Galton |> point_plot(height ~ mother + sex)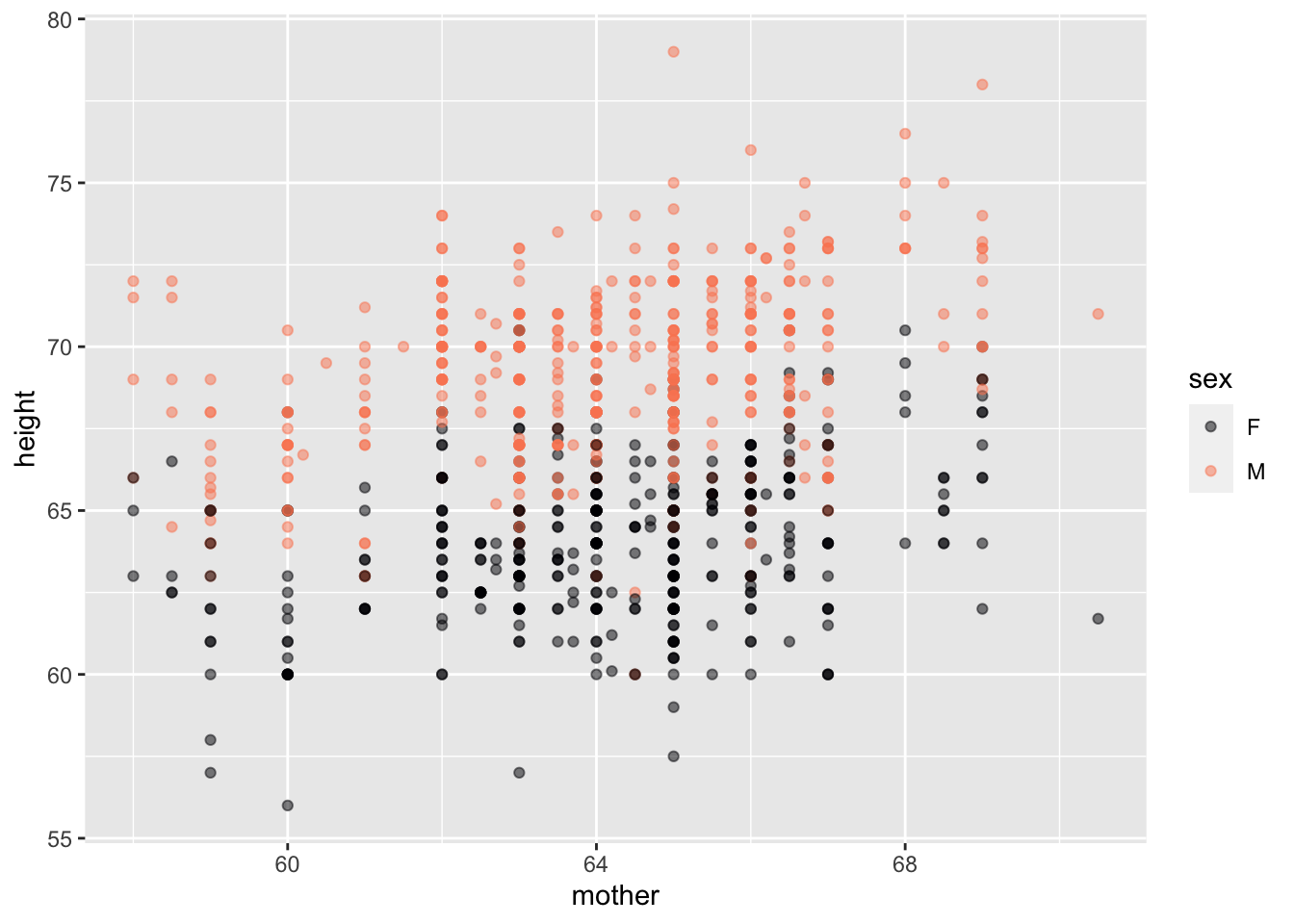
These are presentation notes for the October 2023 StatChat meeting. For more than 15 years, statistical educators in the Twin Cities region of Minnesota have been gathering a half-dozen times a year at StatChat to share comradeship and teaching insights. Among the schools regularly represented are the University of Minnesota, Macalester College, St. Olaf College, Hamline University, Augsburg University, Carleton College, St. Cloud State University, and Minnesota State University Mankato. The slides were slightly revised for a 2024-01-31 presentation “StatsChat” for high-school teachers in Wisconsin.
Abstract: “Mere Renovation is Too Little Too Late: We Need to Rethink Our Undergraduate Curriculum from the Ground Up” is the title 2015 paper by George Cobb. Honoring George’s challenge, I have been rethinking and re-designing the introductory statistics course, replacing traditional foundations using modern materials and reconfiguring the living and working spaces to suit today’s applied statistical needs and projects. In the spirit of a “model house” used to demonstrate housing innovations, I’ll take you on a tour of my “model course,” whose materials are available free, open, and online. Among the features you’ll see: an accessible handling of causal reasoning, a unification of the course structure around modeling, a highly streamlined yet professional-quality computational platform, and an honest presentation of Hypothesis Testing that puts it in the framework of Bayesian reasoning.
What is the most important take-away from your stats course?
What subjects could be dropped without loss?
Are there course topics that are misleading?
Are there course topics that are out of date?
The “consensus” Stat 101 is 50 years out of date:
I’m happy to discuss the above points anytime, but that’s where I aimed this talk.
My objectives:
Demonstrate the extent to which it’s possible to overcome these deficiencies with a complete, practicable, no-prerequisite course.
Provide a complete course framework, avoiding topic bloat, to which other people can add their own exercises, topics, and examples.
To this end, there is now a completed draft textbook: Lessons in Statistical Thinking that is free, online.
Jeff proposes 15 changes*, dividing them into amount-of-effort categories:
Jeff Witmer (2023) “What Should We Do Differently in STAT 101?” Journal of Statistics and Data Science Education link
Almost all of which are engaged in Lessons in Statistical Thinking
Galton |> point_plot(height ~ mother + sex)
Galton |>
model_train(height ~ mother + sex) |>
conf_interval()# A tibble: 3 × 4
term .lwr .coef .upr
<chr> <dbl> <dbl> <dbl>
1 (Intercept) 37.1 41.4 45.8
2 mother 0.286 0.353 0.421
3 sexM 4.87 5.18 5.49 Streamline!
|> verb |> …Data is always in data frames.
Columns: Variables
Rows: “Specimens” / Unit of observation
Computing concepts:
Galton or NatsUsually start with a named data frame, piping it to a function.
Nats |> names()[1] "country" "year" "GDP" "pop" Both the horizontal and vertical axes are mapped to variables.
Just one command: point_plot() produces point plot with automatic jittering as needed.
Tilde expression specifies which variable is mapped to y and x (and, optionally, color and faceting).
Galton |> point_plot(height ~ sex)
Galton |> point_plot(height ~ mother + father + sex)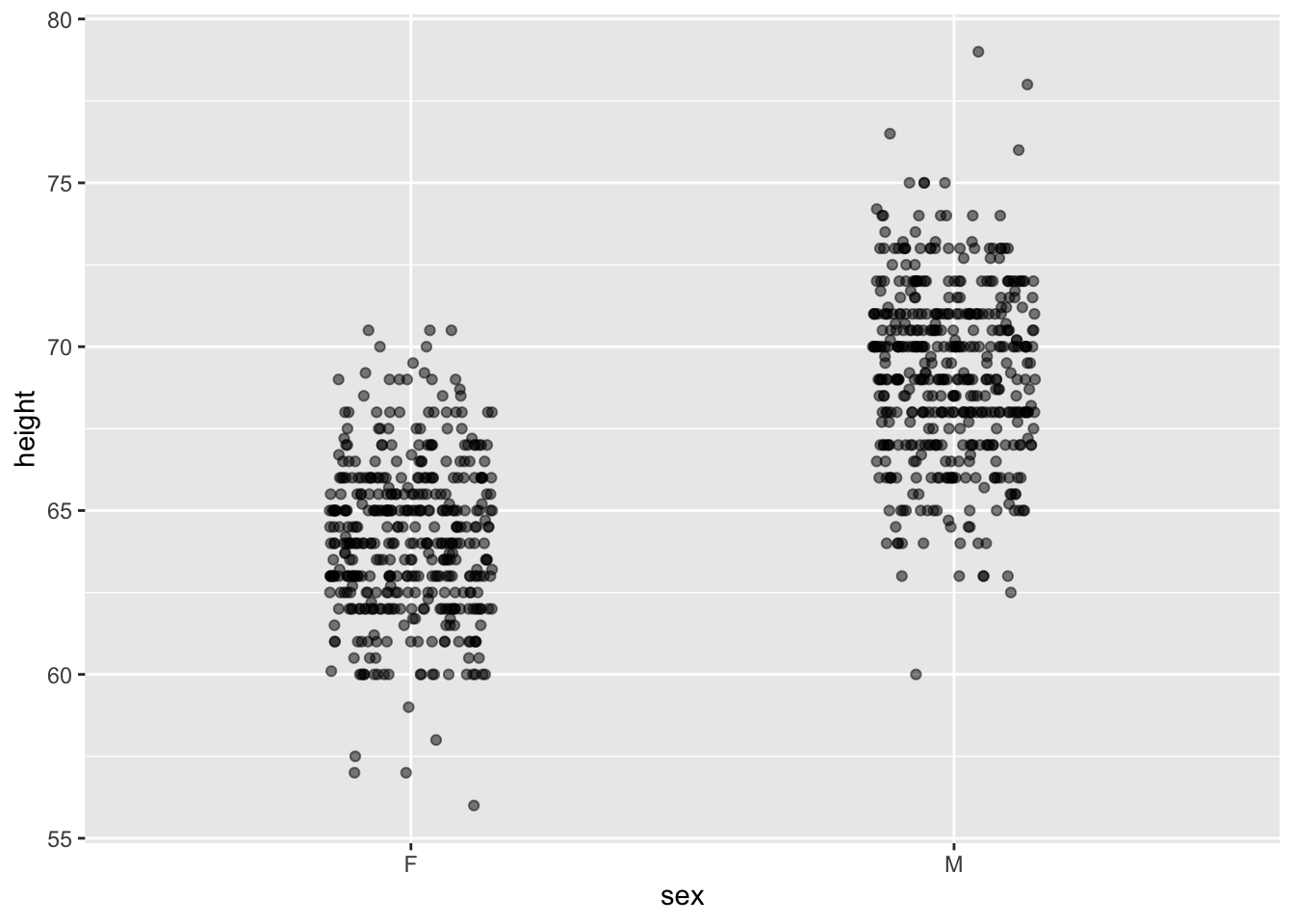
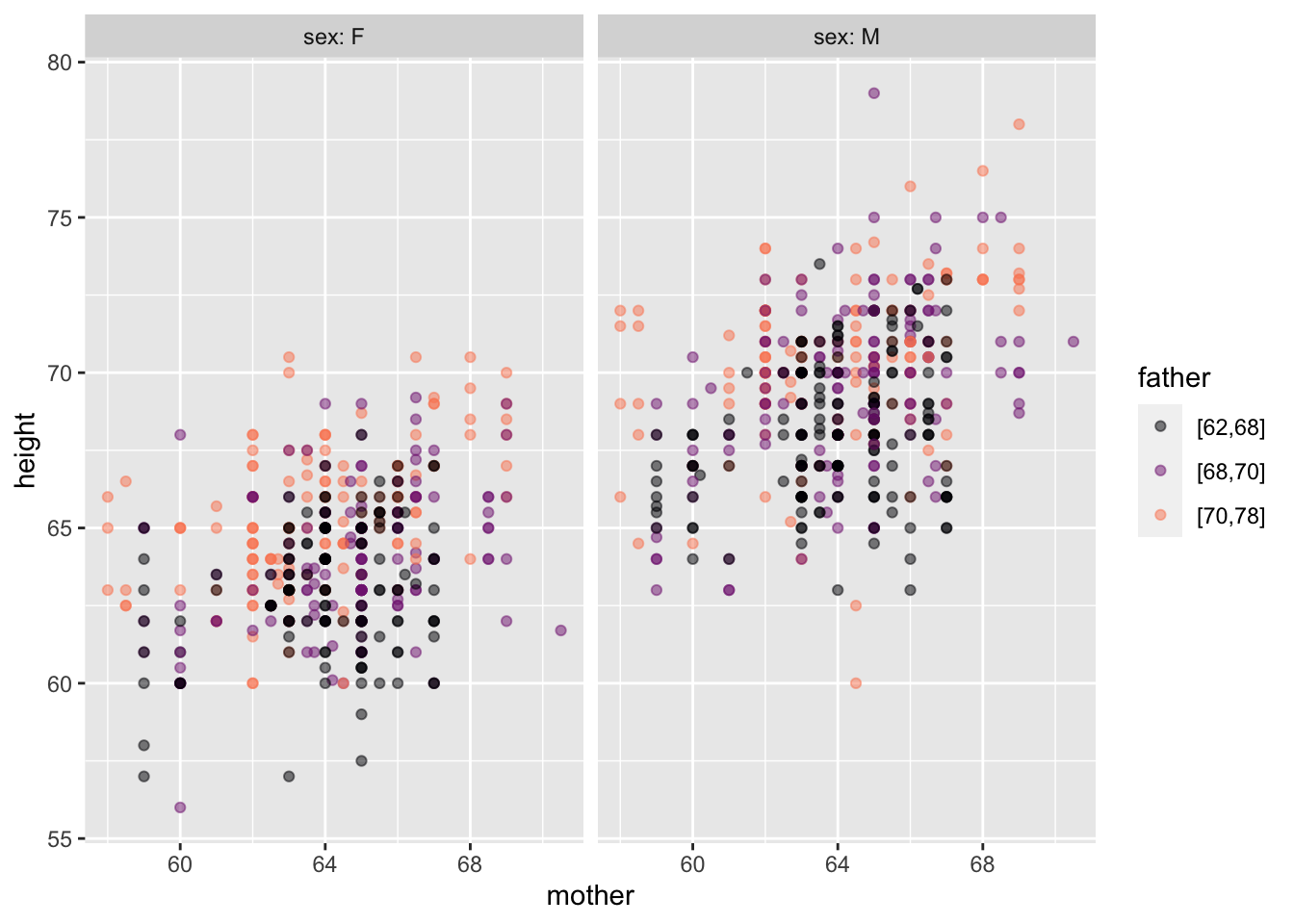
Galton |> point_plot(height ~ sex, annot = "violin")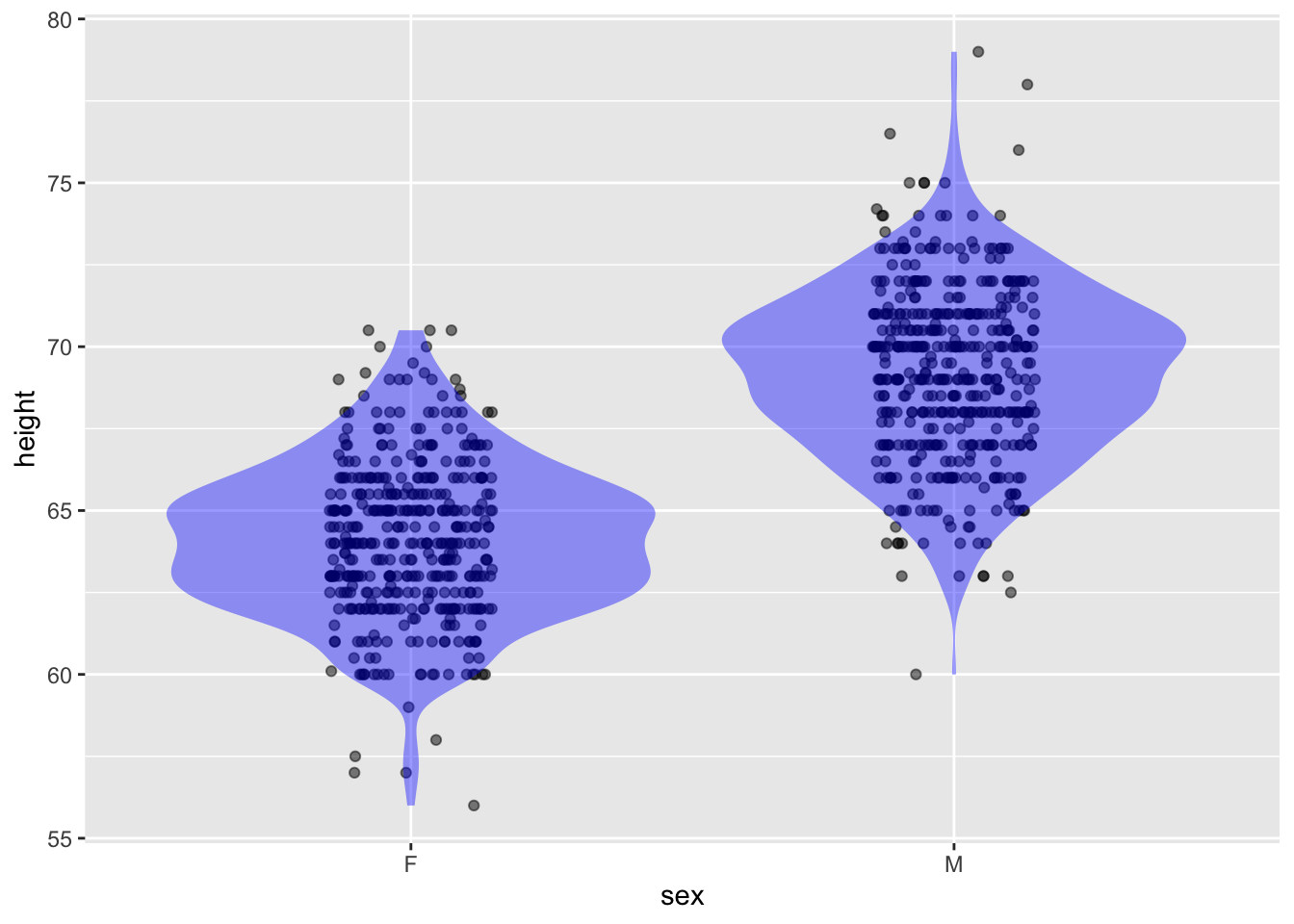
Galton |> sample_n(size=100) |>
point_plot(height ~ sex, annot = "model",
point_ink = 0.1, model_ink=0.75)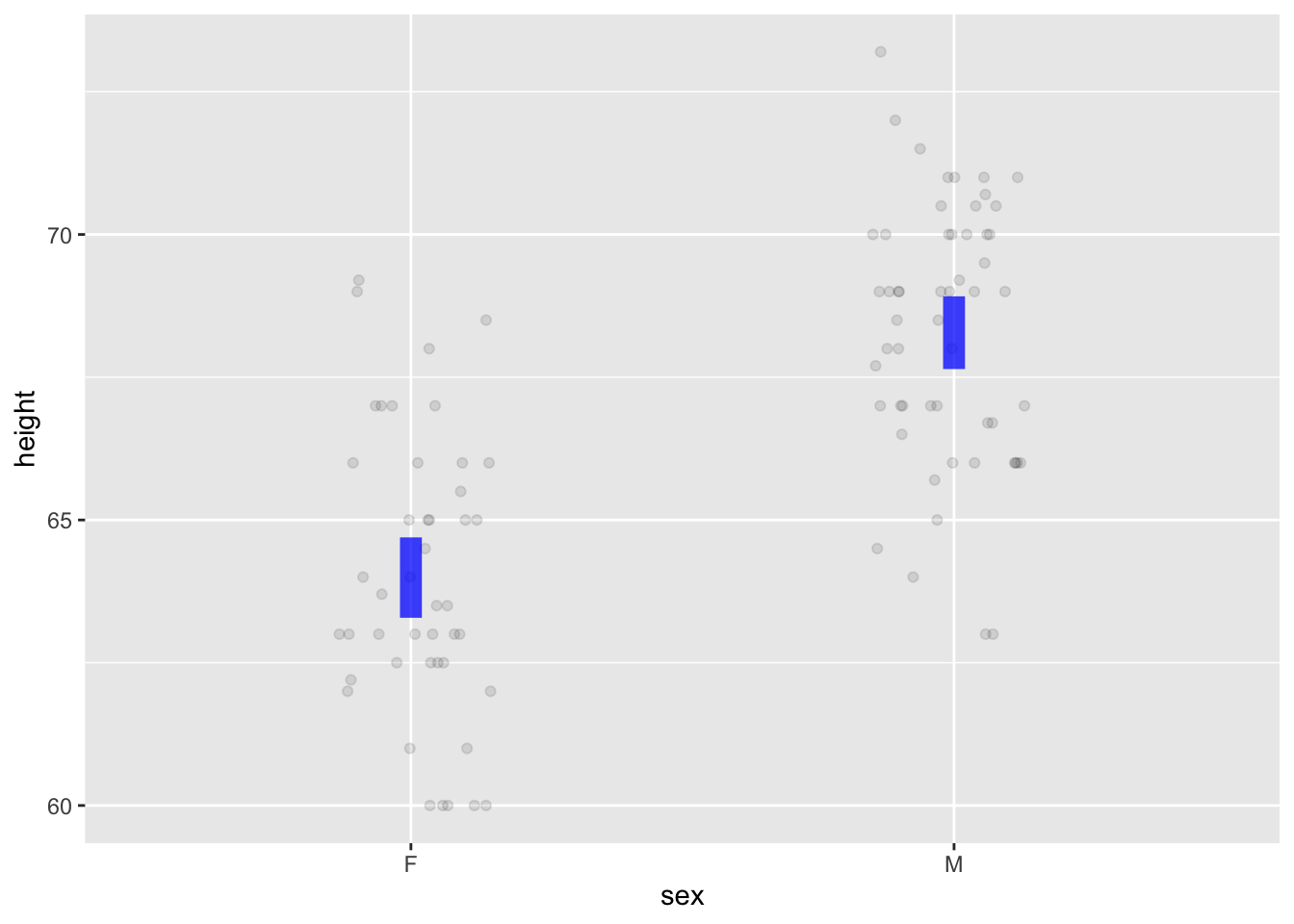
Galton |> point_plot(height ~ mother + father + sex,
annot = "model",
point_ink = 0.1, model_ink=0.75)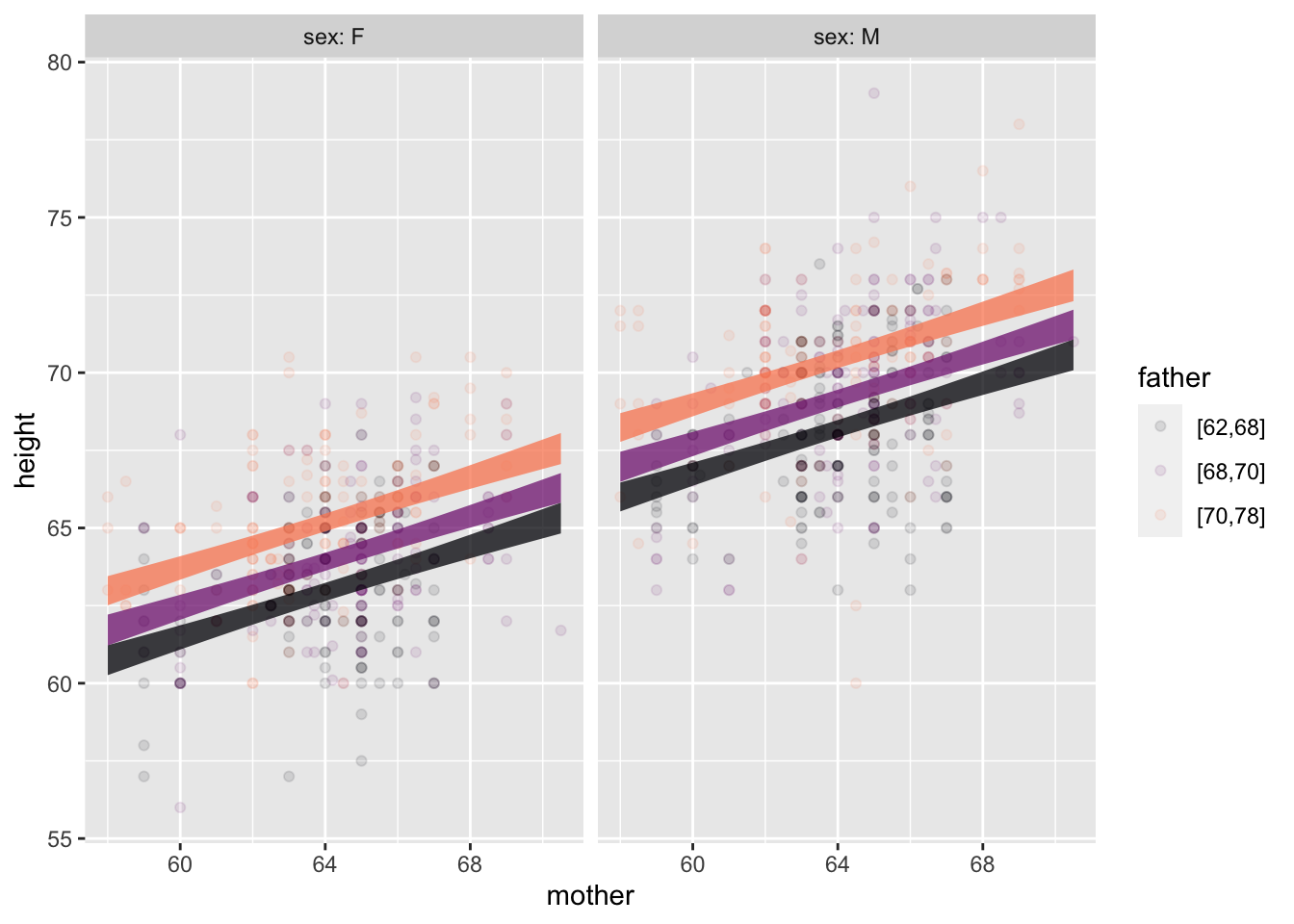
[Perhaps use two class days]
Five basic operations: mutate(), filter(), summarize(), select(), arrange()
Nats# A tibble: 8 × 4
country year GDP pop
<chr> <dbl> <dbl> <dbl>
1 Korea 2020 874 32
2 Cuba 2020 80 7
3 France 2020 1203 55
4 India 2020 1100 1300
5 Korea 1950 100 32
6 Cuba 1950 60 8
7 France 1950 250 40
8 India 1950 300 700Nats |> filter(year == 2020)# A tibble: 4 × 4
country year GDP pop
<chr> <dbl> <dbl> <dbl>
1 Korea 2020 874 32
2 Cuba 2020 80 7
3 France 2020 1203 55
4 India 2020 1100 1300Nats |> summarize(totalpop = sum(pop), .by=year)# A tibble: 2 × 2
year totalpop
<dbl> <dbl>
1 2020 1394
2 1950 780[Perhaps merged into a two-day wrangling unit with Lesson 5]
Pipes, functions, parentheses, arguments, …
[Entirely optional]
Consistently use explanatory/response modeling paradigm. Introduce models with two or three explanatory variables early in the course.
Use variance as measure of variation of a variable. (Ask me about the simple explanation of variance that doesn’t involve calculating a mean.)
Use data wrangling to introduce model values, residuals, …
mtcars |>
mutate(mpg_mod = model_values(mpg ~ hp + wt)) |>
select(hp, wt, mpg_mod) |>
head() hp wt mpg_mod
Mazda RX4 110 2.620 23.57233
Mazda RX4 Wag 110 2.875 22.58348
Datsun 710 93 2.320 25.27582
Hornet 4 Drive 110 3.215 21.26502
Hornet Sportabout 175 3.440 18.32727
Valiant 105 3.460 20.47382Then transition to model coefficients.
mtcars |>
model_train(mpg ~ hp + wt) |>
conf_interval()# A tibble: 3 × 4
term .lwr .coef .upr
<chr> <dbl> <dbl> <dbl>
1 (Intercept) 34.0 37.2 40.5
2 hp -0.0502 -0.0318 -0.0133
3 wt -5.17 -3.88 -2.58 Coefficients are always shown in the context of a confidence interval, even if they don’t yet know the mechanism for generating such intervals.
Demonstrate mechanism of “adjustment”: Evaluate model holding covariates constant.
6-11 class hours, depending on how much spent with named probability distributions. (USAFA engineers want some practice with named distributions: normal, exponential, poisson, …)
Students construct simple simulations, using them to generate data.
mysim <- datasim_make(
x <- rnorm(n),
y <- 2 + 3*x + rnorm(n, sd=0.5)
)
mysim |> sample(size=4)# A tibble: 5 × 2
x y
<dbl> <dbl>
1 0.552 3.97
2 -0.675 -0.0812
3 0.214 3.10
4 0.311 2.82
5 1.17 5.79 Mostly using simulations.
Early introduction of the concept of likelihood: probability of data given hypothesis/model.
The proper form for a prediction: a relative probability assigned to each possible outcome.
The prediction-interval shorthand for (a).
Runs <- mysim |>
sample(n = 5) |>
model_train(y ~ x) |>
trials(10) Warning: The `tidy()` method for objects of class `model_object` is not maintained by the broom team, and is only supported through the `lm` tidier method. Please be cautious in interpreting and reporting broom output.
This warning is displayed once per session.Runs |> select(.trial, term, estimate ) .trial term estimate
1 1 (Intercept) 1.659
2 1 x 3.164
3 2 (Intercept) 2.204
4 2 x 2.950
5 3 (Intercept) 2.055
6 3 x 3.318
7 4 (Intercept) 1.771
8 4 x 3.141
9 5 (Intercept) 2.156
10 5 x 2.920
11 6 (Intercept) 2.157
12 6 x 3.324
13 7 (Intercept) 2.091
14 7 x 2.833
15 8 (Intercept) 2.446
16 8 x 2.794
17 9 (Intercept) 1.892
18 9 x 2.399
19 10 (Intercept) 2.053
20 10 x 2.694Runs |> summarize(var(estimate), .by = term) term var(estimate)
1 (Intercept) 0.05117
2 x 0.08504Demonstrate that variance scales as 1/n.
(2 or 3 day unit)
Definition of risk, risk factors, baseline risk, risk ratios, absolute change in risk.
Use absolute change for decision making, but use risk ratios and odds ratios for calculations.
Regression when response is a zero-one variable.
Whickham |> point_plot(outcome ~ smoker, annot="model",
model_ink = 1)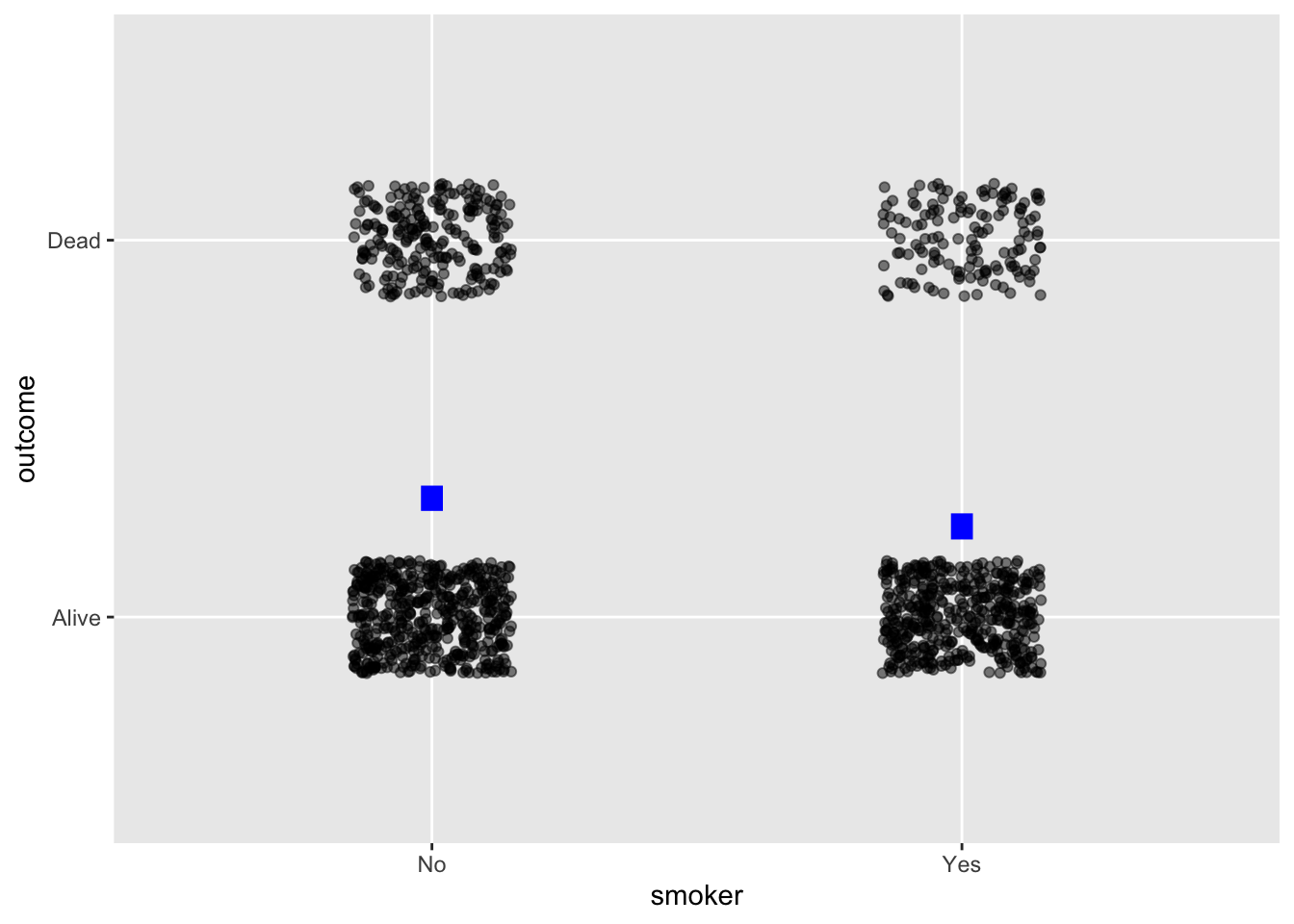
Whickham |> point_plot(outcome ~ age + smoker, annot="model")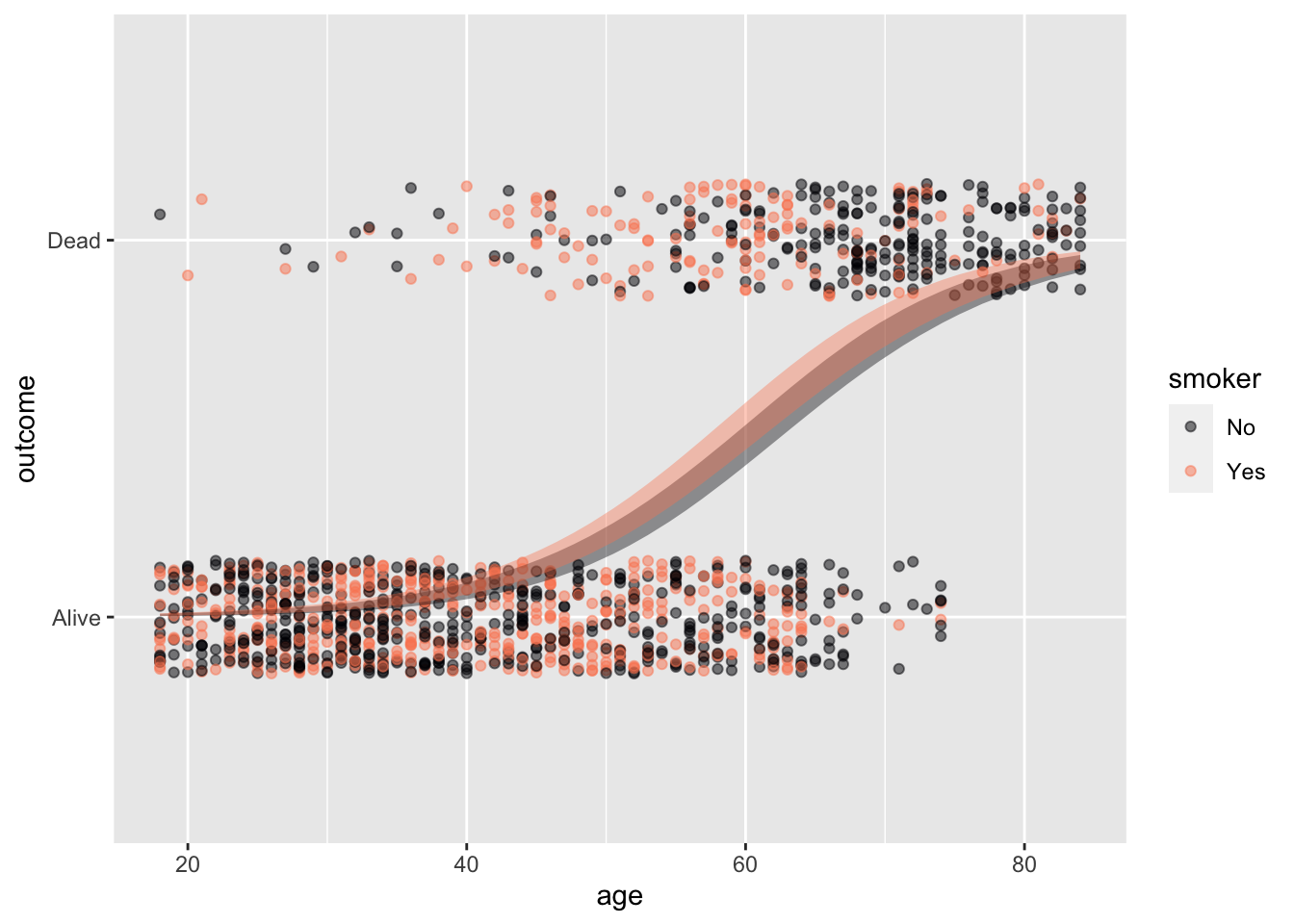
Ratio of (change in output) to (change in input).
Physical units important.
Reading “influence diagrams”
confounding, covariates, and adjustment
Choosing covariates based on a DAG
experiment interpreted as re-wiring of DAGs: requires intervention
What we want: p(hypothesis | data)
What we have: hypothesis |> simulation |> data summarized as a Likelihood.
Question: How do we calculate what we want.
Setting: medical screening. Test result + or -.
We put two hypotheses into competition based on the test result.
Likelihoods we can measure from data:
Setting: prevalence(Sick)
Calculation
\[odds(Sick|+) = \frac{p(+ | Sick)}{p(+ | Healthy)} \ odds(prevalence)\]
Null is “Healthy.”
We have no claim about \(prevalence\).
If we have no claim about \(p(+ | Sick)\), we are more inclined to conclude \(Sick\) if \(p(+ | Healthy)\) is small.
Null is “Healthy.” Alternative is “Sick”.
We have no claim about \(prevalence\), but we have the ability to estimate \(p(+ | Sick)\).
Inclined to conclude \(Sick\) if \(p(+ | Healthy)\) is small (like HNT) and \(p(+ | Sick)\) is small. \(p(+ | Sick)\) is the power of the test.
Operations for all students
Operations used in demonstrations (and suited to some students)
Computations on variables are always inside the arguments of a function taking a data frame as an input.
Tilde expressions for models and graphics.