Chapter 2 Data and variables
Only in the second half of the twentieth century was the organization of data treated as a serious topic. Classical inference, emerging mainly in the period 1880-1925, was developed without reference to standard formats for data. Without automated methods of data handling, each researcher was confronted with the “oppressive necessity of reducing his results to a more convenient bulk.”1
Although this book is a guide to classical inference, we will work with data in a contemporary, standard format. This simplifies inference since we do not need to develop different statistical methodologies to deal with the diverse ways in which raw data can be reduced to a “convenient bulk.”
This chapter is about the organization of data. Later, we’ll work with a standard form for reducing data: statistical model functions.
2.1 Data frames
The data we use is organized into data frames, which are more or less spreadsheets. The columns of the data frame are variables, the rows of the data frame are units of observation.
As an example, consider data collected by Francis Galton, one of the pioneers of statistics. In the 1880s, seeking to understand genetic inheritance from parent to child, Galton visited almost 200 families in London with both parents living and children who had grown up. Galton recorded the height of the mother and father, and the height and sex of each of the adult children. Figure 2.1 shows part of the data frame.
| family | father | mother | sex | height | nkids |
|---|---|---|---|---|---|
| 1 | 78.5 | 67.0 | M | 73.2 | 4 |
| 1 | 78.5 | 67.0 | F | 69.2 | 4 |
| 1 | 78.5 | 67.0 | F | 69.0 | 4 |
| 1 | 78.5 | 67.0 | F | 69.0 | 4 |
| 2 | 75.5 | 66.5 | M | 73.5 | 4 |
| 2 | 75.5 | 66.5 | M | 72.5 | 4 |
| 2 | 75.5 | 66.5 | F | 65.5 | 4 |
| 2 | 75.5 | 66.5 | F | 65.5 | 4 |
| 3 | 75.0 | 64.0 | M | 71.0 | 2 |
| 3 | 75.0 | 64.0 | F | 68.0 | 2 |
| … and so on for 898 rows altogether. |
Each row corresponds to a unit of analysis, in this case, a person. The first row is a 6 foot 1.2 inch man in a family with 4 kids altogether. Looking at the next three rows, you see his three sisters, who are quite tall for the time (5 foot 9 inches) but not as tall as their parents. Their mother was a bit shorter (5 foot 7) and their father was very tall even by today’s standards: 6 feet 6.5 inches.
The family is designated with a number. So all four of the first rows are kids in family one, while rows 5 and 6 come from family two.
Most of the variables are numeric, as appropriate for height and the number of kids. One variable, sex, has values that are labels, M and F here, standing for male and female. Such variables are called categorical; the possible labels are the levels of the variable. In this book, categorical variables with two levels will play a very important role, but certainly there are categorical variables with more than two levels, as we shall see.
2.2 Tabulations
Historically, when data was shared by printing it and when calculations were tedious, data would often be presented as tabulations. For instance, one of the very early (Bateson, Saunders, and Punnett (1905), p. 93) investigations of cross-linkage in genetics examined 799 sweet pea plants, recording the color of the flower and whether the pollen was round or elongated.
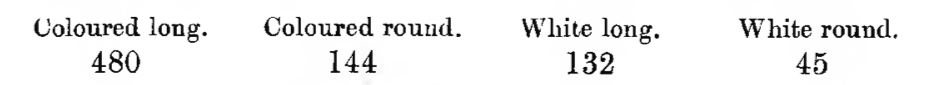
Figure 2.2: Genetics data from 1905
This style of presentation is perfectly understandable, but it is not in the modern format for data. As a data frame, the observations underlying Figure 2.2 would look like Figure 2.3:
| ID | flower_color | pollen_shape |
|---|---|---|
| SP1500 | other | long |
| SP5730 | other | round |
| SP6440 | white | long |
| SP3810 | other | long |
| SP3890 | other | long |
| SP6120 | other | round |
| … and so on for 801 rows altogether. |
You may well wonder what benefit there is to working with an 801-row data frame rather than the simple tabulation in the original publication. First, giving the variables names allows us to distinguish between the variable being measured and the level of the measurement. Second, the table makes clear that both variables flower_color and pollen_shape are categorical. Third, suppose there was some other aspect being recorded about the plants, for instance the plant’s height or how much water the plant was given or the name of the technician who recorded the data. Using a data frame, these new variables can easily be added as additional columns. There’s no space in the tabulation for these additional measurements.
A fourth reason to prefer the data-frame format for the genetics data is subtle. Most often, you will be using software to analyze data. Storing data in a consistent way – data frames – makes it much easier to use standard software than if the data are stored in a (pointless) variety of formats.
2.3 Quantitative and categorical variables
The fundamental distinction to be made between types of variables is whether they are quantitative – a number – or categorical. Categorical variables are those where the possible values come from a set of discrete categories and are typically represented by text labels.
In the Galton data (Figure 1), height is a quantitative variable. Sex is a categorical variable. The family variable has been encoded as a number, but it is not really numerical. For instance, with numbers, 2 is half way between 1 and 3. But family 2 is not “between” families 1 and 3 in any genuinely numerical sense. So family is a categorical variable.
Much later in the book, we will translate categorical variables into a set of very simple numerical variables, each of which is called an indicator variable. In an indicator variable, the only allowed values are zero and one.
Obviously, with just zero and one as possible values, a single indicator variable is not able to represent completely a categorical variable with three or more levels. In such situations, a set of indicator variables is used. If there are k different levels for the categorical variable, the equivalent set of indicator variables will have k - 1 members. For instance, a variable fruit with three levels “apple,” “blueberry,” and “cherry,” will correspond to two indicator variables. The first one might be whether the fruit is apple or not. The second would be whether the fruit is blueberry or not. When both the first and second take on the value zero, we know that the fruit must be the remaining level, cherry. Figure 5 shows the example on a case by case basis.
fruit |
\(\rightarrow\) | indicator apple | & | indicator blueberry |
|---|---|---|---|---|
| cherry | 0 | 0 | ||
| apple | 1 | 0 | ||
| blueberry | 0 | 1 | ||
| apple | 1 | 0 | ||
| cherry | 0 | 0 |
Figure 5: An example of how a categorical variable (‘fruit’) can be translated into simple indicator variables. Note that there is always at most a single 1 in each row of the table.
2.4 Response and explanatory variables
Starting in Chapter 4, we will work with a standard format for reducing the potentially many rows and variables of a data frame into a single compact object: a statistical model. For our purposes, a statistical model will be a function that takes inputs and produces an output. In particular, the inputs to each statistical model will be the values of selected variables in the data frame generically called explanatory variables. The output of the statistical model will be in terms of the values of a single, selected variable generically called the response variable.
The appropriate choice of a response variable and explanatory variables for a model depends on the question that you, the statistical investigator seek to address. Often, to address a broad question, you will use several different statistical models based on the same data frame.
Once you have selected the response and explanatory variables (and a few other details) the process of constructing the corresponding statistical model is a matter of routine calculation, which is always automated. Many people find they can anticipate the results of the calculation for simple models by sketching the graph of a function on a plot of the variables. We delegate the “oppressive necessity” of the exact calculations to a computer, leaving our role to give the computer an order: “Fit the model to the data.”
Keep in mind that response and explanatory variables are not types of variables, they are choices that we make in building a model. This not withstanding, in this book all models will have a response variable that is quantitative. If a categorical variable is to be involved in the response, it will have to be in the form of an indicator variable. On the other hand, explanatory variables can be either quantitative or categorical in any combination.
References
Bateson, W., E.R. Saunders, and R.C. Punnett. 1905. “Experimental Studies in the Physiology of Heredity.” Reports to the Evolution Committee of the Royal Society 2: 1–55, 80–99.
Fisher (1934) p.6↩