19 Computing derivatives
To differentiate a function \(g(x)\) means simply to produce the corresponding function \(\partial_t g(x)\). This is often called “finding the derivative,” language that resonates with the high-school algebra task of “finding \(x\).” Rather than conjuring an image of searching high and low for a missing function, it’s more accurate to say, “compute the derivative.”  2150
2150
In this chapter we’ll introduce two ways of computing a derivative. For simplicity we will write \(x\) for the with-respect-to-variable, although in practice you might be using \(t\) or \(z\) or something else. 2155
- Symbolic differentiation, which uses a set of re-writing rules
- Finite-differencing, which is based directly on the \({\cal D_x}\) operator
In the days when functions were always presented using formulas, symbolic differentiation was usually the only method taught. Nowadays, when functions are just as likely to be described using data and an algorithm, finite-differencing provides the practical approach. 2160
19.1 A function from a function
Recall that the goal of differentiation is to make a function out of an already known function. We’ll call the already known function \(g(x)\). In Chapter 17 we’ve outlined the properties that the new function should have and gave a nice naming convention, \(\partial_x g(x)\) that shows where the new function comes from. In this section we’ll put that aside and focus on the question of what it means to “make a function.” 2165
When mathematics is done with paper and pencil, “making a function” is a matter of writing a formula, such as \(x^2 \sin(x) + 3\) and sometimes giving a name to the formula, e.g. \(h(x) \equiv x^2 \sin(x) + 3\). We are essentially writing something down that will make sense when viewed by another person trained in the conventions of mathematical notation. 2170
For a computer, on the other hand, a function is a definite kind of thing. We “make a function” by creating that kind of thing and, usually, giving it a name. We evaluate a function—that is, apply the function to inputs to produce an output—by using specific punctuation, which in R involves the use of parentheses, for instance name(input). 2175
The computer language itself provides specific means to define a new function. In R/mosaic, you first construct a tilde expression naming the function inputs (right side of the tilde) and specifying the algorithm of that function (left side of the tilde), as with this formula:
f_description <- x^2 * sin(x) + 3 ~ x # a tilde expressionOn its own, f_description cannot be used like a function because it was constructed as something else: a tilde expression. Trying to use f_description in the way one uses a function produces an error.
f_description(2)
Error in f_description(2): could not find function "f_description"In between the tilde expression and the final result—a function—is software that translates from tilde-expressions into functions:
f <- makeFun(f_description)The new creation, f() can now be used like any other function, e.g.
f(2)## [1] 6.63719Down deep inside, makeFun() uses a more basic function-creation syntax which looks like this
function(x) {x^2 * sin(x) + 3}## function(x) {x^2 * sin(x) + 3}You can see all the same information that was in the tilde description, just arranged differently.
Almost every computer language provides something like function. The internal workings of function are elaborate and detailed … only advanced programmers need to be aware of them. This, in much the same way as it’s unnecessary to understand the workings of a transistor in order to use a computer, or comprehend the biochemistry of a COVID vaccine in order to benefit from it. 2180
In the same spirit as makeFun(), which translates a tilde-expression into the corresponding function, in R/mosaic you have D() which takes a tilde expression and translates it into the derivative of the function described.35 For example:
D(f_description)## function (x)
## 019.2 Finite differencing
You can use the definition of the slope function \[{\cal D}_x f(x) = \frac{f(x+0.1) - f(x)}{0.1}\] to create an approximation to the derivative of any function. Like this:
Whenever you calculate a derivative function, you should check against mistakes or other sources of error. For instance, whenever the derivative is zero, the original function should have an instantaneous slope of zero. Figure 19.1 shows a suitable plot for supporting this sort of check.
zeros_of_dg <- findZeros(dg(x) ~ x, xlim=c(-5,5))
slice_plot(g(x) ~ x, domain(x=c(-5,5)), npts=500) %>%
slice_plot(dg(x) ~ x, color="magenta", npts=500) %>%
gf_hline(yintercept = ~ 0, color = "orange", size=2, alpha=0.2) %>%
gf_vline(xintercept = ~ x, data=zeros_of_dg, color="blue")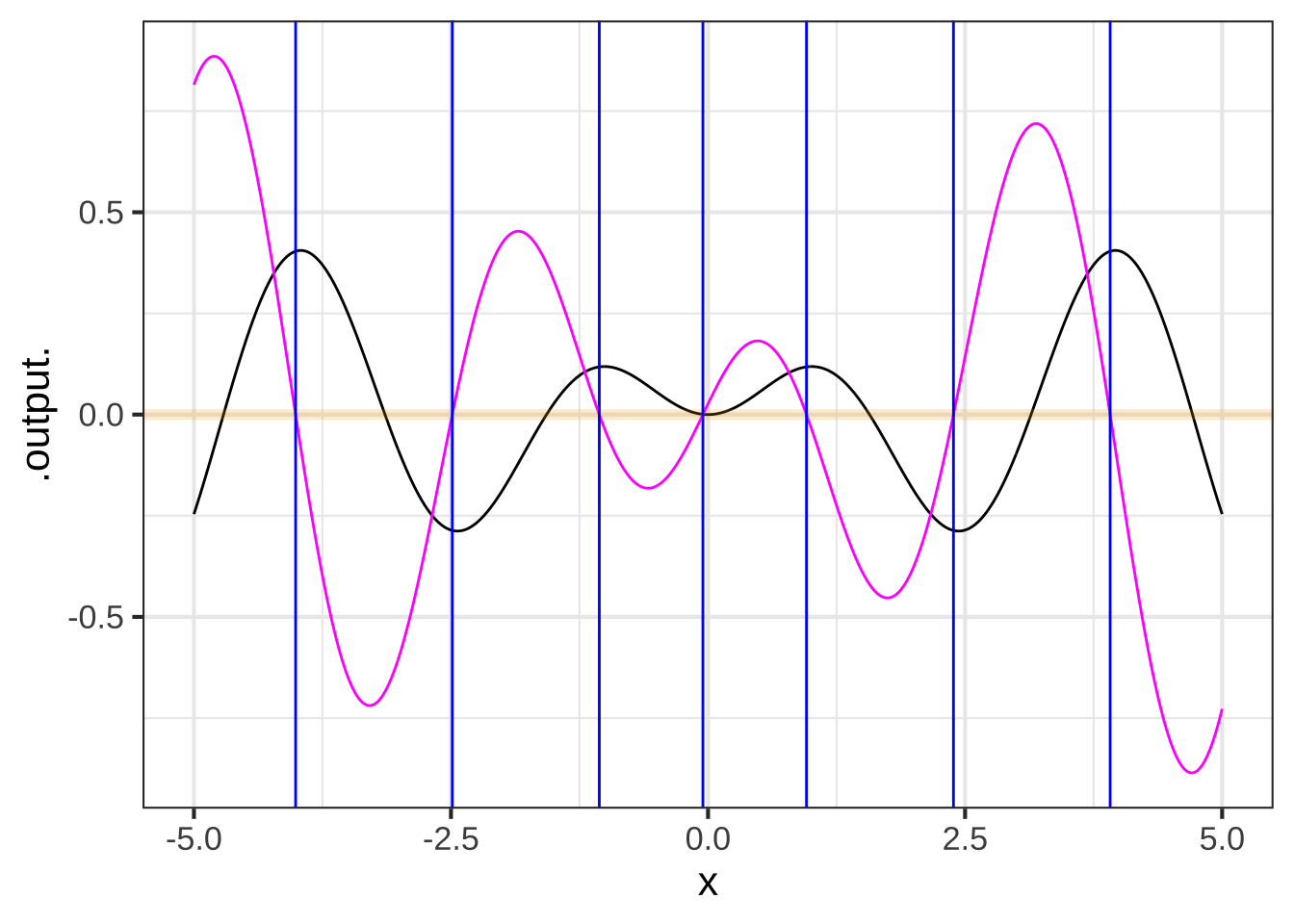
Figure 19.1: The x-position of zero crossings of the derivative function (magenta) are marked with blue lines. The zero crossings correspond to local maxima or minima in the original function (black). This is because the original function has slope zero at maxima and minima.
Look very closely at Figure 19.1, particularly at the places where the blue vertical markers cross the function \(g(x)\) (black). They should cross exactly at the flat zone, but they are a little shifted to the left. (You might have to zoom in on the plot to see the offset between the vertical blue marker and the local maximum of the function.) That’s the sense in which the finite-difference approach gives an approximation. The small left-shift stems from the use of 0.1 in the definition of the zero function. Use a smaller value, say 0.01 or 0.001, and you won’t be able to see the shift at all. 2185
In modeling work, there’s nothing wrong with an approximation so long as it is good enough for your purposes. We picked the value 0.1 for our definition of the slope function because it works very well with the pattern-book functions. Here, “very well” means you can’t easily see in the graph any deviation compared to the exact derivative. 2190
When a calculation can be done exactly (without outrageous effort) it certainly makes sense to use the exact method. However:
- It’s useful to have an easy, approximate method always at hand. This lets you check the results of other methods for the possibility of some blunder or mis-conception. The slope function approach to differentiation is certainly easy, and if you think the approximation isn’t good enough, then instead of 0.1 use something smaller. (Chapter 18 discusses how small is too small.)
- The computer makes it practical to employ the slope function as a useful approximation to the derivative. There are many other mathematical methods that the computer has made feasible, for instance the methods of machine learning. These methods create functions that sometimes cannot be handled by the traditional (“exact”) methods of differentiation. 2195
19.3 The slope-function operator
Take a look at the statement we used to construct the slope function of g():
dg <- makeFun((g(x+0.1) - g(x))/0.1 ~ x)There is almost nothing about this statement that has anything to do with the specifics of how we defined g(); we could have used any \(g()\). The “almost” in the previous sentence is about the choice of 0.1, which isn’t guaranteed to be small enough. 2200
In today’s world, considerable mathematical content is conveyed to users not directly with formulas but with software that implements the formulas. And in software, it’s a good idea to have a name for each operation so that the readers and authors of software have a completely explicit indication that a particular operation is being used.
When you have many slope functions to compute in some application, it can be error prone to write many statements that are versions of
dg <- makeFun((g(x+0.1) - g(x))/0.1 ~ x)It’s too easy to make a mistake in copying this over, producing a wrong computation that can be hard to detect in the code. For instance, each of these statements looks a lot like the above, but all of them are different and none is constructing a slope function:
df <- makeFun((f(x-0.1) - f(x))/0.1)
dh <- makeFun((h(x+0.1) - f(x))/0.1)
du <- makeFun((u(x+0.1) - u(x))/1.0)
dg <- makeFun(g(x+0.1) - g(x)/0.1)Much easier to read and more reliable would be something like this:
df <- slopeFun(f(x) ~ x)
dh <- slopeFun(h(x) ~ x)
du <- slopeFun(u(x) ~ x)Creating such an R operator is a programming task and in that sense beyond the scope of this course. Still, it’s a good idea to get in the habit of reading programming code. So here goes …
Creating a slopeFun() operator: 2205
- Instead of
makeFun()which is really just maknig for mathematical functions, R programmers use a construction namedfunction(). The name of the arguments goes inside the parentheses. The function algorithm goes between curly braces:{ } - We’re going to use a tilde expression as the input to
slopeFun(). This is how the other R/mosaic operators work. That will be easier for the user and will also give us access to those other operators if we need them in writingslopeFun(). - The object returned by the
slopeFun()operator will be, of course, a function. We’ve been usingmakeFun()to make our mathematical functions, so expect to see that in the code forslopeFun(). - There’s the matter of whether 0.1 is small enough. So let’s use an
hargument in place of 0.1 that we can change when needed.
Putting this together, here is a slopeFun() operator that takes a tilde expression (as do makeFun() and slice_plot()) and produces a new mathematical function that is the slope function for the mathematical function described in the tilde expression. (There are a couple of R programming elements in slopeFun() that you aren’t expected to understand completely. But do try reading the code to see what sense you can make of it.)
# two arguments, a tilde expression and a choice for h
# with a default value
slopeFun <- function(tilde, h=0.1) {
# Turn the tilde expression into a function
g <- makeFun(tilde)
# just like before, with h instead of 0.1
makeFun((g(x + h) - g(x))/h ~ x, h=h)
}Another important advantage of centralizing computations in a single operator is that the operator can be made more sophisticated without being harder to use. For instance, R/mosaic provides the D() operator for computing derivatives. This knows the rules for symbolic differentiation that will be introduced in Chapter 22 and switches to a finite-difference method (like slopeFun(), but more sophisticated) when symbolic differentiation isn’t applicable.
In practice, instead of home-brewed functions like slopeFun(), you can use the R/mosaic D() instead, which takes a more careful approach to the computer numerics and uses symbolic differentiation whenever possible to give results without numerical error.
19.4 Symbolic differentiation
Symbolic differentiation is the process of taking a formula and translating it to a new formula according to certain patterns or rules. Each rule is ultimately derived from the definition of the slope function and the differencing operator. 2215
As you recall, the differencing operator \(\diff{x}\) turns a function into its slope function \[\diff{x} f(x) \equiv \frac{f(x+h) - f(x)}{h}\]
19.4.1 The line rule
Let’s look at one where we already know the result: The straight line function \(\line(x) \equiv a x + b\) has a slope function that is constant: \(\diff{x}\line(x) = a\)
\[\diff{x}\line(x) = \frac{\line(x+h) - \line(x)}{h} = \frac{\left[\strut a (x+h) + b\right] - \left[\strut a x + b\right]}{h} = \frac{ah}{h} = a\] The derivative is the slope function with \(h\) made as small as possible. It’s tempting to think of this as \(h = 0\), but that would imply dividing by zero in the differencing operator.
Being wary about the possibility of dividing by zero, mathematicians adopt a convention which indicates clearly that \(h\) is to be small, but not zero. This convention is marked with the notation \(\lim_{h \rightarrow 0}\), which means “as close as you can get to zero, but not zero exactly.” 2220
\[\partial_x \line(x) \equiv \lim_{h\rightarrow 0} \frac{\line(x+h) - \line(x)}{h} =\\ \ \\ = \lim_{h\rightarrow 0} \frac{a h}{h} = a\]
This derivation is unarguably correct for any non-zero \(h\).
This short derivation gives us a basic differentiation rule which we can divide into 3 special cases.
-
Line rule: \(\partial_x ax + b = a\)
- \(\partial_x ax = a\). The function \(ax\) is \(\line(x)\) with \(b=0\).
- \(\partial_x b = 0\). The function \(b\) is \(\line(x)\) with \(a=0\) and thus is the constant function.
- \(\partial_x x = 1\). The function \(x\) is \(\line(x)\) with \(a=1\) and \(b=0\).
Remember that \(\partial_x f(x)\) is always a function no matter what kind of function \(f(x)\) is. The functions associated with the line rule are all constant functions, meaning the output doesn’t depend on the input.
19.4.2 The square rule
Only for the \(\line()\) function and its three special cases is the derivative a constant function. And \(\line()\) is the only function for which the \(h\) in the differencing operator disappears on its own. For instance, consider the square function: \(g(x) \equiv x^2\). 2225
\[\partial_x [x^2] = \lim_{h\rightarrow 0}\frac{(x+h)^2 - x^2}{h} =\\ \ \\ =\lim_{h\rightarrow 0}\frac{(x^2 + 2 x h + h^2) - x^2}{h} =\\ \ \\ = \lim_{h\rightarrow 0}\frac{2 x h + h^2}{h} =\\ \ \\ =\lim_{h\rightarrow 0} [2x + h]\\ \] It’s accepted that the limit of a sum is the sum of the limits, so … \[\lim_{h\rightarrow 0} \left[\strut 2 x + h\right]= \lim_{h\rightarrow 0} 2x + \lim_{h\rightarrow 0}h\] The limit of something not involving \(h\) is just that thing, giving \[\lim_{h\rightarrow 0}2x = 2x\ .\] Finally, when an expression including \(h\) doesn’t involve division by \(h\), we can remove the \(\lim_{h\rightarrow 0}\) and just use \(h=0\) instead, so \[\lim_{h\rightarrow 0} h = 0\ .\]
Putting these together gives
\[\partial_x [x^2] = 2x + \lim_{h\rightarrow 0}h = 2x\]
We’ll write this as another differentiation rule.
- Quadratic rule: \(\partial_x [x^2] = 2x\)
19.4.3 The exponential rule
Let’s take on the exponential function \(h(x) \equiv e^x\):
\[\partial_x e^x = \lim_{h\rightarrow 0}\frac{e^{x+h} - e^x}{h} = e^x \lim_{h\rightarrow 0}\left[\frac{e^h - 1}{h}\right]\] At a glance, it can be hard to know what to make of \(\lim_{h\rightarrow 0} (e^h-1)/h\). Setting \(h=0\) in the denominator is perfectly legitimate and gives \(e^0 - 1 = 0\). But that still leaves the \(h\) in the numerator. Still, for any non-zero \(h\), the division is legitimate, so let’s see what happens as \(h \rightarrow 0\):
f <- makeFun((exp(h) - 1)/h ~ h)
f(0.1)## [1] 1.051709
f(0.01)## [1] 1.005017
f(0.001)## [1] 1.0005
f(0.0001)## [1] 1.00005
f(0.0000001)## [1] 1
f(0.0000000001)## [1] 1Setting \(h\) exactly to zero, however, won’t work: it produces NaN.
f(0)## [1] NaNSince \(\lim_{h\rightarrow 0} (e^h-1)/h = 1\), we have
- Exponentiation rule: \(\partial_x e^x = e^x\)
19.4.4 The reciprocal rule
Still another example: the reciprocal function, written equivalently as \(1/x\) or \(x^{-1}\)
\[\partial x^{-1} = \lim_{h\rightarrow 0}\frac{\frac{1}{x+h} - \frac{1}{x}}{h} \\ \ \\ = \lim_{h\rightarrow 0} \frac{\frac{x - (x+h)}{x(x+h)}}{h}\\ \ \\ = \lim_{h\rightarrow 0}\frac{x - x+h}{x(x+h)h} = -\lim_{h\rightarrow 0}\frac{h}{x(x+h)h} \\ \ \\ = -\lim_{h\rightarrow 0}\frac{1}{x^2 + hx}\] So long as \(x \neq 0\), there is no divide-by-zero problem even when \(h=0\), but let’s see what the computer thinks:
g <- makeFun(-1/(x^2 + h*x) ~ h, x=10)
g(0.1)## [1] -0.00990099
g(0.01)## [1] -0.00999001
g(0.001)## [1] -0.009999
g(0.0001)## [1] -0.0099999
g(0.0000001)## [1] -0.01
g(0.0000000001)## [1] -0.01
g(0)## [1] -0.01Setting \(h\) to zero in the last expression gives another differentiation rule:
- Reciprocal rule: \(\partial_x \frac{1}{x} = -\frac{1}{x^2}\)
19.4.5 Power-law rule
We don’t yet have the tools needed to prove a formula for the derivative of power-law functions, but we already have some instances where we know the derivative:
- \(\partial_x x^2 = 2 x\)
- \(\partial_x x^1 = 1\)
- \(\partial_x x^0 = 0\)
A rule that fits all these examples is \[\partial_x x^p = p\, x^{p-1}\ .\] For instance, when \(p=2\) the rule gives \[\partial_x x^2 = 2\, x^1 = 2 x\] since \(p-1\) will be 1$.
It’s not too hard to do the algebra to find the derivative of \(x^3\). According to the proposed rule, the derivative should be \[\partial_x x^3 = 3 x^2\ .\] Let’s check this via the definition of the derivative: \[\partial_x x^3 = \lim_{h \rightarrow 0}\frac{(x+h)^3 - x^3}{h}\] Direct multiplication \((x+h)(x+h)(x+h)\) gives \[(x+h)^3 = x^3 + 3\, x^2 h + 3\, x h^2 + h^3\] Consequently, the limit definition amounts to: \[\partial_x x^3 = \lim_{h\rightarrow 0}\frac{3\, x^2 h + 3\, x h^2 + h^3}{h} = \lim_{h\rightarrow 0} \left[\strut 3\, x^2 + 3\,x h + h^2\right]\] But there is no divide-by-\(h\) in sight, so we can resolve \(\lim_{h\rightarrow 0}\) to \(h=0\), giving \[\partial_x x^3 = 3 x^2\ ,\] consistent with the proposed rule.
Those familiar with the use of Pascal’s Triangle for finding the terms of binomial expansions such as \((x + h)^p\) will gain insight into the \(p x^{p-1}\) rule.
19.4.6 List of pattern-book rules
We’ll save for later the derivation of the derivatives of the other pattern-book functions, but note that the gaussian function is defined to be the derivative of the sigmoidal function.
| Name | \(f(x)\) | \(\partial_x f(x)\) |
|---|---|---|
| exponential | \(e^x\) | \(e^x\) |
| logarithm (natural) | \(\ln(x)\) | \(1/x\) |
| sinusoid | \(\sin(x)\) | \(\cos(x)\) |
| square | \(x^2\) | \(2x\) |
| proportional | \(x\) | \(1\) |
| constant | 1 | 0 |
| reciprocal | \(1/x\) or \(x^{-1}\) | \(-1/x^2\) |
| gaussian (hump) | \(\dnorm(x)\) | \(-x\, \dnorm(x)\) |
| sigmoid | \(\pnorm(x)\) | \(\dnorm(x)\) |
Figure 19.2: A diagram showing how differentiation connects the pattern-book functions to one another.
19.5 Exercises
Exercise 19.1: kelwx
The most common programming pattern in the R/mosaic calculus commands is:
Operator(tilde_expression, [optional details])
Some operators: slice_plot(), contour_plot, make_Fun(), D(), antiD(), findZeros()
For each of the R/mosaic expressions, determine which kind of thing is being created. Feel free to run the expressions in a SANDBOX.
`makeFun(a*x - b ~ x)` ( ) a function of `x` (x ) a function of `x`, `a`, and `b` ( ) a tilde expression ( ) a plot ( ) a data frame ( ) an error [[Good.]]
`D(a*x - b ~ x)` ( ) a function of `a` (x ) a function of `x`, `a`, and `b` ( ) a tilde expression ( ) a plot ( ) a data frame ( ) an error [[Right!]]
`antiD(a*x - b ~ x)` ( ) a function of `a` (x ) a function of `x`, `a`, and `b` ( ) a tilde expression ( ) a plot ( ) a data frame ( ) an error [[Good.]]
`slice_plot(a*x - b ~ x, domain(x=c(0,5)))` ( ) a function of `x` ( ) a function of `x`, `a`, and `b` ( ) a tilde expression ( ) a plot ( ) a data frame (x ) an error [[Excellent!]]
`f`findZeros(a*x - b ~ x, domain(x=c(0,5)))` ( ) a function of `x` ( ) a function of `x`, `a`, and `b` ( ) a tilde expression ( ) a plot ( ) a data frame (x ) an error [[Correct.]]`a*x - b ~ x` ( ) a function of `x` ( ) a function of `x`, `a`, and `b` (x ) a tilde expression ( ) a plot ( ) a data frame ( ) an error [[Right!]]`fSuppose you create a function in the usual way, e.g. `f
Exercise 19.2: K05LrF
As you know, given a function \(g(x)\) it’s easy to construct a new function \({\cal D}_x g(x)\) that will be an approximation to the derivative \(\partial_x g(x)\). The approximation function, which we call the slope function, can be \[{\cal D}_x g(x) \equiv \frac{g(x + 0.1) - g(x)}{0.1}\]
Open a SANDBOX and use makeFun() to create a function \(g(x) \equiv \sin(x)\) and another that will be the slope function, called it slope_of_g().
g <- makeFun(sin(x) ~ x)
slope_of_g <- makeFun( _your_tilde_expression_here )What's the value of `slope_of_g(1)`? ( ) 0.3749 (x ) 0.4973 ( ) 1.3749 ( ) 1.4973 [[Nice!]]
Using your sandbox, plot both g() and slope_of_g() (in blue) on a domain \(-5 \leq x \leq 5\). This can be done with slicePlot() in the following way:
slice_plot(g(x) ~ x, domain(x=c(-5,5))) %>%
slice_plot(slope_of_g(x) ~ x, color="blue")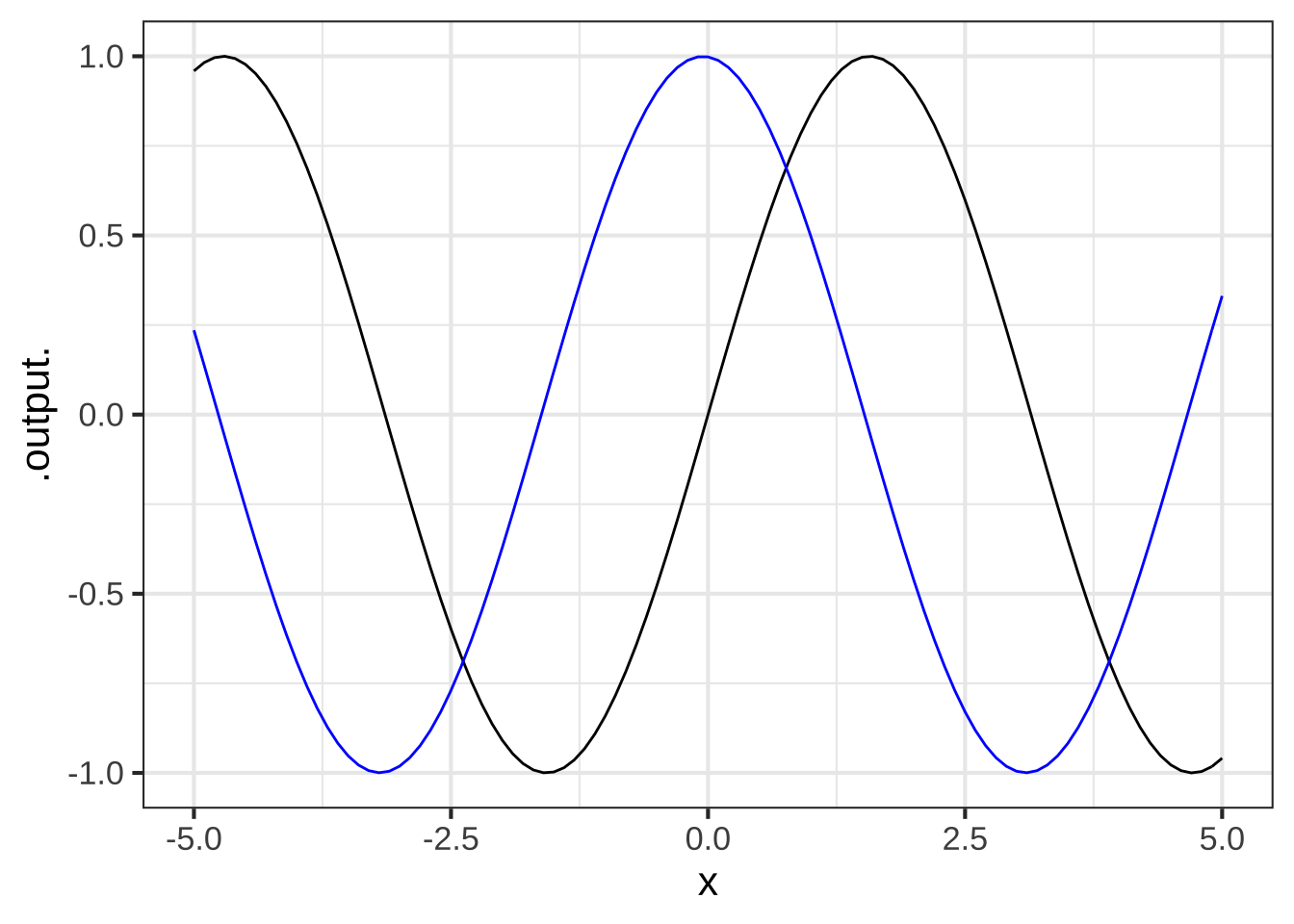
Which of these statements best describes the graph of $$g()$$ compared to `slope_of_g()`? (x ) `slope_of_g()` is shifted left by about $$\pi/2$$ compared to `g(x)`. ( ) `slope_of_g()` is shifted left by about $$\pi$$ compared to `g(x)`. ( ) `slope_of_g()` has a larger amplitude than `g()` ( ) The output of `slope_of_g()` is always positive ( ) `slope_of_g()` is practically the same function as `g()`. That is, for any input the output of the two functions is practically the same. [[Correct.]]
Exercise 19.5: qCfet3
Recall the differentiation rules for three of the pattern-book functions as presented in Section 19.4:
| Function name | Formula | Formula for derivative | power-law exponent \(p\) |
|---|---|---|---|
| Identity | \(x\) | \(1\) | 1 |
| Square | \(x^2\) | \(2\, x\) | 2 |
| Reciprocal | \(1/x\) | \(-1/x^2\) | -1 |
All three of these pattern-book functions are members of the power-law family: \(x^p\). They differ only in the value of \(p\).
There is a differentiation rule for the power-law family generally. The next question offers several formulas for this rule, only one of which is correct. You can figure out which one by trying the pattern-book functions in the table above and seeing which formula gives the correct answer for the derivative.
Which of these formulas gives the correct differentiation rule for the power-law family $$x^p$$?
(x ) $$p x^{p-1}$$
( ) $$(p-1) x^{p+1}$$
( ) $$x^{p-1}$$
( ) $$(p-1) x^{p-1}$$
[[Right!]]
Exercise 19.6: ykels
Although we created an R function named slopeFun() for the purposes of demonstration, it’s better to use the R/mosaic operator D() which calculates the derivative, sometimes using symbolic methods and sometimes using a finite-difference method.
As an example of the use of D(), here is some more R code that defines a function f() and finds \(\partial_x f()\), calling it d_f(). Then a slice plot is made of both f() and d_f().
f <- makeFun(sqrt(exp(x)) - x^2 ~ x)
d_f <- D(f(x) ~ x)
slice_plot(f(x) ~ x, domain(x=c(0, 5))) %>%
slice_plot(d_f(x) ~ x, color = "orange3")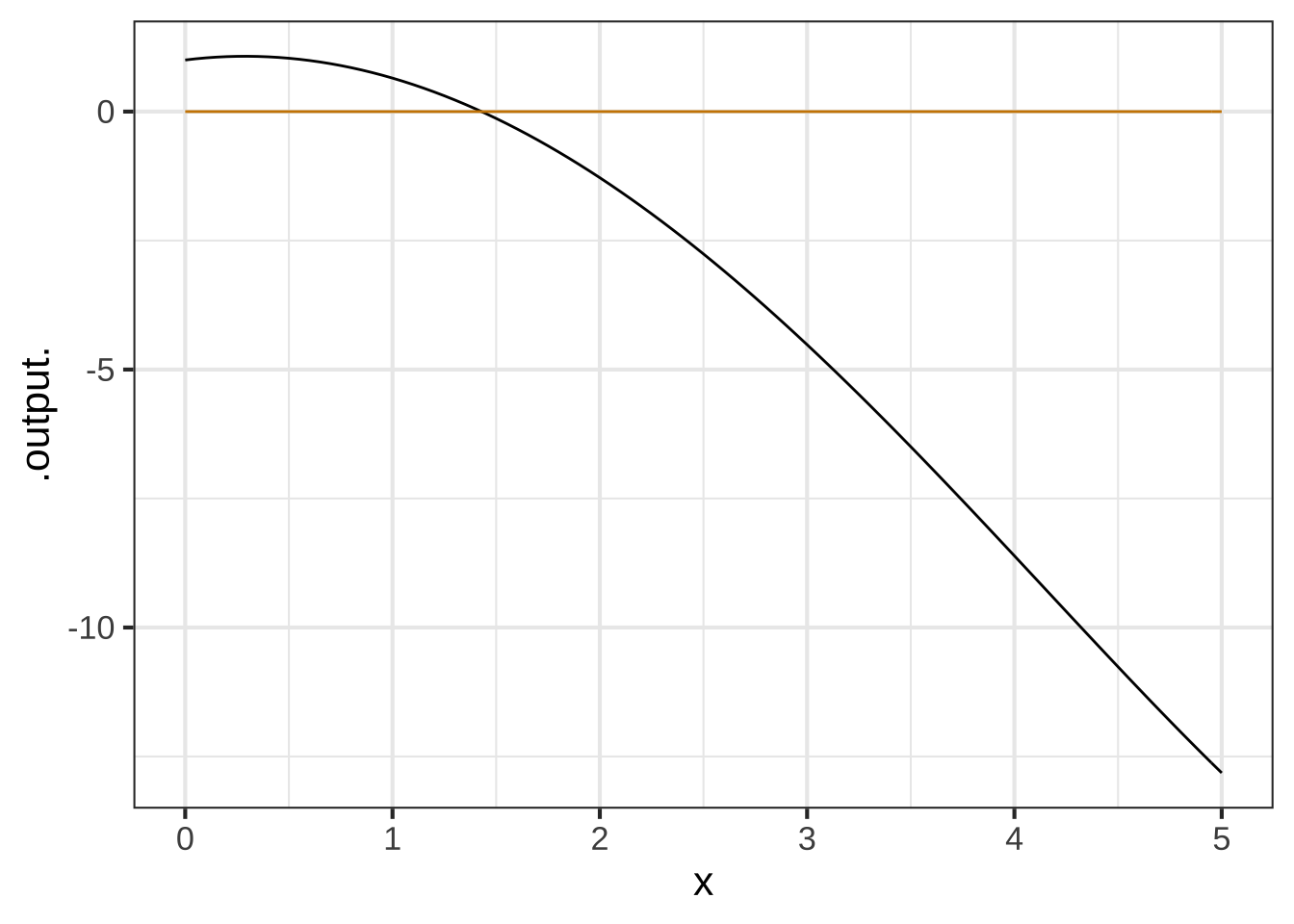 :::
:::For each of the following functions, write a brief comparison of the function to it’s differenced version. You can combine phrases such as “same shape,” “different shape. larger in amplitude,” “smaller in amplitude,” “same period,” “shorter period,” “longer period,” or whatever seems appropriate. For instance, for the original example in the sandbox, a reasonable comparison might be, “f() is concave down but Diff(f) is concave up.”
Essay question tmp-5: A. For the function \(f(x) \equiv 3 x\), compare \(f()\) to \(\partial_x f\).
Essay question tmp-6: B. For the function \(f(x) \equiv x^2\), compare \(f()\) to \(\partial_x f\).
Essay question tmp-7: C. For the function \(f(x) \equiv e^x\), compare \(f()\) to \(\partial_x f\).
Essay question tmp-8: D. For the function \(f(x) \equiv e^{-0.3 x}\), compare \(f()\) to \(\partial_x f\).
Essay question tmp-9: E. For the function \(f(x) \equiv \sin(x)\), compare \(f()\) to \(\partial_x f\).
Essay question tmp-10: F. For the function \(f(x) \equiv \sin(2 \pi x)\), compare \(f()\) to \(\partial_x f\)).
Essay question tmp-11: G. For the function \(f(x) \equiv \sin(\frac{2 \pi}{20} x)\), compare \(f()\) to \(\partial_x f\)).