Topic 7 Regularization, shrinkage and dimension reduction
7.1 Best subset selection
Algorithm 6.1 from ISLR
- Let \(M_0\) denote the null model, which contains no predictors. This model simply predicts the sample mean for each observation.
- For k in 1,2,…p:
- Fit all p models that contain exactly k predictors. \(\left(\begin{array}{c}k\\p\end{array}\right)\)
- Pick the best among these k models, and call it \(M_k\). Here best is defined as having the smallest RSS, or equivalently largest R\(^2\).
- Select a single best model from among \(M_0, \ldots , M_p\) using cross- validated prediction error, C\(_p\), AIC, BIC, or adjusted \(R^2\).
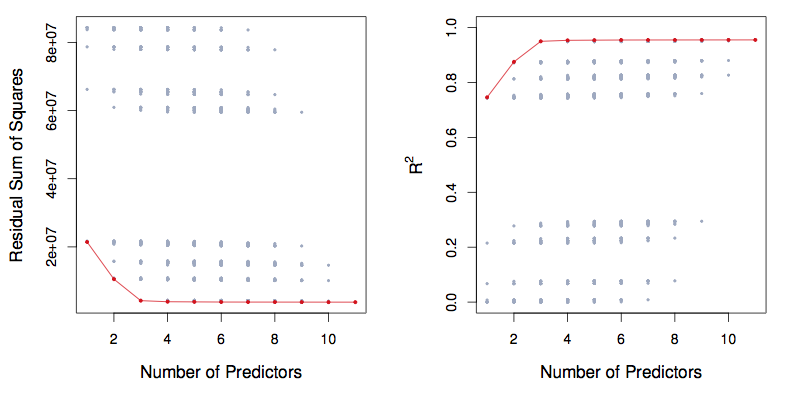
Figure 7.1: ISLR Figure 6.1. The models from best subset selection
7.2 Approximation to best subset selection
For large \(p\), there are too many possible models to fit all of them: \(2^p\). So, some heuristics.
- There are only \(p\) models with just one term: \(d = 1\). So easy to try all of them.
- There are only \(p(p-1)/2\) models with just two terms \(d = 2\). Again, easy to try all of them.
- Starting out from \(M_1\) or \(M_2\), keep all of those terms and look for the best individual term to add. There will be only \(p-(d-1)\) of them. We presume that one of these will be near the frontier of the best possible model with \(d\) terms.
- Repeat the process \(k \gg p\) times, moving forward and back randomly, adding a term or deleting a term.
- This will take roughly \(k p\) fits \(\alpha p^2\) fits, where \(\alpha\) is a constant \(k/p\), say 10.
- Compare this to \(2^p\). Setting \(\alpha = 10\), find the ratio \(\frac{2^p}{\alpha p^2}\) for \(p = 5, \ldots, 40\).
p <- 1:40
(2^p) / (10 * p^2)## [1] 2.000000e-01 1.000000e-01 8.888889e-02 1.000000e-01 1.280000e-01
## [6] 1.777778e-01 2.612245e-01 4.000000e-01 6.320988e-01 1.024000e+00
## [11] 1.692562e+00 2.844444e+00 4.847337e+00 8.359184e+00 1.456356e+01
## [16] 2.560000e+01 4.535363e+01 8.090864e+01 1.452321e+02 2.621440e+02
## [21] 4.755447e+02 8.665917e+02 1.585748e+03 2.912711e+03 5.368709e+03
## [26] 9.927347e+03 1.841121e+04 3.423922e+04 6.383721e+04 1.193046e+05
## [31] 2.234634e+05 4.194304e+05 7.887911e+05 1.486148e+06 2.804877e+06
## [36] 5.302429e+06 1.003937e+07 1.903587e+07 3.614437e+07 6.871948e+07Exhaustion seems find up through about \(d = 20\) — only 100 times more expensive than the random search.
7.3 Classical theory of best model choice
We punish models with lots of terms.
| In-sample | Adjusted | Out-of-sample |
|---|---|---|
| \(\frac{1}{n}\)RSS | \(C_p = \frac{1}{n}(\mbox{RSS} + 2 d \hat{\sigma}^2)\) | cross-validated prediction error |
| . | \(\mbox{AIC} = -2 \ln {\cal L} - 2 d\) | . |
| . | \(\mbox{AIC}_{ls} = \frac{1}{\hat{\sigma}^2}C_p\) | . |
| . | \(\mbox{BIC} = \frac{1}{n} (\mbox{RSS} + \ln(n) d \hat{\sigma}^2)\) | . |
| R\(^2\) | Adjusted R\(^2\) | ??? |
\(\mbox{Adjusted R}^2 = 1 - \frac{\mbox{RSS}/(n-d-1)}{\mbox{TSS}{(n-1)}}\)
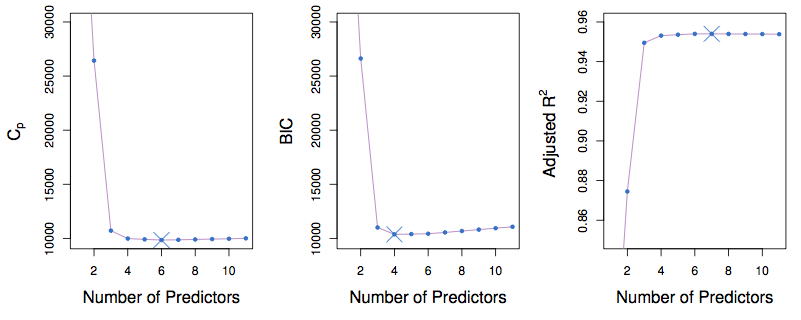
Figure 7.2: ISLR Figure 6.2. Note that the values on the vertical axis are the best for that “number of predictors.
Uncertainty
Repeat the analysis for different test sets or using different folds in k-fold cross validation.
- At each value of “Number of Predictors”, there will be a distribution.
- One-standard-error rule: select the smallest model for which the estimated test error is within one standard error of the lowest point on the curve.
7.4 Optimization
7.4.1 What are we optimizing over?
Choose the best set of columns from the model matrix.
Small <- mosaic::sample(mosaicData::KidsFeet, size = 5)
row.names(Small) <- NULL
M1 <- model.matrix(width ~ length + sex, data = Small)
M2 <- model.matrix(width ~ length + sex*biggerfoot, data = Small)
M3 <- model.matrix(width ~ length*domhand*sex + sex*biggerfoot, data = Small)7.5 Shrinkage methods
Example, a roughly quadratic cloud of points. Better to fit it with a constant, straight line, a quadratic?
- Depends on the amount of data.
- What if you have only n=3 or 4?
Constant will have the least sampling variation but the most bias.
Quadratic will have the least bias but the most sampling variation.
Shrinkage idea: Make a linear combination of the constant model with the “full” model.
7.5.1 Ridge regression
The objective function: minimize
\[\sum_{i=1}^n \left(y_i - \beta_0 - \sum_{j = 1}^p \beta_j x_{ij}\right)^2 + \lambda \sum_{j=1}^p \beta_j^2\]
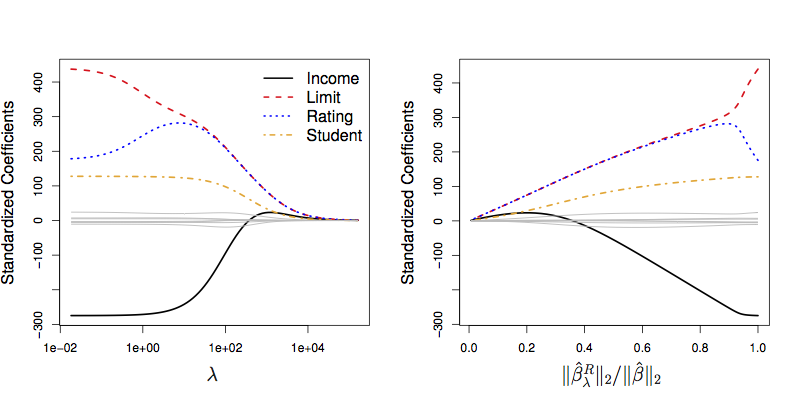
Figure 7.3: ISLR Figure 6.4.
Note the y-axis label: “Standardized Coefficients.”
- Remember that coefficients have units that depend on the response variable and the explanatory variable(s) participating in the coefficient.
- Those coefficients will typically be different from model term to model term.
- Meaningless to add up numbers with different physical dimension.
… So, standardize the explanatory variables.
Another perspective on the reason to standardize: Some of the coefficients might be huge numerically, others small. In such a situation, the huge coefficients will dominate; the small ones will have little influence on the shrinkage.
data(CPS85, package = "mosaic")## Warning in data(CPS85, package = "mosaic"): data set 'CPS85' not foundx <- model.matrix(wage ~ age + educ + sex + union + married, data = CPS85)
foo <- glmnet(x, CPS85$wage, alpha = 0)
foo$lambda.min## NULLpredict(foo,s=foo$lambda.min,exact=T,type="coefficients")## 7 x 100 sparse Matrix of class "dgCMatrix"## [[ suppressing 100 column names 's0', 's1', 's2' ... ]]##
## (Intercept) 9.024064e+00 8.9845500258 8.9807084640 8.9764945908
## (Intercept) . . . .
## age 7.833801e-38 0.0002223183 0.0002439361 0.0002676496
## educ 7.580412e-37 0.0021509145 0.0023600259 0.0025894031
## sexM 2.137431e-36 0.0060625175 0.0066516621 0.0072978516
## unionUnion 2.184744e-36 0.0061916460 0.0067927982 0.0074520479
## marriedSingle -1.097614e-36 -0.0031093285 -0.0034110717 -0.0037419469
##
## (Intercept) 8.971872561 8.9668031280 8.9612433278 8.9551461420
## (Intercept) . . . .
## age 0.000293661 0.0003221914 0.0003534828 0.0003878003
## educ 0.002840997 0.0031169438 0.0034195819 0.0037514703
## sexM 0.008006567 0.0087838090 0.0096361411 0.0105707449
## unionUnion 0.008174955 0.0089676003 0.0098366324 0.0107893174
## marriedSingle -0.004104736 -0.0045024806 -0.0049385043 -0.0054164378
##
## (Intercept) 8.9484601281 8.9411290199 8.933091297 8.9242797166
## (Intercept) . . . .
## age 0.0004254338 0.0004667008 0.000511948 0.0005615549
## educ 0.0041154088 0.0045144596 0.004951971 0.0054316019
## sexM 0.0115954738 0.0127189125 0.013950443 0.0153003109
## unionUnion 0.0118335936 0.0129781289 0.014232384 0.0156066793
## marriedSingle -0.0059402456 -0.0065142539 -0.007143182 -0.0078321724
##
## (Intercept) 8.9146208149 8.9040343629 8.8924327880 8.8797205546
## (Intercept) . . . .
## age 0.0006159361 0.0006755443 0.0007408743 0.0008124655
## educ 0.0059573508 0.0065335834 0.0071650649 0.0078569941
## sexM 0.0167797050 0.0184008330 0.0201770102 0.0221227462
## unionUnion 0.0171122647 0.0187613975 0.0205674209 0.0225448498
## marriedSingle -0.0085868290 -0.0094132503 -0.0103180689 -0.0113084920
##
## (Intercept) 8.8657934983 8.8505381222 8.833830848 8.81553723
## (Intercept) . . . .
## age 0.0008909068 0.0009768399 0.001070964 0.00117404
## educ 0.0086150384 0.0094453731 0.010354721 0.01135040
## sexM 0.0242538476 0.0265875170 0.029142461 0.03193901
## unionUnion 0.0247094586 0.0270783749 0.029670175 0.03250498
## marriedSingle -0.0123923429 -0.0135781042 -0.014874962 -0.01629285
##
## (Intercept) 8.795511112 8.773593781 8.749613049 8.723382330
## (Intercept) . . . .
## age 0.001286896 0.001410431 0.001545623 0.001693531
## educ 0.012440352 0.013633217 0.014938358 0.016365920
## sexM 0.034999211 0.038346996 0.042008261 0.046011017
## unionUnion 0.035604563 0.038992442 0.042693981 0.046736492
## marriedSingle -0.017842503 -0.019535481 -0.021384232 -0.023402122
##
## (Intercept) 8.694699697 8.66334692 8.629088521 8.591670836
## (Intercept) . . . .
## age 0.001855303 0.00203218 0.002225506 0.002436727
## educ 0.017926885 0.01963311 0.021497409 0.023533552
## sexM 0.050385511 0.05516435 0.060382633 0.066078045
## unionUnion 0.051149320 0.05596393 0.061213970 0.066935341
## marriedSingle -0.025603471 -0.02800358 -0.030618769 -0.033466351
##
## (Intercept) 8.550821131 8.506246777 8.457634524 8.404649905
## (Intercept) . . . .
## age 0.002667402 0.002919208 0.003193942 0.003493528
## educ 0.025756363 0.028181734 0.030826673 0.033709334
## sexM 0.072290980 0.079064621 0.086445009 0.094481084
## unionUnion 0.073166217 0.079947059 0.087320592 0.095331734
## marriedSingle -0.036564669 -0.039933055 -0.043591796 -0.047562072
##
## (Intercept) 8.346936807 8.284117277 8.21579158 8.141538616
## (Intercept) . . . .
## age 0.003820021 0.004175608 0.00456261 0.004983484
## educ 0.036849035 0.040266269 0.04398269 0.048021111
## sexM 0.103224702 0.112730595 0.12305630 0.134262014
## unionUnion 0.104027489 0.113456777 0.12367019 0.134719696
## marriedSingle -0.051865865 -0.056525832 -0.06156514 -0.067007279
##
## (Intercept) 8.060916717 7.973464940 7.878704903 7.776143265
## (Intercept) . . . .
## age 0.005440816 0.005937322 0.006475838 0.007059311
## educ 0.052405411 0.057160500 0.062312194 0.067887072
## sexM 0.146410399 0.159566289 0.173796323 0.189168465
## unionUnion 0.146658213 0.159539140 0.173415734 0.188340405
## marriedSingle -0.072875762 -0.079193859 -0.085984206 -0.093268375
##
## (Intercept) 7.665274929 7.54558705 7.416563927 7.27769283 7.1284709
## (Intercept) . . . . .
## age 0.007690785 0.00837338 0.009110276 0.00990468 0.0107598
## educ 0.073912294 0.08041537 0.087423891 0.09496517 0.1030659
## sexM 0.205751424 0.22361395 0.242824003 0.26344778 0.2855486
## unionUnion 0.204363867 0.22153418 0.239895671 0.25948770 0.2803434
## marriedSingle -0.101066377 -0.10939610 -0.118272683 -0.12770782 -0.1377091
##
## (Intercept) 6.96841279 6.79705996 6.61399012 6.41882823 6.2112579
## (Intercept) . . . . .
## age 0.01167879 0.01266472 0.01372055 0.01484901 0.0160526
## educ 0.11175163 0.12104636 0.13097192 0.14154739 0.1527884
## sexM 0.30918583 0.33441321 0.36127774 0.38981798 0.4200625
## unionUnion 0.30248814 0.32593832 0.35069962 0.37676565 0.4041166
## marriedSingle -0.14827895 -0.15941437 -0.17110566 -0.18333586 -0.1960801
##
## (Intercept) 5.9910334 5.7579921 5.51206649 5.25329617 4.98183860
## (Intercept) . . . . .
## age 0.0173335 0.0186935 0.02013392 0.02165556 0.02325861
## educ 0.1647066 0.1773089 0.19059658 0.20456512 0.21920324
## sexM 0.4520282 0.4857189 0.52112390 0.55821629 0.59695227
## unionUnion 0.4327179 0.4625192 0.49345370 0.52543758 0.55837010
## marriedSingle -0.2093050 -0.2229683 -0.23701831 -0.25139453 -0.26602738
##
## (Intercept) 4.69797856 4.40213581 4.09487021 3.77688286 3.44901969
## (Intercept) . . . . .
## age 0.02494258 0.02670626 0.02854762 0.03046385 0.03245118
## educ 0.23449256 0.25040721 0.26691358 0.28397034 0.30152843
## sexM 0.63727009 0.67908961 0.72231213 0.76682031 0.81248048
## unionUnion 0.59213404 0.62659667 0.66161129 0.69701946 0.73265266
## marriedSingle -0.28083903 -0.29574427 -0.31065174 -0.32546539 -0.34008662
##
## (Intercept) 3.11226065 2.76771551 2.41661109 2.06027583 1.70012110
## (Intercept) . . . . .
## age 0.03450504 0.03661995 0.03878962 0.04100694 0.04326407
## educ 0.31953158 0.33791673 0.35661486 0.37555188 0.39464982
## sexM 0.85914169 0.90663875 0.95479401 1.00341984 1.05232141
## unionUnion 0.76833644 0.80389287 0.83914426 0.87391666 0.90804331
## marriedSingle -0.35441592 -0.36835537 -0.38181085 -0.39469431 -0.40692595
##
## (Intercept) 1.33761998 0.97428376 0.61163733 0.25119401 -0.10556916
## (Intercept) . . . . .
## age 0.04555258 0.04786348 0.05018744 0.05251487 0.05483612
## educ 0.41382804 0.43300458 0.45209753 0.47102648 0.48971376
## sexM 1.10129972 1.15015470 1.19868837 1.24670797 1.29402881
## unionUnion 0.94136790 0.97374751 1.00505497 1.03518081 1.06403449
## marriedSingle -0.41843607 -0.42916675 -0.43907299 -0.44812347 -0.45630085
##
## (Intercept) -0.45723496 -0.80246738 -1.14003052 -1.46880417 -1.78779598
## (Intercept) . . . . .
## age 0.05714158 0.05942192 0.06166817 0.06387188 0.06602526
## educ 0.50808576 0.52607395 0.54361585 0.56065574 0.57714518
## sexM 1.34047696 1.38589155 1.43012672 1.47305307 1.51455874
## unionUnion 1.09154508 1.11766129 1.14235091 1.16559986 1.18741066
## marriedSingle -0.46360157 -0.47003518 -0.47562331 -0.48039836 -0.48440181
##
## (Intercept) -2.09614984 -2.39315067 -2.6782256 -2.95094196 -3.21100222
## (Intercept) . . . . .
## age 0.06812123 0.07015356 0.0721169 0.07400677 0.07581963
## educ 0.59304334 0.60831709 0.6229410 0.63689689 0.65017384
## sexM 1.55455004 1.59295153 1.6297059 1.66477322 1.69813027
## unionUnion 1.20780080 1.22680071 1.2444518 1.26080428 1.27591536
## marriedSingle -0.48768253 -0.49029496 -0.4922973 -0.49374981 -0.49471329
##
## (Intercept) -3.45823680 -3.69259470 -3.91413280 -4.12300419 -4.31944604
## (Intercept) . . . . .
## age 0.07755284 0.07920461 0.08077398 0.08226072 0.08366532
## educ 0.66276734 0.67467888 0.68591532 0.69648818 0.70641303
## sexM 1.72976918 1.75969624 1.78793039 1.81450170 1.83944980
## unionUnion 1.28984720 1.30266526 1.31443681 1.32522960 1.33511079
## marriedSingle -0.49524770 -0.49541101 -0.49525830 -0.49484107 -0.49420673
##
## (Intercept) -4.50376732 -4.67633677 -4.83757141 -4.98792574 -5.12788178
## (Intercept) . . . . .
## age 0.08498886 0.08623295 0.08739966 0.08849141 0.08951095
## educ 0.71570878 0.72439708 0.73250174 0.74004811 0.74706270
## sexM 1.86282238 1.88467367 1.90506303 1.92405372 1.94171161
## unionUnion 1.34414606 1.35239889 1.35993009 1.36679741 1.37305531
## marriedSingle -0.49339833 -0.49245445 -0.49140918 -0.49029227 -0.48912933
##
## (Intercept) -5.25794016 -5.3786121 -5.49041268 -5.59385451 -5.6894432
## (Intercept) . . . . .
## age 0.09046123 0.0913454 0.09216668 0.09292837 0.0936338
## educ 0.75357262 0.7596053 0.76518802 0.77034787 0.7751113
## sexM 1.95810424 1.9732998 1.98736634 2.00037119 2.0123803
## unionUnion 1.37875481 1.3839435 1.38866554 1.39296178 1.3968698
## marriedSingle -0.48794212 -0.4867489 -0.48556453 -0.48440129 -0.4832687
##
## (Intercept) -5.77767290 -5.85902333 -5.93390991 -6.00287296 -6.06628568
## (Intercept) . . . . .
## age 0.09428624 0.09488895 0.09544397 0.09595664 0.09642875
## educ 0.77950393 0.78355064 0.78727494 0.79070015 0.79384759
## sexM 2.02345769 2.03366541 2.04306574 2.05170968 2.05965435
## unionUnion 1.40042429 1.40365684 1.40658991 1.40926359 1.41169502
## marriedSingle -0.48217421 -0.48112327 -0.48012751 -0.47917354 -0.47827092For Credit dataset: http://www-bcf.usc.edu/~gareth/ISL/Credit.csv
7.6 LASSO
The objective function: minimize
\[\sum_{i=1}^n \left(y_i - \beta_0 - \sum_{j = 1}^p \beta_j x_{ij}\right)^2 + \lambda \sum_{j=1}^p |\beta_i|\] Almost exactly the same as ridge regression. But the small change makes a big difference.

Figure 7.4: ISLR Figure 6.7.
x <- model.matrix(wage ~ age * educ * sex * union * married, data = CPS85)
foo <- cv.glmnet(x, CPS85$wage, alpha = 1)
foo$lambda.min## [1] 0.1263735predict(foo,s=foo$lambda.min,exact=T,type="coefficients")## 33 x 1 sparse Matrix of class "dgCMatrix"
## 1
## (Intercept) -1.9708098459
## (Intercept) .
## age .
## educ 0.5482123152
## sexM .
## unionUnion 1.1057230664
## marriedSingle .
## age:educ 0.0054884080
## age:sexM 0.0559924024
## educ:sexM .
## age:unionUnion .
## educ:unionUnion .
## sexM:unionUnion .
## age:marriedSingle .
## educ:marriedSingle .
## sexM:marriedSingle .
## unionUnion:marriedSingle .
## age:educ:sexM 0.0003101264
## age:educ:unionUnion .
## age:sexM:unionUnion .
## educ:sexM:unionUnion .
## age:educ:marriedSingle .
## age:sexM:marriedSingle .
## educ:sexM:marriedSingle -0.0453647898
## age:unionUnion:marriedSingle .
## educ:unionUnion:marriedSingle .
## sexM:unionUnion:marriedSingle .
## age:educ:sexM:unionUnion .
## age:educ:sexM:marriedSingle .
## age:educ:unionUnion:marriedSingle -0.0002003640
## age:sexM:unionUnion:marriedSingle .
## educ:sexM:unionUnion:marriedSingle .
## age:educ:sexM:unionUnion:marriedSingle .7.7 Review
We started by considering one mathematical representation of the problem: Choose \(\beta_1, \beta_2, \ldots, \beta_p\) to minimize this objective function
\[\sum_{i=1}^n \left(y_i - \beta_0 - \sum_{j = 1}^p \beta_j x_{ij}\right)^2 + \lambda \sum_{j=1}^p \beta_j^2\] The result depends on the value of \(\lambda\), which is often called the Lagrange multiplier.
The motivation for this form of the objective function is rooted in two different and conflicting goals:
- Get the model as close as possible to the data: minimize the sum of square errors.
- Keep the \(\beta\)’s small: minimize the model variance.
Reductio ad absurdum argument. Suppose \(\lambda \rightarrow \infty\). Then the best \(\beta\)’s would be zeros. Such a model has zero model variance, since we’ll get exactly the same result on every data set used to train the model.
Another way to think about multi-objective optimization …
We have several goals as a function of the adjustable parameters. Let’s denote them by \(g_1(x), g_2(x), g_3(x), \ldots\). For instance, suppose \(g_1(x)\) is the appeal of a meal as a function of the ingredients, \(g_2(x)\) is the vitamin content, \(g_3(x)\) is the protein content, \(g_4(x)\) is the amount of salt, and so on.
We want to find the parameters \(x\) that minimize some mixture of the objectives, e.g.
\[T(x; \lambda_1, \lambda_2, \ldots) \equiv \lambda_1 g_1(x) + \lambda_2 g_2(x) + \ldots\] We don’t know what the \(\lambda\)’s are; they reflect the relative importance of the different components of the objective function. We could, of course, make them up. But instead …
- Let’s choose one of the components to be our sole objective. It can be any of the components, the end result will be the same regardless. The others we will consider as constraints. For instance, we might take taste (\(g_1(x)\)) as our objective but impose constraints: calories should be between 800 and 1200, salt should be below 1200 mg, protein should be above 50 grams.
- Consider all the values of \(x\) that satisfy the constraints. Search over these to find the one that maximizes our selected objective component. This is called constrained optimization.
- Consider each of the constraints. Find out how much the selected objective will improve if we relax that constraint a bit, say allowing salt to be 1300 mg. The ratio is the Lagrange multiplier \(\lambda_i\).
\[\frac{\mbox{change in taste}}{\mbox{change in constraint}_i} \equiv \lambda_i\]
Now ask questions about priorities: If I were to ease up on the constraint, would I get enough change in the objective to be worthwhile? Or, if I were to tighten the constraint, would the resulting change in objective be acceptable? Change the constraints accordingly until you no longer see a net gain by changing the constraints.
Let’s translate this to ridge and lasso regression.
- The selected component of the overall objective: Minimize the in-sample sum of square error.
- The constraint: how big are we willing to make the coefficients? (Remember, by standardizing the variables we make it possible to calculate a total size.)
- Evaluating the trade-offs between constraints and objectives: does the out-of-sample prediction error get smaller.
The picture:
- the red shows the objective function
- the blue shows the permitted region for the coefficients to satisfy the constraint.
Figure 7.5: ISLR Figure 6.7.
We can imagine increasing or decreasing the constraints, and will get a different optimum at each level of the constraint.
Why the circle and diamond?
Three different “metrics,” that is three different ways of combining parts to get an overall size.
- \(L^2\) — square-root of the sum of squares. The usual Euclidean distance. Circle
- \(L^1\) — sum of the absolute values. Sometimes called the Manhattan metric. Diamond
- \(L^\infty\) — the biggest individual value. Square.
Predicting Salary in the ISLR::Hitters data:
Without_NA <- na.omit(ISLR::Hitters)
inds <- sample(nrow(Without_NA), size = nrow(Without_NA)/2)
Train <- Without_NA[inds,]
Test <- Without_NA[-inds,]
y_all <- Without_NA$Salary
x_all <- model.matrix(Salary ~ ., data=Without_NA)
y_train <- Train$Salary
x_train <- model.matrix(Salary ~ ., data=Train)
y_test <- Test$Salary
x_test <- model.matrix(Salary ~ ., data=Test)
ridge_mod <- cv.glmnet(x_train, y_train, alpha = 0)
ridge_mod$lambda.min
ridge_pred <- predict(ridge_mod, s=0, newx = x_test, exact=TRUE)
mean((ridge_pred - y_test)^2)
final <- glmnet(x_all, y_all, alpha=0)
predict(final, type="coefficients", s=ridge_mod$lambda.min)Lasso: Do we really need all of those variables?
lasso_mod <- cv.glmnet(x_train, y_train, alpha = 1)
lasso_mod$lambda.min
lasso_pred <- predict(lasso_mod, s=0, newx = x_test, exact=TRUE)
mean((lasso_pred - y_test)^2)
final <- glmnet(x_all, y_all, alpha=1)
predict(final, type="coefficients", s=lasso_mod$lambda.min)Figure 7.6: ISLR Figure 6.4
Figure 7.7: ISLR Figure 6.7
7.8 Multi-collinearity
The SAT story.
summary(lm(sat ~ expend, data=mosaicData::SAT))$coef## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1089.29372 44.389950 24.539197 8.168276e-29
## expend -20.89217 7.328209 -2.850925 6.407965e-03summary(lm(sat ~ expend + ratio, data=mosaicData::SAT))$coef## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1136.335547 107.803485 10.5408053 5.693212e-14
## expend -22.307944 7.955544 -2.8040751 7.313013e-03
## ratio -2.294539 4.783836 -0.4796442 6.337049e-01summary(lm(sat ~ expend + ratio + salary, data=mosaicData::SAT))$coef## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1069.234168 110.924940 9.6392585 1.292219e-12
## expend 16.468866 22.049899 0.7468907 4.589302e-01
## ratio 6.330267 6.542052 0.9676272 3.382908e-01
## salary -8.822632 4.696794 -1.8784372 6.666771e-02mosaic::rsquared(lm(expend ~ ratio + salary, data=mosaicData::SAT))## [1] 0.893476
Figure 7.8: Confidence interval explanation
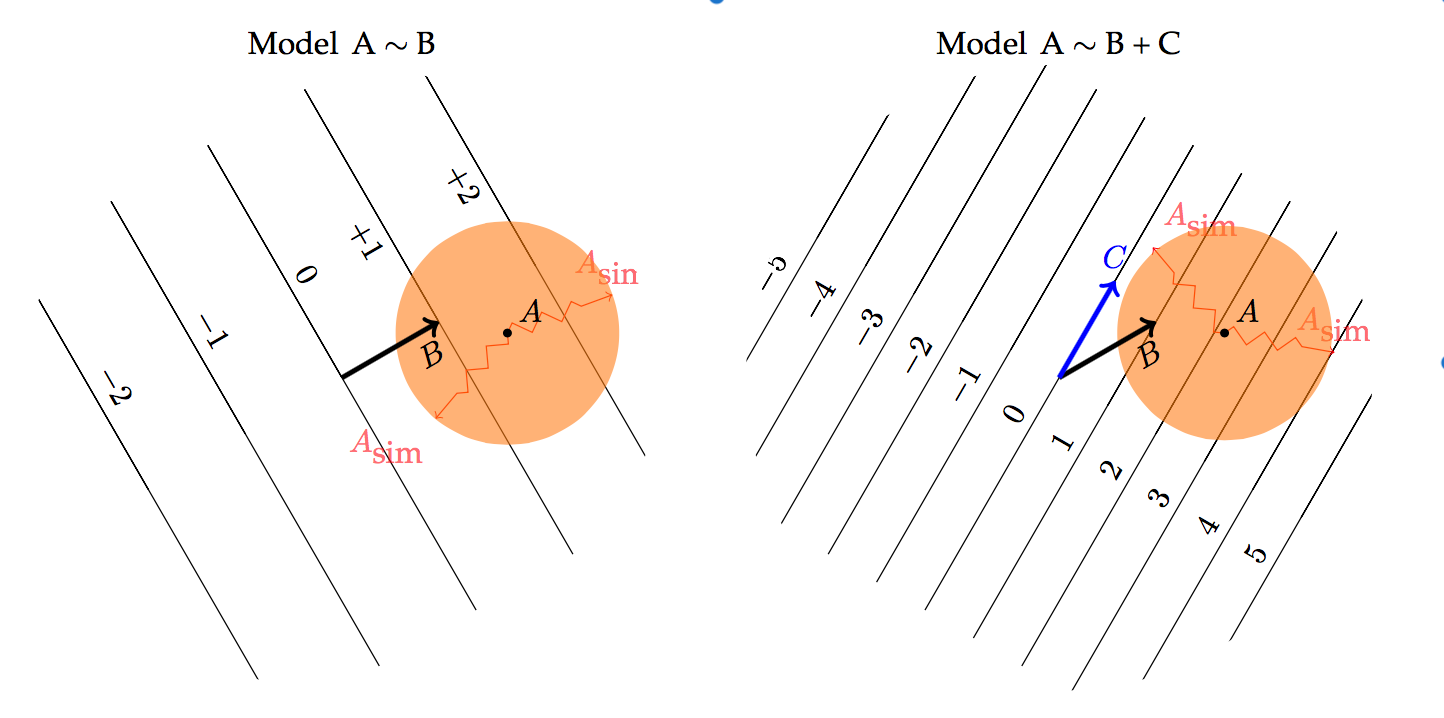
Figure 7.9: Confidence interval explanation, part 2
load("Images/mona.rda")
rankMatrix(mona)## [1] 191
## attr(,"method")
## [1] "tolNorm2"
## attr(,"useGrad")
## [1] FALSE
## attr(,"tol")
## [1] 5.551115e-14# pick a vector at random; column 151 versus the first 131 columns
mosaic::rsquared(lm(t(mona)[,151] ~ t(mona)[,-151]))## [1] 0.9999636Variance inflation factor
\(\mbox{VIF}(\beta_j) = \frac{1}{1 - R^2_{x_j|x_{-j}}}\)
Getting rid of vectors that correlate substantially with one another can reduce the variance inflation factor.
7.9 Creating correlations
Generate points on circles of radius 1, 2, 3, …
make_circles <- function(radii = 1:2, nangs = 30) {
theta = seq(0, 2*pi, length = nangs)
x <- rep(cos(theta), length(radii))
y <- rep(sin(theta), length(radii))
r <- rep(radii, each = nangs)
col <- rep(rainbow(nangs), length(radii))
data.frame(x = x * r, y = y * r, r = r, col = col)
}
transform_circles <- function(M, circles = NULL) {
if (is.null(circles)) circles <- make_circles()
XY <- rbind(circles$x, circles$y)
new <- M %*% XY
circles$x = new[1, ]
circles$y = new[2, ]
circles
}
Trans <- matrix(c(1, 2, -3, -1), nrow = 2, byrow = TRUE)
After_trans <- transform_circles(Trans)
plot(y ~ x, data = After_trans, col = (After_trans$col), asp = 1, pch = 20)
svals <- svd(Trans)
Start <- make_circles()
plot(y ~ x, data = Start, col = Start$col, asp = 1, pch = 20)
After_V <- transform_circles(t(svals$v), Start)
plot(y ~ x, data = After_V, col = After_V$col, asp = 1, pch = 20)
After_V_lambda <- transform_circles(diag(svals$d), After_V)
plot(y ~ x, data <- After_V_lambda, col = After_V_lambda$col, asp = 1, pch = 20)
After_V_lambda_U <- transform_circles(svals$u, After_V_lambda)
plot(y ~ x, data = After_V, col = After_V_lambda_U$col, asp = 1, pch = 20)
7.10 Rank 1 Matrices
Suppose all the columns in a matrix are simple multiples of the first column. All of the columns would be exactly collinear, so lm() will produce NA for all but one of the coefficients (putting the intercept aside). Lasso would zero out all but one of the coefficients, ridge would …
set.seed(101)
one <- outer(rnorm(100), rnorm(10))
two <- outer(rnorm(100), rnorm(10))
three <- outer(rnorm(100), rnorm(10))
y <- rnorm(100) + 7 * one[, 1] - 2 * two[, 1]
x <- one + two
dim(one)## [1] 100 10lm(y ~ x)##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x1 x2 x3 x4
## -0.06554 -17.08557 -10.65980 NA NA
## x5 x6 x7 x8 x9
## NA NA NA NA NA
## x10
## NAlasso_mod <- cv.glmnet(x, y, alpha = 1)
lasso_mod$lambda.min## [1] 0.02322399predict(lasso_mod, type="coefficients", s=lasso_mod$lambda.min)## 11 x 1 sparse Matrix of class "dgCMatrix"
## 1
## (Intercept) -0.06467677
## V1 .
## V2 .
## V3 .
## V4 .
## V5 .
## V6 -3.00961477
## V7 .
## V8 .
## V9 -2.19570742
## V10 .ridge_mod <- cv.glmnet(one, y, alpha = 0)
ridge_mod$lambda.min## [1] 2.046288predict(ridge_mod, type="coefficients", s=ridge_mod$lambda.min)## 11 x 1 sparse Matrix of class "dgCMatrix"
## 1
## (Intercept) 0.12330285
## V1 0.52231401
## V2 -0.23757058
## V3 0.06598347
## V4 0.11986807
## V5 0.18788200
## V6 -0.60749645
## V7 1.59250740
## V8 -0.06389472
## V9 -0.29849103
## V10 0.082470907.11 Idea of singular values.
Find orthogonal vectors to describe the ellipsoidal cloud. The singular value describes “how long” each ellipsoidal axis is.
Correlation \(R^2_{x_j | x_{-j}}\) gets increased for each direction that overlaps between \(x_j\) and \(x_{-j}\) — it doesn’t matter how big the singular value is in that direction. Only by throwing out directions can we reduce \(R^2_{x_j | x_{-j}}\)
Nice illustration:

{kind=link}
7.12 Dimension reduction
Re-arrange the variables to squeeze the juice out of them.
- Matrix
- Approximate matrix in a least squares sense. If that approximation includes the same column or more, we can discard the repeats.
- Outer product
- Rank-1 matrix constructed by creating multiples of one column.
- Create another vector and another rank-1 matrix. Add it up and we get closer to the target.
Creating those singular vectors:
- singular value decomposition
- \({\mathbf D}\) gives information on how big they are
- orthogonal to one another
- cumulative sum of \({\mathbf D}\) components gives the amount of variance in the approximation.
res <- svd(mona)
approx <- 0
for (i in 1:10) {
approx <- approx + outer(res$u[,i], res$v[,i]) * res$d[i]
}
image(approx, asp=1)
Picture in terms of gaussian cloud. The covariance matrix tells all that you need.
Using pcr() to fit models, interpreting the output.
library(pls)##
## Attaching package: 'pls'## The following object is masked from 'package:stats':
##
## loadingspcr.fit <- pcr(Salary ~ ., data = ISLR::Hitters, scale=TRUE, validation="CV")
summary(pcr.fit)## Data: X dimension: 263 19
## Y dimension: 263 1
## Fit method: svdpc
## Number of components considered: 19
##
## VALIDATION: RMSEP
## Cross-validated using 10 random segments.
## (Intercept) 1 comps 2 comps 3 comps 4 comps 5 comps 6 comps
## CV 452 354.3 353.2 353.7 351.6 348.7 345.2
## adjCV 452 353.9 352.7 353.1 350.9 348.0 344.3
## 7 comps 8 comps 9 comps 10 comps 11 comps 12 comps 13 comps
## CV 345.8 349.3 351.5 357.6 358.9 361.6 362.3
## adjCV 344.9 348.2 350.3 356.0 357.1 359.8 360.4
## 14 comps 15 comps 16 comps 17 comps 18 comps 19 comps
## CV 355.4 355 346.7 346.4 346.0 349.4
## adjCV 353.3 353 344.6 344.3 343.7 346.9
##
## TRAINING: % variance explained
## 1 comps 2 comps 3 comps 4 comps 5 comps 6 comps 7 comps
## X 38.31 60.16 70.84 79.03 84.29 88.63 92.26
## Salary 40.63 41.58 42.17 43.22 44.90 46.48 46.69
## 8 comps 9 comps 10 comps 11 comps 12 comps 13 comps 14 comps
## X 94.96 96.28 97.26 97.98 98.65 99.15 99.47
## Salary 46.75 46.86 47.76 47.82 47.85 48.10 50.40
## 15 comps 16 comps 17 comps 18 comps 19 comps
## X 99.75 99.89 99.97 99.99 100.00
## Salary 50.55 53.01 53.85 54.61 54.61validationplot(pcr.fit, val.type = "MSEP")