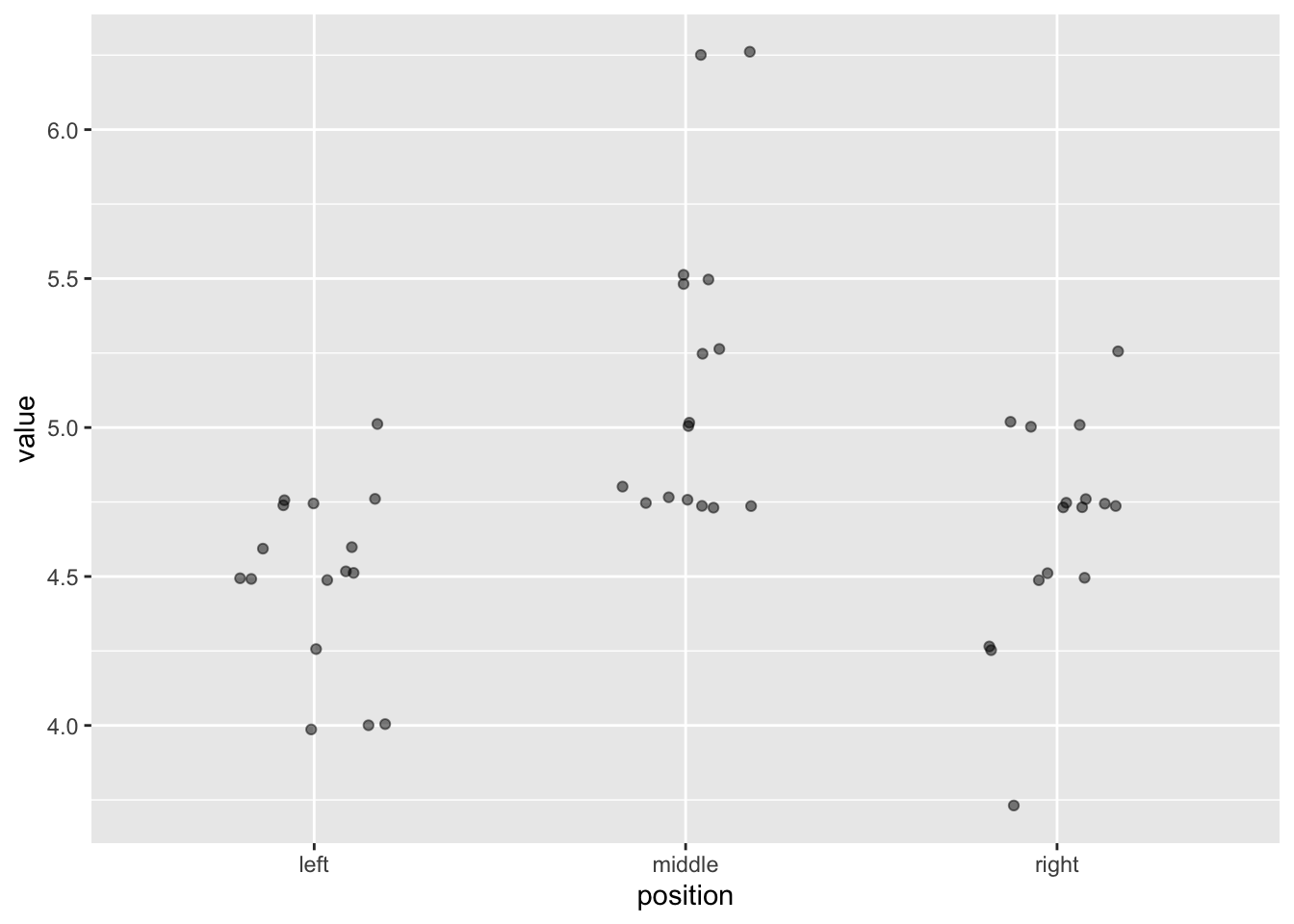
Rows: 16 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Student_initials
dbl (3): left, middle, right
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Remember that statistics focus on variation in the characteristics of a set of multiple specimens. The characteristics of each individual specimen are recorded in a row of a data frame. The data frame itself, with its multiple rows, represents the set of specimens. Each characteristic is arranged as a column in the data frame. We call such columns “variables,” a name that emphasizes that our particular interest is to understand/explain/account-for the variation of the values stored in the column.
In a regression model, we attempt to understand/explain/account-for the variation in a single variable, called the “response variable.” We accomplish this explanation by associating the variation in the response with the simultaneous variation in other variables called “explanatory variables.”
The lm() model-building function does the work of quantifying the associations. Your task in model building is to provide data for training and to specify which are the explanatory variables you want to use to account for the variation in the response variable. The specification takes the form of a tilde expression listing the response and explanatory variables. All these variables must be in the data frame used for training. We say such variables are “observed.”
There are usually other characteristics that are relevant to the system being studied that are not observed, that is, they are not in the data frame. It’s a bad idea to ignore such things.
Starting Lesson 20
Today is a meta-day. It is about tools for learning about statistical methods and gaining insight into why certain kinds of questions/techniques come up over and over again as you work on genuine statistical problems.
The two kinds of tools for learning are:
Tools for thinking and communicating about hypotheses about causal connections.
Diagrams called “DAGs” for sketching out causation.
Generating random, simulated data consistent with the mechanism described by a DAG.
Ways to automate the process of random trials. This is purely a labor-saving measure. You are not responsible to generate the code for this automation, but you should learn to read the code to be able to say what’s going on.
Causation examples
Systolic blood pressure in the elderly:
Experiment shows that lowering SBP reduces mortality.
Observation shows that lower SBP is associated with increased mortality.
Congressional elections
Among incumbents, higher election spending is associated with worse vote outcomes.
Vitamin D and disease
Low vitamin linked to adverse outcomes in many diseases
Ill people go outside less often so are less exposed to sunlight AND Vitamin D is an acute phase reactant and declines with the inflammatory cytokine rise in acute and chronic diseases AND No evidence from randomized trials that vitamin D supplementation lessens mortality risks in such conditions.