you with inverse functions for \(2^n\) and \(e^n\) and \(10^n\). Their names are log2(), log(), and log10() repectively. Using log2(), write a function named log_half() that gives the inverse function to \((1/2)^n\). Remember, the input to the inverse function corresponds to 10%; the output to the \(n\).
log_half <- makeFun( - log2(...your stuff here ...) ~ x)D) The answer you got in part C) is the **number** of halvings needed to reach 10%. If this number occurs in 2 hours (that is, 120 minutes), what is the half life stated in minutes. ( ) 30 ( ) 35 (x ) 36 ( ) 38 ( ) 42 ( ) 47 [[Right!]]
Suppose you compromise between the half-life needed to reach 25% after one hour and the half-life needed to reach 10% after two hours. Use, say, 33 minutes as the compromise half life. Using the sandbox, calculate how much would be left after 1 hour for this compromise half life, and how much left after 2 hours.
E) How much is left after 1 hour and after 2 hours when the half life is 33 minutes? (x ) 28% and 8% ( ) 31% and 4% ( ) 30% and 9% ( ) 27% and 9% [[Right!]]
Exercise 8.13: IELWV
The gaussian function is implemented in R with dnorm(x, mean, sd). The input called mean corresponds to the center of the hump. The input called sd gives the width of the hump.
In a sandbox, make a slice plot of dnorm(x, mean=0, sd=1). By varying the value of width, figure out how you could read that value directly from the graph.
In the plot below, one of the double-headed arrows represents the width parameter. The others are misleading.
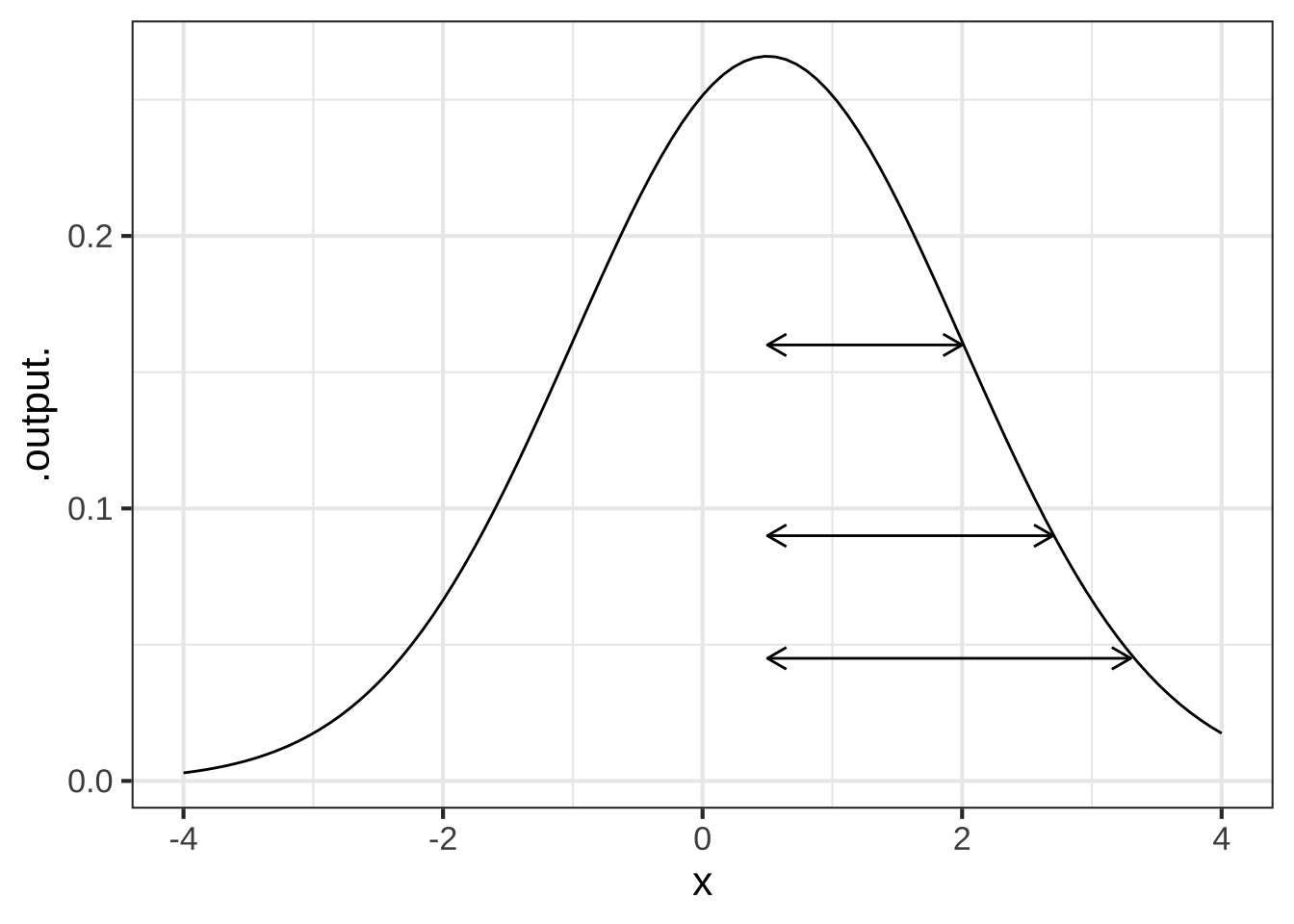
Which arrow shows correctly the `width` parameter of the gaussian function in the graph with arrows? (x ) top ( ) middle ( ) bottom ( ) none of them [[Good.]]
What is the value of `center` in the graph with arrows? ( ) -2 ( ) -1 ( ) -0.5 ( ) 0 (x ) 0.5 ( ) 1 ( ) 2 [[Excellent!]]
Exercise 8.15: CKSLE
Gaussian functions and sigmoidal functions come in pairs. For every possible sigmoid, there is a corresponding gaussian that gives, for each value of the input, the slope of the sigmoid.
Each of the following graphs shows a sigmoid and a gaussian function. The two might or might not correspond to one another. That is, the output of the gaussian might be the slope of the sigmoid, or the gaussian might correspond to some other sigmoid. Remember, you’re comparing the output of the gaussian to the slope of the sigmoid.
For each graph, say whether the gaussian and the sigmoid correspond to one another. If not, choose one of the reasons why not.
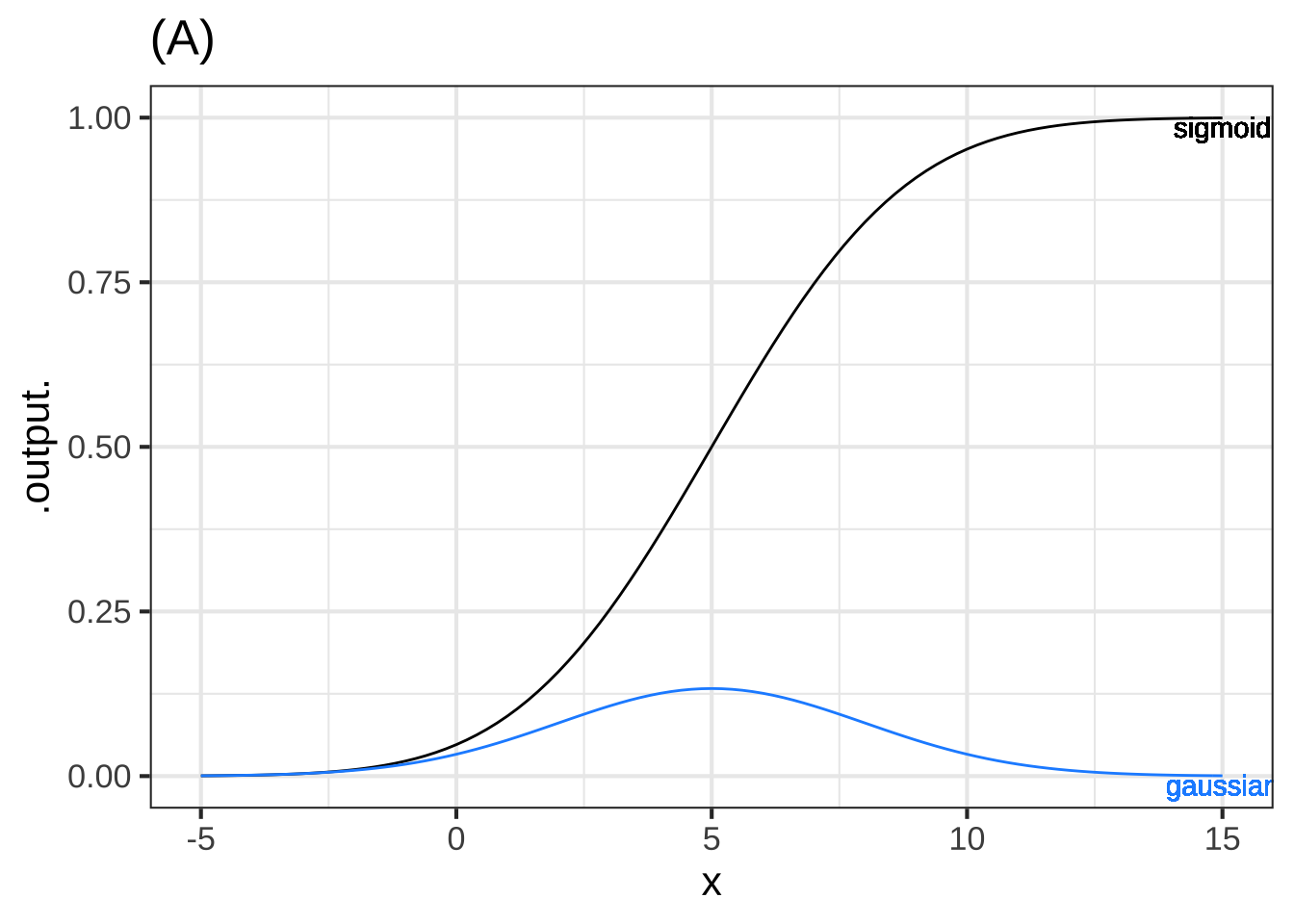
Graph (A) (x ) The gaussian and sigmoid correspond. ( ) The peak of the gaussian does not occur at the same value of $$x$$ at which the sigmoid is steepest. ( ) The numerical value of the output of the gaussian function is, for all $$x$$, much larger than the numerical value of the *slope* of the sigmoid. [[Good.]]
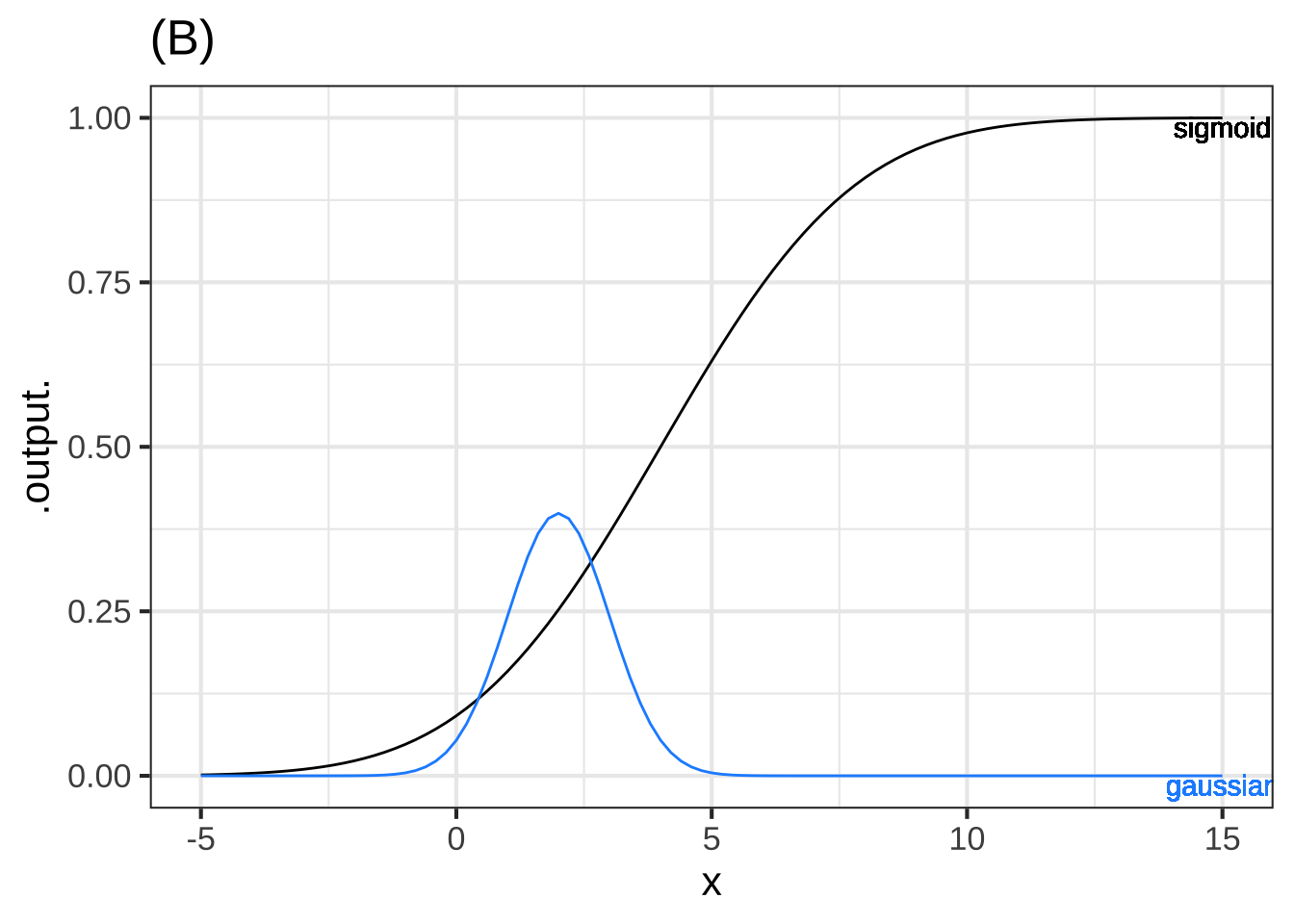
Graph (B) ( ) The gaussian and sigmoid correspond. (x ) The peak of the gaussian does not occur at the same value of $$x$$ at which the sigmoid is steepest. ( ) The numerical value of the output of the gaussian function is much larger than the numerical value of the *slope* of the sigmoid. [[The gaussian peaks at about $$x=2$$ while the steepest part of the sigmoid is at about $$x=4$$]]
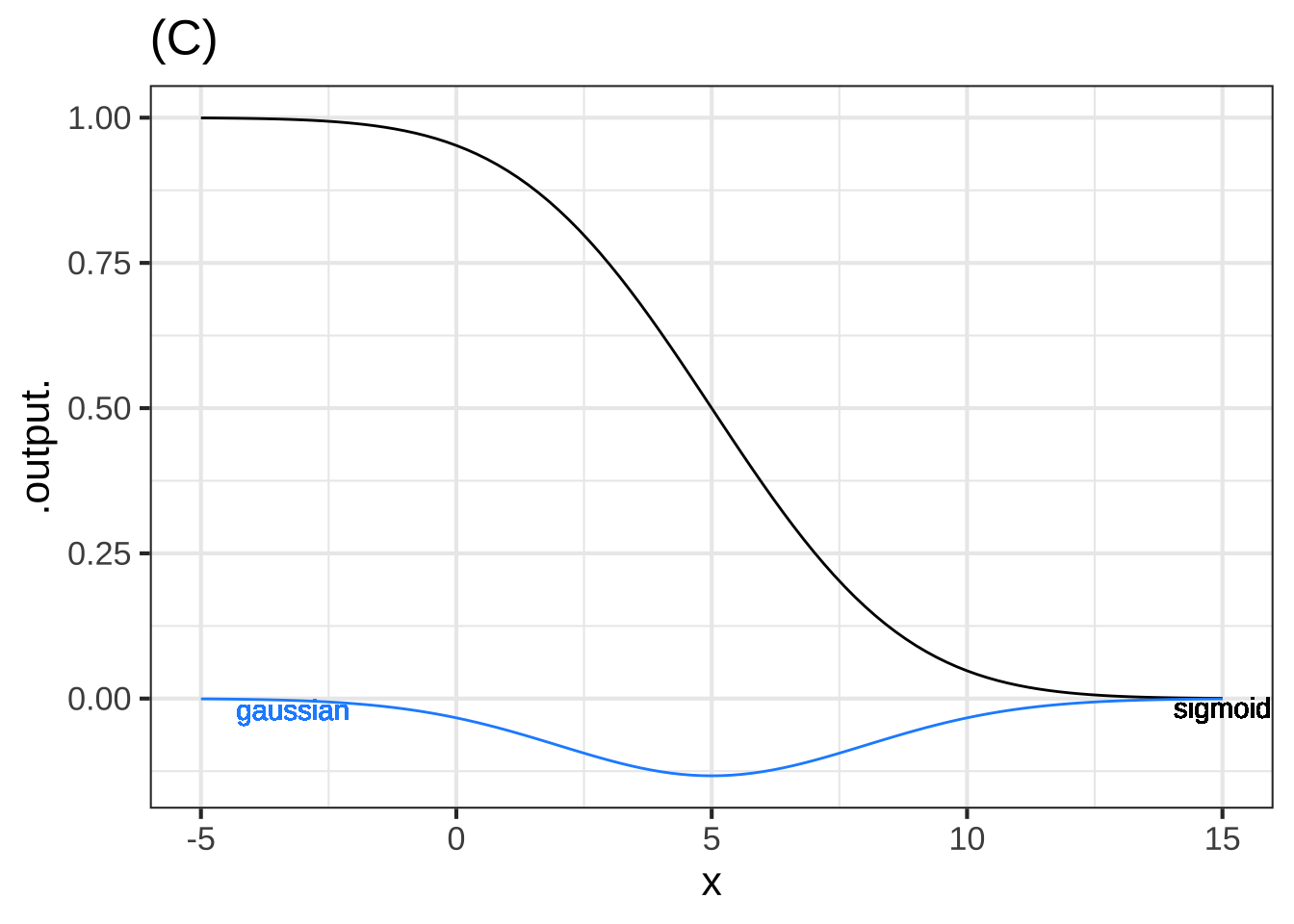
Graph (C) (x ) The gaussian and sigmoid correspond. ( ) The peak of the gaussian does not occur at the same value of $$x$$ at which the sigmoid is steepest. ( ) The numerical value of the output of the gaussian function is, for all $$x$$, much larger than the numerical value of the *slope* of the sigmoid. [[Correct.]]
In the graph D, there are several gaussian functions shown, only one of which corresponds to the sigmoid.
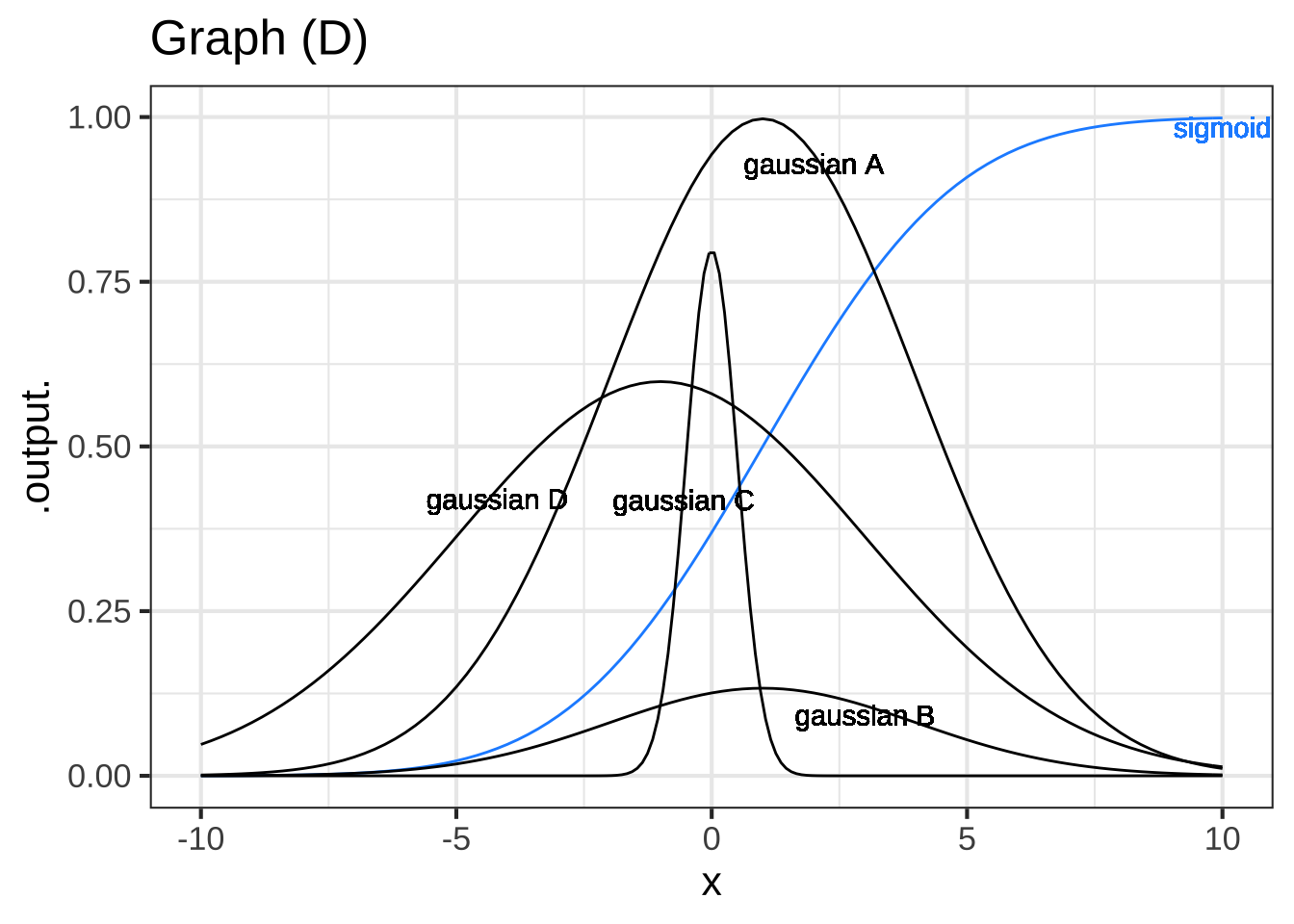
Which gaussian corresponds to the sigmoid? ( ) A (x ) B ( ) C ( ) D [[Right! The gaussian is centered on the steepest part of the sigmoid and falls to zero where the sigmoid levels out.]]
Exercise 8.17: bllKR
Have in mind a gaussian function and a sigmoid function that form a corresponding pair.
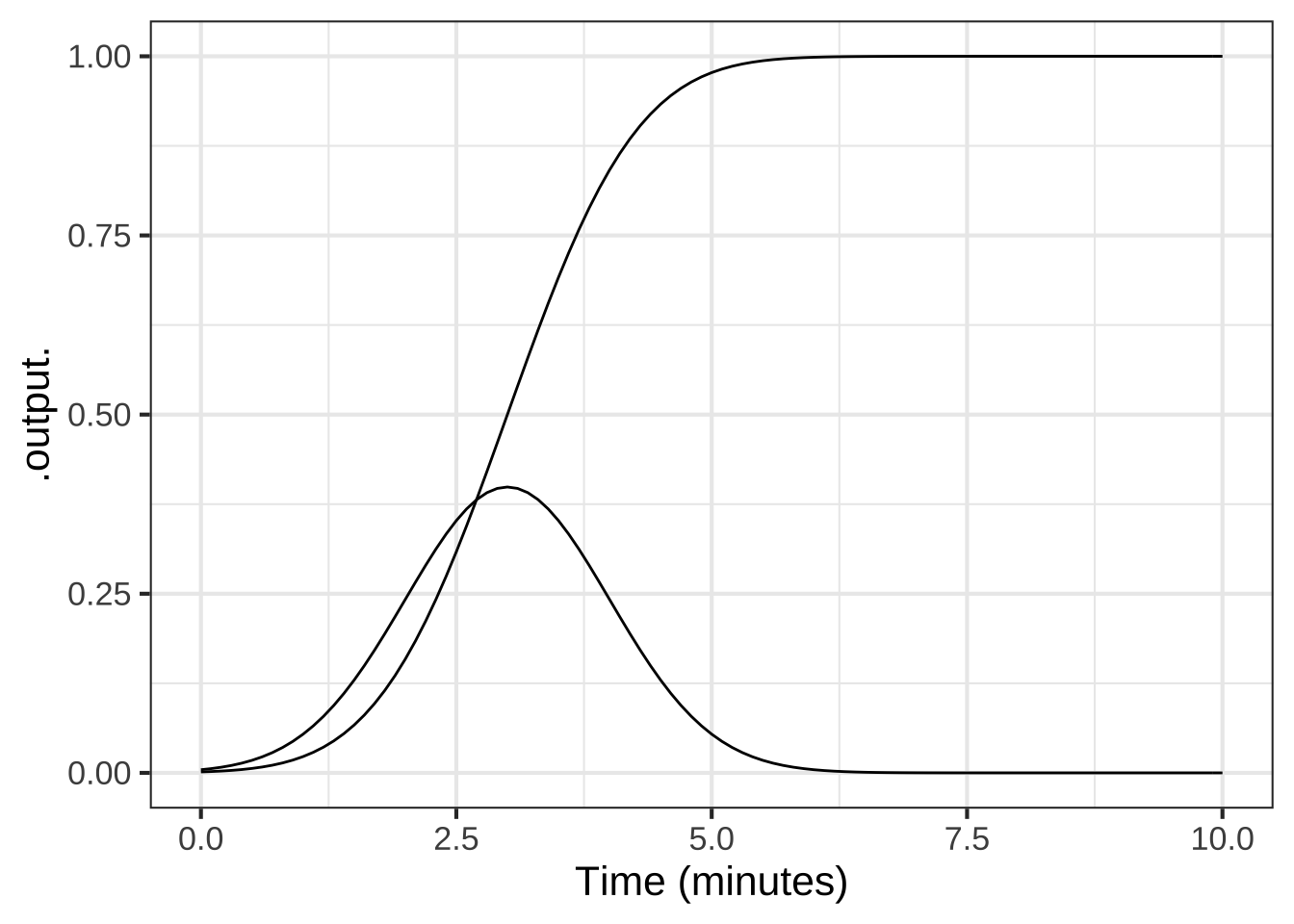
Which of these stories is consistent with the relationship between a gaussian and its corresponding sigmoid? ( ) The gaussian is the amount of water in a bathtub while the sigmoid is the time you spend in the bath. ( ) The gaussian is the amount of water in the bathtub while the sigmoid is the rate at which water flows from the tap. (x ) The gaussian is the rate at which water flows from the tap and the sigmoid is the amount of water in the bathtub. ( ) The gaussian indicates the amount the drain is open and the sigmoid is the amount of water in the bathtub. [[Correct.]]
Exercise 8.19: YLWP2
Each of the curves in the graph is an exponential function \(e^{kt}\), for various values of \(k\).
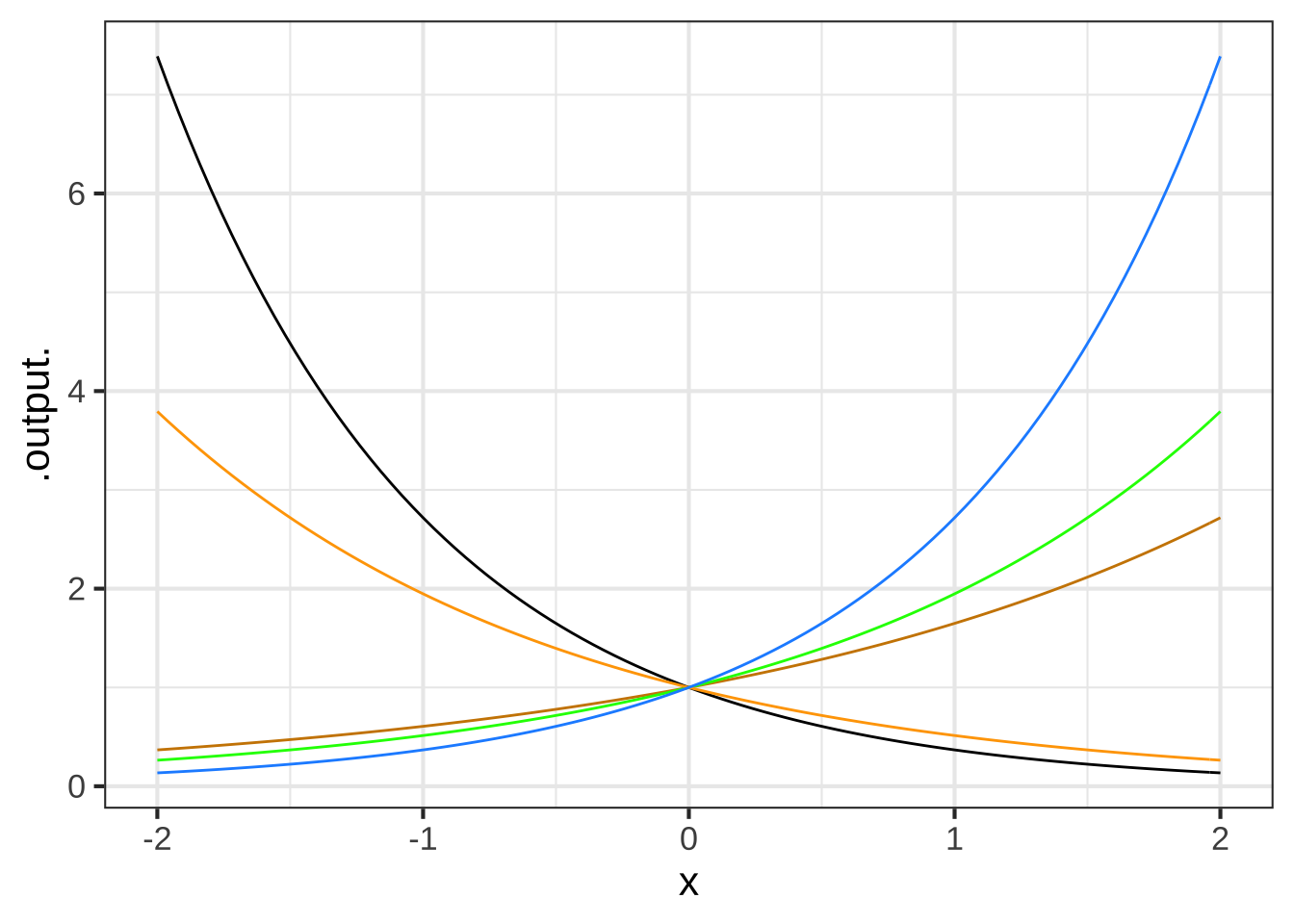
What is the order from $$k$$ smallest (most negative) to k largest? (x ) black, orange, red, green, blue ( ) black, orange, blue, green, red ( ) red, green, blue, orange, black [[Exponential functions that grow slowly have $$k$$ with a small absolute value]]
Exercise 8.21: EKCIE
Put aside for the moment that the Ebola data plotted in Figure 8.10 doesn’t look exactly like the standard sigmoid function. Follow the fitting procedure as best you can.
Where is the top plateau? ( ) About Day 600. (x ) About 14,000 cases ( ) About 20,000 cases ( ) None of the above [[Good.]]
Where is the centerline? (x ) Near Day 200 ( ) Near Day 300 ( ) At about 7000 cases [[Correct.]]
Now to find the `width` parameter. The curve looks more classically sigmoidal to the left of the centerline than to the right, so follow the curve *downward* as in Step 4 of the algorithm to find the parameters. What's a good estimate for `width`? (x ) About 50 days ( ) About 100 days ( ) About 10 days ( ) About 2500 cases [[Correct.]]